Python训练营---Day39
- 图像数据的格式:灰度和彩色数据
- 模型的定义
- 显存占用的4种地方
- 模型参数+梯度参数
- 优化器参数
- 数据批量所占显存
- 神经元输出中间状态
- batchisize和训练的关系
作业:今日代码较少,理解内容即可
1、图像数据的格式:灰度和彩色数据

# 打印一张彩色图像,用cifar-10数据集
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np# 设置随机种子确保结果可复现
torch.manual_seed(42)
# 定义数据预处理步骤
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 加载CIFAR-10训练集
trainset = torchvision.datasets.CIFAR10(root='./cifar_data',train=True,download=True,transform=transform
)# 创建数据加载器
trainloader = torch.utils.data.DataLoader(trainset,batch_size=4,shuffle=True
)# CIFAR-10的10个类别
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 随机选择一张图片
sample_idx = torch.randint(0, len(trainset), size=(1,)).item()
image, label = trainset[sample_idx]# 打印图片形状
print(f"图像形状: {image.shape}") # 输出: torch.Size([3, 32, 32])
print(f"图像类别: {classes[label]}")# 定义图像显示函数(适用于CIFAR-10彩色图像)
def imshow(img):img = img / 2 + 0.5 # 反标准化处理,将图像范围从[-1,1]转回[0,1]npimg = img.numpy()plt.imshow(np.transpose(npimg, (1, 2, 0))) # 调整维度顺序:(通道,高,宽) → (高,宽,通道)plt.axis('off') # 关闭坐标轴显示plt.show()# 显示图像
imshow(image)2、模型的定义
2.1黑白图像模型定义
# 定义两层MLP神经网络
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元self.relu = nn.ReLU() # 激活函数self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 展平图像x = self.layer1(x) # 第一层线性变换x = self.relu(x) # 应用ReLU激活函数x = self.layer2(x) # 第二层线性变换,输出logitsreturn x# 初始化模型
model = MLP()device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device) # 将模型移至GPU(如果可用)from torchsummary import summary # 导入torchsummary库
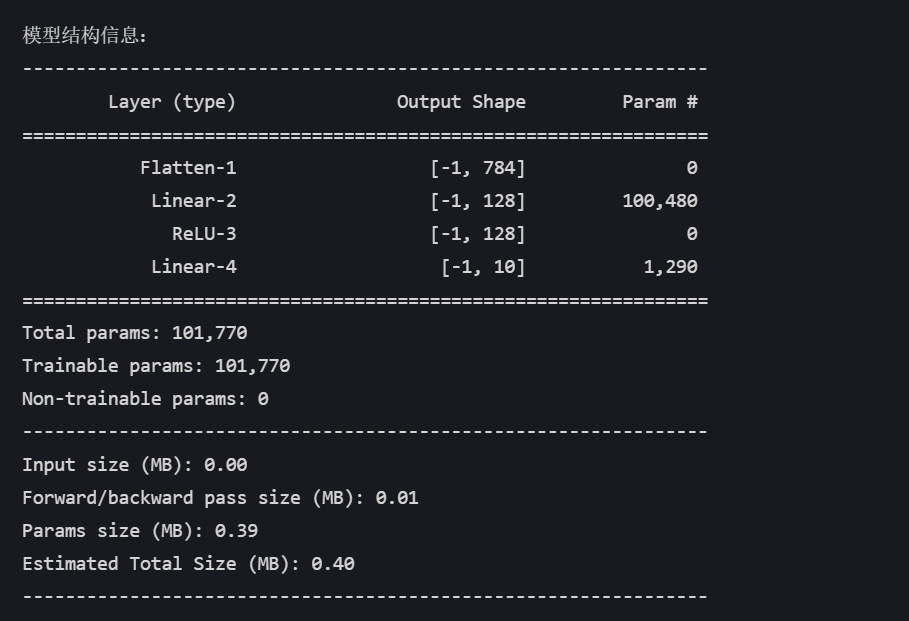
print("\n模型结构信息:")
summary(model, input_size=(1, 28, 28)) # 输入尺寸为MNIST图像尺寸MLP 的输入层要求输入是一维向量,但 MNIST 图像是二维结构(28×28 像素),形状为 [1, 28, 28](通道 × 高 × 宽)。nn.Flatten()展平操作 将二维图像 “拉成” 一维向量(784=28×28 个元素),使其符合全连接层的输入格式。
其中不定义这个flatten方法,直接在前向传播的过程中用 x = x.view(-1, 28 * 28) 将图像展平为一维向量也可以实现
2.2彩色图像模型定义
class MLP(nn.Module):def __init__(self, input_size=3072, hidden_size=128, num_classes=10):super(MLP, self).__init__()# 展平层:将3×32×32的彩色图像转为一维向量# 输入尺寸计算:3通道 × 32高 × 32宽 = 3072self.flatten = nn.Flatten()# 全连接层self.fc1 = nn.Linear(input_size, hidden_size) # 第一层self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_size, num_classes) # 输出层def forward(self, x):x = self.flatten(x) # 展平:[batch, 3, 32, 32] → [batch, 3072]x = self.fc1(x) # 线性变换:[batch, 3072] → [batch, 128]x = self.relu(x) # 激活函数x = self.fc2(x) # 输出层:[batch, 128] → [batch, 10]return x# 初始化模型
model = MLP()device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device) # 将模型移至GPU(如果可用)from torchsummary import summary # 导入torchsummary库
print("\n模型结构信息:")
summary(model, input_size=(3, 32, 32)) # CIFAR-10 彩色图像(3×32×32)实际定义中,输入图像还存在batchsize这一维度。
在 PyTorch 中,模型定义和输入尺寸的指定不依赖于 batch_size,无论设置多大的 batch_size,模型结构和输入尺寸的写法都是不变的。
PyTorch 模型会自动处理 batch 维度(即第一维),无论 batch_size 是多少,模型的计算逻辑都不变。batch_size 是在数据加载阶段定义的,与模型结构无关。
summary(model, input_size=(1, 28, 28))中的input_size不包含 batch 维度,只需指定样本的形状(通道 × 高 × 宽)。
3、显存占用的4种地方

