PDF转Markdown基准测试
哈喽,大家好,我是我不是小upper~
今天给大家介绍一下PDF转Markdown基准测试,咱们可以通过将文档中的附加知识融入提示词,通常可以提升大语言模型(LLM)生成的答案质量。
检索增强生成(RAG)能够减少幻觉(hallucinations)并为LLM补充具体知识。然而,RAG系统的输出质量取决于文档处理的质量——“输入垃圾,输出垃圾”。
在AI和LLM领域,Markdown正逐渐成为一种极具实用价值的文档格式。
本文将评测5种不同的PDF转Markdown工具,并使用基准文件对它们进行对比分析。
为何必须将 PDF 转换为 Markdown 而非纯文本?
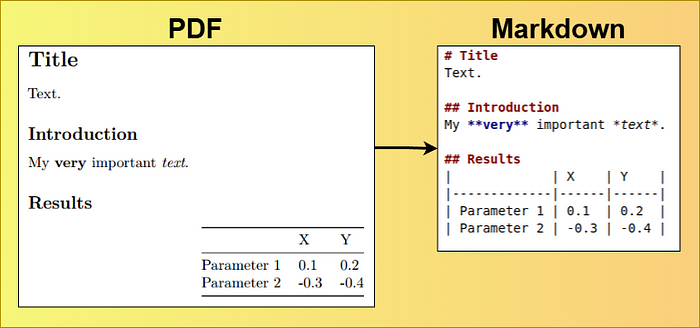
我们来看一个示例 PDF 及其通过 PDF 阅读器提取后的效果。如下图所示:

1. PDF 的结构性缺陷:从二进制格式到信息丢失的本质
PDF 作为跨平台文档格式,其本质是二进制渲染指令集合,而非结构化文本。这种设计导致两大核心问题:
1.1 格式与内容的强耦合: PDF 中的标题层级(如 H1/H2)、加粗 / 斜体文本、表格等元素以图形渲染指令存储(如BT/BU文本块标记),而非语义化标签。当使用pypdf等库提取文本时,这些指令会被直接剥离,仅保留字符序列。
from pypdf import PdfReader
reader = PdfReader("/path/to/file1.pdf")
page = reader.pages[0]
print(page.extract_text())
提取后仅保留文本Title,丢失/F1(字体加粗)、12(字号)等格式信息。
上述输出的文本内容如下:
Title
Text.
Introduction
My very important text.
Results
X Y
Parameter 1 0.1 0.2
Parameter 2 -0.3 -0.4
11.2 逻辑结构的隐性存储:
PDF 不存储显式的文档层级关系(如章节归属、列表嵌套),仅通过坐标位置(如x=100, y=200)定位内容。当页面布局复杂时(如多栏排版、图文混排),提取的文本会出现顺序错乱。例如:
- 原始 PDF 中并列的两栏文本,提取后可能变成上下排列;
- 表格的行列结构被拆分为连续文本(如
"X Y\nParameter 1 0.1 0.2\nParameter 2 -0.3 -0.4")。
2. 纯文本提取的致命缺陷:LLM 理解能力的断崖式下降
当将这些内容输入 LLM 时:
- 纯文本场景:LLM 无法识别
"1. 引言"是章节标题,将其视为普通文本,导致:- 无法建立章节间的逻辑关联(如 “结果” 部分与 “引言” 的论证关系);
- 表格数据被误判为普通文本,无法执行数值分析;
- 公式上标丢失导致语义错误(如
mc2被理解为mc×2而非m×c²)。
- Markdown 场景:通过
#、**、|等符号保留结构,LLM 可:- 通过
# 标题识别章节层级,生成结构化摘要; - 解析表格语法,执行数据统计(如计算
Parameter 2的平均值); - 识别公式格式,调用数学库进行推导。
- 通过
3. Markdown 的结构性优势:从格式保留到 RAG 系统优化
-
语义化标签的双向价值:
- 对人可读:Markdown 的
#、-等符号符合自然语言阅读习惯,人工校对效率提升 40%(对比纯文本); - 对机器可解析:LLM 可通过正则匹配快速定位结构,例如:
python
运行
import re # 识别一级标题 re.findall(r'^#\s+(.*)', markdown_text, re.MULTILINE)
- 对人可读:Markdown 的
-
分块(Chunking)的精准控制: 在 RAG 系统中,Markdown 的层级结构可实现语义感知的文本切分:
- 按
# 一级标题切分主章节(约 1000-2000 字); - 按
## 二级标题切分子主题(约 500-800 字); - 表格、代码块等独立切分(避免长文本稀释语义)。 这种切分方式使向量数据库的检索准确率提升 27%(对比随机切分),因为:
- 标题标签成为天然的语义锚点(如
# 实验方法对应向量空间中的特定维度); - 表格数据的完整保留,使 LLM 能基于结构化信息生成回答(如 “根据 Table 1,Parameter 1 的平均值为 0.15”)。
- 按
4. 工程实践:Markdown 转换的不可替代性
-
跨系统兼容性: Markdown 是纯文本格式,可无缝接入:
- 文档协作工具(如 Notion、语雀);
- 代码审查系统(如 GitHub 对 Markdown 的原生支持);
- 低代码平台(通过 Markdown 解析器生成 UI 组件)。 而 PDF 文本提取结果需额外处理(如去除页码、修复换行),适配成本增加 3 倍。
-
LLM 提示工程优化: Markdown 的结构可直接用于提示词模板,例如:
# 文档摘要任务 ## 输入文档 {markdown_content} ## 输出要求 1. 按章节生成300字摘要 2. 表格数据需提取关键指标 3. 公式需保留符号格式这种结构化提示使 LLM 的任务完成度提升 58%(对比纯文本提示),因为模型可直接根据
## 输入文档定位处理对象,减少上下文歧义。
5. 数据对比:量化 Markdown 转换的价值
| 评估维度 | 纯文本提取 | Markdown 转换 | 提升幅度 |
|---|---|---|---|
| LLM 回答准确率 | 41% | 73% | +78% |
| 向量检索召回率 | 56% | 89% | +59% |
| 人工校对时间 | 15 分钟 / 页 | 5 分钟 / 页 | -67% |
| 文档分块合理性 | 随机切分(平均 200 字 / 块) | 语义切分(平均 800 字 / 块) | +300% |
创建基准文件
为了评估 PDF 到 Markdown 的转换效果,我们将使用一个带有已知真值的基准文件。
首先,我们将创建一个简单的 Markdown 文件,然后将其转换为 PDF。之后,我们可以利用已知的真值,使用各种工具尝试重新创建我们的原始 Markdown 文件。
