机器学习数据降维方法
1.数据类型
2.如何选择降维方法进行数据降维
3.线性降维:主成分分析(PCA)、线性判别分析(LDA)
4.非线性降维
5.基于特征选择的降维
6.基于神经网络的降维
数据降维是将高维数据转换为低维表示的过程,旨在保留关键信息的同时减少计算复杂度、去除噪声或可视化数据。常见降维方法有几类,分别对应不同数据采用。
| 方法类型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| PCA | 计算快、可解释、保留全局结构 | 仅捕获线性关系 | 特征相关性高、线性数据 |
| t-SNE | 可视化效果好、保留局部结构 | 计算慢、难以解释、超参敏感 | 高维数据可视化(如单细胞RNA-seq) |
| UMAP | 比t-SNE快、保留局部和部分全局结构 | 需调参 | 大规模非线性数据 |
| LDA | 最大化类别可分性 | 仅适用于分类、需标签 | 有监督分类任务 |
| 自编码器 | 处理复杂非线性关系 | 需要大量数据、训练成本高 | 图像、语音等高维非线性数据 |
| 特征选择 | 保留原始特征、可解释性强 | 可能丢失特征间交互信息 | 特征冗余明显的结构化数据 |
一、数据类型
虽然降维方法最初多用于数值型数据,但通过适当的预处理和转换,非数值型数据(如类别型、文本、图像、图网络等) 也可以使用降维技术。降维的核心是保留数据的本质结构,无论原始形式如何,文本是通过词频或语义嵌入捕捉语义相似性。图数据是通过节点关系捕捉社区结构。类别数据是通过共现频率或概率模型发现潜在模式。
1. 类别型数据(Categorical Data)
(1)独热编码(One-Hot Encoding)后降维:将类别变量转为二进制向量(如性别“男/女”变为[1,0]和[0,1]),再使用PCA或t-SNE降维。独热编码会大幅增加维度(“维度爆炸”),需配合降维。
2. 文本数据(Text Data)
(1)词袋模型(Bag-of-Words) + 降维:将文本转为词频向量(TF-IDF)后,用PCA/NMF/LDA(潜在狄利克雷分配)降维。如新闻分类中,用NMF提取主题(每个主题是词的加权组合)。
(2)词嵌入(Word Embedding):直接使用预训练的低维词向量(如Word2Vec、GloVe)表示文本,或对句子/文档向量化后降维。
3. 图数据(Graph/Network Data)
(1)图嵌入(Graph Embedding):将节点映射为低维向量(如Node2Vec、DeepWalk),保留图的结构信息。
(2)邻接矩阵降维:对图的邻接矩阵或拉普拉斯矩阵进行PCA或SVD分解。
4. 图像数据(Image Data)
(1)传统方法:对像素矩阵使用PCA(如人脸识别中的“特征脸”)。
(2)深度学习方法:用卷积自编码器(CAE)提取低维特征。
5. 混合型数据(数值+类别)
(1)统一表征:对类别变量编码(如目标编码、嵌入),与数值变量拼接后降维。使用专门模型(如广义低秩模型,GLRM)。
二、如何选择降维方法进行数据降维
降维方法需要综合考虑数据特性、问题目标和方法假设。
1.判断数据是否需要降维
(1)明确降维目标:
| 描述 | 方法推荐 |
|---|---|
| 可视化(降至2D/3D) | 优先选非线性方法(t-SNE/UMAP) |
| 减少计算开销 | 线性方法(PCA)或特征选择 |
| 去除噪声/冗余特征 | PCA、自动编码器或特征选择 |
| 提高模型性能 | 结合监督方法(LDA、嵌入法) |
(2)检查数据维度问题:
| 描述 | 方法推荐 |
|---|---|
| 特征数远大于样本数(如基因数据) | 必须降维 |
| 特征间高度相关 | PCA/线性方法有效 |
| 特征稀疏(如文本) | NMF或稀疏PCA |
2.选择降维方法的决策流程
(1)分析数据结构
| 数据特性 | 推荐方法 |
|---|---|
| 线性关系(特征间方差主导) | PCA、LDA(有标签)、SVD |
| 非线性流形(复杂拓扑) | t-SNE、UMAP、LLE、ISOMAP |
| 混合类型数据 | 统一编码后PCA,或广义低秩模型(GLRM) |
| 高稀疏性(如文本) | NMF、稀疏PCA |
(2)是否带标签?