手写数据集(MNIST)和当前 MLP 模型,显存占用的计算可以简化为以下几个部分。
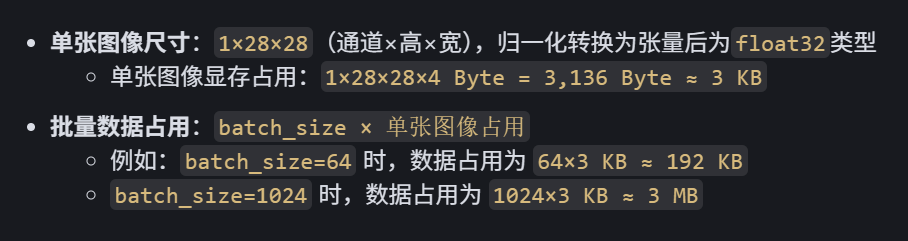
PyTorch的transforms.ToTensor()会将其归一化到[0, 1]范围,并转换为 float32类型(浮点型更适合神经网络计算)。
3.1模型参数+梯度参数
- 单精度参数:101770*4B≈ 403 KB
- 梯度参数(反向传播):与参数相同,403KB
3.2优化器参数

3.3数据批量所占显存
3.4神经元输出中间状态

4、batchisize和训练的关系
在 PyTorch 中,在使用DataLoader加载数据时,如果不指定batch_size参数,默认值是1
,即每次迭代返回一个样本。这与一次性使用全部数据进行训练是完全不同的概念。如果想要一次性使用全部数据进行训练,需要手动将batch_size设置为数据集的大小,但对于大型数据集,这样做通常会导致内存不足,因为一次性将所有数据加载到内存中可能会超出硬件的内存限制。
大规模数据时,通常从16开始测试,然后逐渐增加,确保代码运行正常且不报错,直到出现 内存不足(OOM)报错 或训练效果下降,此时选择略小于该值的 batch_size。
训练时候搭配 nvidia-smi 监控显存占用,合适的 batch_size = 硬件显存允许的最大值 × 0.8(预留安全空间),并通过训练效果验证调整。