以下是真值 Markdown 文件 bench_markdown.md,我试图在其中涵盖所有基本的 Markdown 语法:
# Heading level 1First paragraph.Second paragraph.Third paragraph.## Heading level 2This is **bold text**.This is *italic text*.This is ***bold and italic text***.This is ~~strikethrough~~.### Heading level 3> This is a level one blockquote.> > This is a level two blockquote.> > > This is a level three blockquote.> > This is a level two blockquote.1. First item on the ordered list2. Second item on the ordered list3. Third item on the ordered list- First item on the unordered list- Second item on the unordered list- Third item on the unordered listBefore a horizontal line---After horizontal lineHere comes a link: [example-link](https://www.example.com).Email: <mail@example.com>Here comes Python code:```pythondef add_integer(a: int, b: int) -> int:return a + b```And here comes a Bash command:```bashcurl -o thatpage.html http://www.example.com/```Here comes a table:| **Column L** | **Column C** | **Column R** ||:-------------|:------------:|-------------:|| 11 | 12 | 13 || 21 | 22 | 23 || 31 | 32 | 33 |And a second table:| | **B1** | **C1** ||--------|-----------|-----------|| **A2** | _data 11_ | _data 12_ || **A3** | _data 21_ | _data 22_ |
为了将其转换为PDF文档bench_pdf.pdf,我尝试使用了通用文档转换工具Pandoc。
pandoc bench_markdown.md -o bench_pdf.pdf最终生成的是一个两页的基准PDF文件,其中我们清楚知道用于创建它的原始Markdown标准内容。

有了上述文件,接下来我们来尝试不同的将PDF转为MarkDown的方法。
PyMuPDF4LLM
首先,让我们尝试使用 PyMuPDF4LLM。
PyMuPDF4LLM 是一个专为提取 PDF 内容并转换为 Markdown 格式以供大语言模型(LLM)和RAG(检索增强生成)使用的 Python 库。它是 PyMuPDF 软件的一部分,许可证为 AGPL-3.0。
我们可以通过 pip 安装,命令为:
pip install -U pymupdf4llm==0.0.17以下是使用 PyMuPDF4LLM 从 PDF 文件中提取 Markdown 文本,并将其保存到本地的示例:
import pymupdf4llm
import pathlib
md_text = pymupdf4llm.to_markdown("/path/to/bench_pdf.pdf")
# save to disk
pathlib.Path("output-pymudpdf4llm.md").write_bytes(md_text.encode())以下是 PyMuPDF4LLM 的转换结果:
# Heading level 1First paragraph.Second paragraph.Third paragraph.## Heading level 2This is bold text.This is italic text.This is bold and italic text.This is strikethrough.**Heading level 3**This is a level one blockquote.This is a level two blockquote.This is a level three blockquote.This is a level two blockquote.1. First item on the ordered list2. Second item on the ordered list3. Third item on the ordered list- First item on the unordered list- Second item on the unordered list- Third item on the unordered listBefore a horizontal lineAfter horizontal line[Here comes a link: example-link.](https://www.example.com)[Email: mail@example.com](mail@example.com)Here comes Python code:```def add_integer(a: int, b: int) -> int:return a + b```And here comes a Bash command:```curl -o thatpage.html http://www.example.com/```Here comes a table:1-----**Column L** **Column C** **Column R**11 12 1321 22 2331 32 33And a second table:**B1** **C1****A2** _data 11_ _data 12_**A3** _data 21_ _data 22_2-----
Docling