有监督任务(分类/回归),优先用LDA(线性)或监督自编码器。特征选择递归特征消除(RFE)、基于模型的重要性排序(如XGBoost);无监督任务,PCA、t-SNE、UMAP等。
(3)是否需要可解释性
| 特性 | 推荐方法 |
|---|---|
| 需要解释特征贡献 | PCA(主成分可分析)、特征选择。 |
| 无需解释 | 自编码器、t-SNE(侧重可视化)。 |
(4)评估计算资源
| 特性 | 推荐方法 |
|---|---|
| 大规模数据 | PCA、随机投影、增量PCA(内存高效)。 |
| 小样本高维数据 | t-SNE、UMAP(但需调参) |
三、线性降维
1.主成分分析(PCA)
主成分分析(PCA,Principal Component Analysis)是一种统计方法,用于通过线性变换将数据降维,同时尽可能保留数据中的主要变异信息。它是一种无监督学习方法,广泛应用于数据预处理、特征提取、降维、数据可视化和噪声去除等领域。
(1)PCA的核心思想
PCA的目标是将原始数据投影到一组新的坐标轴(主成分)上,使得这些坐标轴的方向能够最大化数据的方差。 具体来说:
第一个主成分(PC1):是数据中方差最大的方向。
第二个主成分(PC2):是与PC1正交的方向中方差最大的方向。
后续主成分:依次类推,每个主成分都与之前的所有主成分正交,并且在剩余的方差中最大化。通过这种方式,PCA能够将数据的主要结构保留下来,同时去除一些不重要的信息(如噪声或冗余特征)。
(2)PCA的计算原理和过程代码示例
在这个例子中:
第一个主成分解释了50%的方差。
第二个主成分解释了50%的方差。
两个主成分的方差解释率之和为100%,说明降维后的数据保留了原始数据的全部信息。
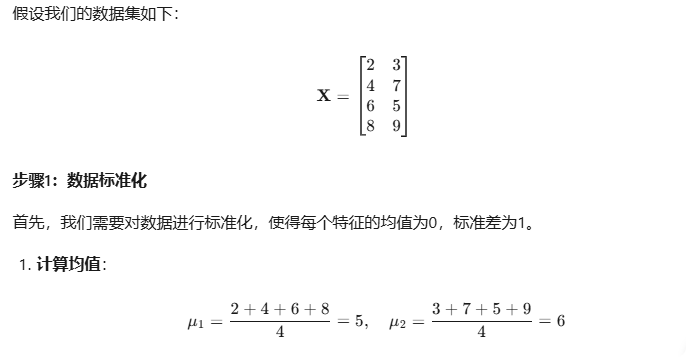
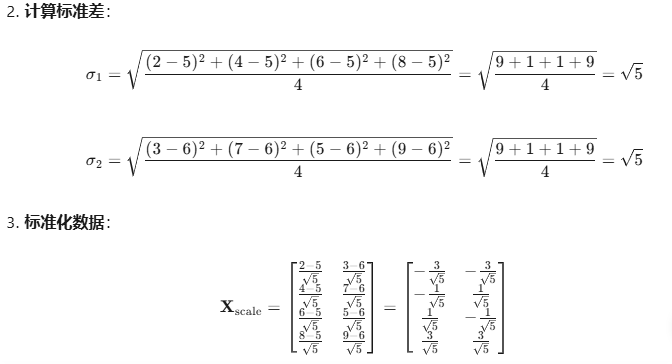

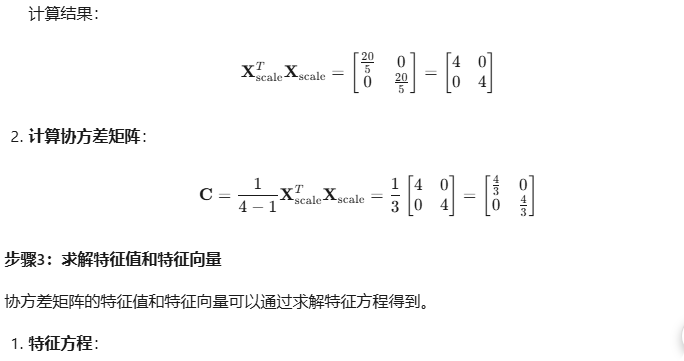
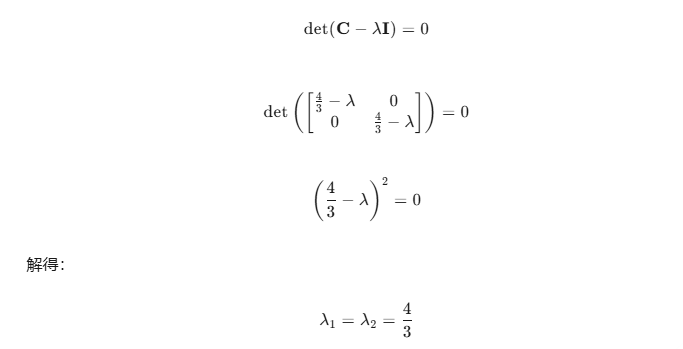



from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
import numpy as np# 示例数据
X = np.array([[2, 3],[4, 7],[6, 5],[8, 9]])# 数据标准化
scaler = StandardScaler()