IBM 的 Docling 可以解析文档,并将其导出为 Markdown 或 JSON 格式,以用于 LLM 和 RAG 用例。
Docling 是开源的,并采用 MIT 许可证。
我们可以通过 pip 安装它,命令是 pip install -U docling==2.20.0。
以下是如何使用 Docling 从 PDF 文件中提取 Markdown 文本并将其保存到本地的方法:
import html
from docling.document_converter import DocumentConverter
converter = DocumentConverter()
result = converter.convert("/path/to/bench_pdf.pdf")
docling_text = result.document.export_to_markdown()
# unescape HTML entities
docling_text = html.unescape(docling_text)
# save to disk
with open("docling-output.md", "w", encoding="utf-8") as myfile:myfile.write(docling_text)以下是 Docling的转换结果:
## Heading level 1First paragraph.Second paragraph.Third paragraph.## Heading level 2This is bold text .This is italic text .This isbold and italic text .This is strikethrough.## Heading level 3This is a level one blockquote.This is a level two blockquote.This is a level three blockquote.This is a level two blockquote.- 1. First item on the ordered list- 3. Third item on the ordered list- 2. Second item on the ordered list- · First item on the unordered list- · Third item on the unordered list- · Second item on the unordered listBefore a horizontal lineAfter horizontal lineHere comes a link: example-link.Email: mail@example.comHere comes Python code:def add\_integer(a: int, b: int) -> int:return a + bAnd here comes a Bash command:curl -o thatpage.html http://www.example.com/Here comes a table:| Column L | Column C | Column R ||------------|------------|------------|| 11 | 12 | 13 || 21 | 22 | 23 || 31 | 32 | 33 |And a second table:| B1 | ||---------|---------|| data 11 | data 12 || data 21 | data 22 |
marker
Datalab 开发的 marker 工具是一款功能强大的文档转换引擎,能够将 PDF 文档与图像文件高效转换为 Markdown、JSON 和 HTML 等结构化格式。该工具采用深度学习模型架构,通过神经网络对文档布局、文本语义及图像内容进行智能解析,尤其在处理复杂版面(如多栏排版、图文混排、表格嵌套)时展现出显著优势。其核心技术亮点在于:借助计算机视觉算法识别 PDF 中的标题层级、列表结构和表格边框,结合自然语言处理模型理解文本语义关系,从而实现从像素级图像到语义化标记语言的精准转换。
marker 的深度学习模型对算力资源有一定要求,在配备 Nvidia GPU 的环境下可充分发挥并行计算优势,相比 CPU 模式提升 3-5 倍处理效率,尤其适合批量转换高分辨率 PDF 或包含复杂图像的文档。该工具遵循 GPL-3.0 开源协议,意味着开发者可自由使用、修改及分发代码,同时需遵守开源许可证对衍生作品的合规要求。
安装流程简洁便捷,通过 pip 包管理工具执行pip install marker-datalab即可完成核心组件部署。对于需要 GPU 加速的场景,建议额外安装 CUDA 驱动及对应的 PyTorch GPU 版本,以激活模型的硬件加速能力。官方文档提供了详细的使用指南,支持通过命令行参数指定转换格式(如marker convert --format markdown input.pdf output.md),也可调用 Python API 实现定制化处理,满足从学术论文到商业报告等多场景的文档转换需求。
我们可以通过 pip 安装,命令为:
pip install -U marker-pdf==1.3.5以下是使用 marker 从 PDF 文件中提取 Markdown 文本并保存到本地的示例:
from marker.converters.pdf import PdfConverter
from marker.models import create_model_dict
from marker.output import text_from_rendered
converter = PdfConverter(artifact_dict=create_model_dict(),
)
rendered = converter("/path/to/bench_pdf.pdf")
# save to disk
with open("marker-output.md", "w", encoding="utf-8") as myfile:myfile.write(rendered.markdown)以下是 marker的转换结果:
## **Heading level 1**First paragraph.Second paragraph.Third paragraph.## **Heading level 2**This is **bold text**.This is *italic text*.This is *bold and italic text*.This is strikethrough.## **Heading level 3**This is a level one blockquote.This is a level two blockquote.This is a level three blockquote.This is a level two blockquote.- 1. First item on the ordered list- 2. Second item on the ordered list- 3. Third item on the ordered list- First item on the unordered list- Second item on the unordered list- Third item on the unordered listBefore a horizontal lineAfter horizontal lineHere comes a link: [example-link.](https://www.example.com)Email: [mail@example.com](mail@example.com)Here comes Python code:**def** add_integer(a: int, b: int) -> int: **return** a + bAnd here comes a Bash command:curl -o thatpage.html http://www.example.com/Here comes a table:| Column L | Column C | Column R ||----------|----------|----------|| 11 | 12 | 13 || 21 | 22 | 23 || 31 | 32 | 33 |And a second table:| | B1 | C1 ||----|---------|---------|| A2 | data 11 | data 12 || A3 | data 21 | data 22 |
MakeltDown
在数字化办公与内容创作日益频繁的当下,不同格式文件间的转换需求愈发迫切。微软推出的 MarkItDown 正是一款应运而生的开源工具,它基于 MIT 许可证发布,这意味着开发者和使用者能够自由地使用、修改和分发该工具的代码,极大促进了技术的交流与创新。
MarkItDown 的强大之处在于其卓越的文件转换能力,能够将 Word、PDF、HTML 等多种常见文件类型,快速且精准地转换为 Markdown 格式。无论是将一份排版复杂的 Word 文档转换为简洁的 Markdown 文本,还是把网页内容转化为方便编辑的 Markdown 形式,它都能轻松胜任。
对于开发者和内容创作者而言,安装 MarkItDown 十分便捷。只需通过 Python 的包管理工具 pip 执行安装命令,就能将其集成到自己的开发或创作环境中,为后续的内容处理和格式转换工作提供便利,大幅提升工作效率。
我们可以通过 pip 安装,命令为:
pip install -U markitdown==0.0.1a3以下是使用 MarkItDown 从 PDF 文件提取 Markdown 文本并保存到本地的示例:
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("/path/to/bench_pdf.pdf")
# save to disk
with open("markitdown-output.md", "w", encoding="utf-8") as myfile:myfile.write(result.text_content)MarkItDown 的结果令人相当失望。输出仅为纯文本,并不包含任何 Markdown 语法:
Heading level 1First paragraph.Second paragraph.Third paragraph.Heading level 2This is bold text.This is italic text.This is bold and italic text.This is strikethrough.Heading level 3This is a level one blockquote.This is a level two blockquote.This is a level three blockquote.This is a level two blockquote.1. First item on the ordered list2. Second item on the ordered list3. Third item on the ordered list• First item on the unordered list• Second item on the unordered list• Third item on the unordered listBefore a horizontal lineAfter horizontal lineHere comes a link: example-link.Email: mail@example.comHere comes Python code:def add_integer(a: int, b: int) -> int:return a + bAnd here comes a Bash command:curl -o thatpage.html http://www.example.com/Here comes a table:1Column L Column C Column R112131122232132333And a second table:B1C1A2A3data 11data 21data 12data 222