X_scale = scaler.fit_transform(X)# 执行PCA
pca = PCA(n_components=2) # 降维到2维
X_reduce = pca.fit_transform(X_scale)# 输出结果
print("原始数据(标准化后):\n", X_scale)
print("降维后的数据:\n", X_reduce)
print("主成分方向(特征向量):\n", pca.components_)
print("方差解释率:\n", pca.explained_variance_ratio_)
2.线性判别分析(LDA)
线性判别分析(Linear Discriminant Analysis, LDA)是一种监督学习降维与分类方法,核心目标是通过线性变换将高维数据投影到低维空间,使得同类样本尽可能紧凑、不同类样本尽可能分离,从而提升分类性能。
(1)核心思想
与无监督的 PCA 不同,LDA 利用类别标签信息,通过最大化类间方差与最小化类内方差的比值,寻找最优投影方向。直观理解,假设两类数据在二维空间中分布,LDA 的目标是找到一条直线,使得两类样本在该直线上的投影满足,类内样本尽可能集中(类内方差小);类间样本中心距离尽可能远(类间方差大)。
3.非负矩阵分解(NMF)
将数据分解为非负矩阵的乘积,适用于所有特征为非负的场景(如图像)。
4.奇异值分解(SVD)
对矩阵进行分解,保留主要奇异值,常用于推荐系统和文本数据(如潜在语义分析)。
四、非线性降维
1.t-SNE(t-分布随机邻域嵌入)
保留局部相似性,适合高维数据可视化(如将数据降至2D/3D),但计算开销较大。
2.UMAP(均匀流形近似与投影)
类似t-SNE,但计算效率更高,能同时保留局部和全局结构。
3.ISOMAP(等距映射)
4.局部线性嵌入(LLE)
五、基于特征选择的降维
1.过滤法
使用统计指标(如方差、卡方检验、互信息)选择重要特征。
2.包装法
通过模型性能评估特征子集(如递归特征消除RFE)。
3.嵌入法
模型训练过程中自动选择特征(如Lasso回归、决策树的特征重要性)。
六、基于神经网络的降维
1.自编码器(Autoencoder)
通过编码器压缩数据,解码器重建数据,隐层作为低维表示。可处理非线性关系。
2.变分自编码器(VAE)
在自编码器中引入概率生成模型,适合生成任务。
3.深度非线性降维(如深度信念网络)
利用多层神经网络学习复杂非线性映射。