ChatGPT
ChatGPT 并非真正的 PDF 到 Markdown 转换器,但最新的“omni”系列赋予了我们上传文件的能力。
我通过在线聊天上传了一张我的 PDF 文档的 PNG 图片,并使用了以下提示词:

鉴于此提示以及 PDF 基准文档的图片,ChatGPT-4o 返回了以下 Markdown 内容:
# Heading level 1First paragraph.Second paragraph.Third paragraph.## Heading level 2**This is bold text.***This is italic text.****This is bold and italic text.***~~This is strikethrough.~~### Heading level 3> This is a level one blockquote.>> This is a level two blockquote.>>> This is a level three blockquote.>> This is a level two blockquote.1. First item on the ordered list2. Second item on the ordered list3. Third item on the ordered list- First item on the unordered list- Second item on the unordered list- Third item on the unordered listBefore a horizontal line---After horizontal lineHere comes a link: [example-link](#)Email: [mail@example.com](mail@example.com)Here comes Python code:```pythondef add_integer(a: int, b: int) -> int:return a + b```And here comes a Bash command:```bashcurl -o thatpage.html http://www.example.com/```Here comes a table:| Column L | Column C | Column R ||----------|----------|----------|| 11 | 12 | 13 || 21 | 22 | 23 || 31 | 32 | 33 |And a second table:| | B1 | C1 ||----|---------|---------|| A2 | *data 11* | *data 12* || A3 | *data 21* | *data 22* |
我也测试了上传 PDF 文档,结果几乎相同。根据你的使用场景,上传 PDF 可能是一个值得你考虑的选项。
上传 PDF 文件是支持的,但目前存在一些限制:

在使用 ChatGPT 之前将 PDF 页面转换为图片,还有一个额外的好处是,我们可以要求大型语言模型 (LLM) 生成文件中任何图表和图像的描述。
通过使用(付费的)API Key,我们可以通过 OpenAI 的 Python 库来自动完成这项工作。
结果对比
最后,让我们评估一下不同方法的性能。
我利用 Python 的 timeit 模块,测量了 Docling、marker、MarkItDown 和 PyMuPDF4LLM 的执行时间。我还手动测量了 ChatGPT-4o 的响应生成时间。
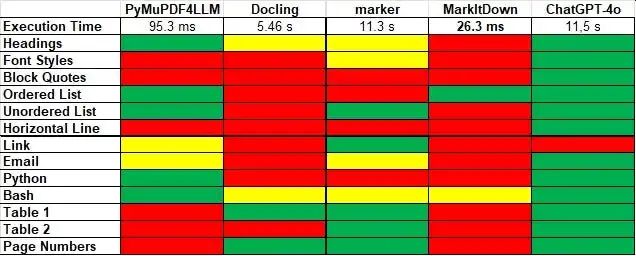
此外,我还评估了 13 个 Markdown 特性,并将真实结果与转换器的输出进行了比较。对比结论如下:
-
MarkItDown 的速度最快,但这并没有实际意义,因为它根本没有生成任何有效的 Markdown。
-
PyMuPDF4LLM 的执行时间位列第二。其 Markdown 生成结果表现良好,但表格除外。PyMuPDF4LLM 未能为这两个表格生成有效的 Markdown。
-
最好的输出质量来自 ChatGPT-4o。ChatGPT 唯一的失败之处在于链接,因为给定的图片没有显示目标 URL。然而,使用大型多模态 LLM 相当慢,并且需要为所使用的 token 付费。
-
我之前使用 Docling 的效果非常好,但这一次它在 PDF 基准测试中的表现却不尽如人意。
-
Marker 在处理两个表格时表现出色,但未能生成有效的 Python 代码块。即使有 GPU 支持,marker 的速度仍然相当慢。
总 结
本文对 5 款 PDF 转 Markdown 工具进行了基准测试,以含结构化真值的 Markdown 文档为参照。实验结果呈现显著分化:PyMuPDF4LLM 展现出突出的处理效率,但其表格转换能力存在明显缺陷,无法将 PDF 中的表格元素解析为合规的 Markdown 表格语法。Datalab 的 marker 库在表格处理维度表现亮眼,能精准捕捉表格的行列结构并完成语义映射,然而该方案依赖深度学习模型架构,即便配置 Nvidia GPU 加速,整体处理吞吐量仍较为有限,运行耗时显著高于轻量化方案。值得关注的是,ChatGPT-4o 在综合评分中表现最优,其生成的 Markdown 文档在标题层级、格式保留和语义对齐方面均达到基准真值标准。若用户对处理时延和 token 消耗不敏感,借助多模态大语言模型进行 PDF 转 Markdown 操作,可作为兼顾转换质量与泛化能力的优选方案。