DAX权威指南5:筛选上下文、表操作函数与层级结构
文章目录
- 十、筛选上下文
- 10.1 HASONEVALUE 和 SELECTEDVALUE:选择单一值
- 10.1.1 HASONEVALUE:确保筛选器返回单一值
- 10.1.2 SELECTEDVALUE:没有单一值时返回默认值
- 10.2 ISFILTERED 和 ISCROSSFILTERED:确认筛选器状态
- 10.2.1 检查直接筛选器
- 10.2.2 检查交叉筛选器
- 10.3 ALLEXCEPT 和 ALL / VALUES 的差异
- 10.3.1 筛选器检测误区
- 10.3.2 使用 ALL清除特定列筛选器
- 10.3.3 使用ALLEXCEPT保留特定筛选器
- 10.3.4 最佳实践:ALL与VALUES组合
- 10.4 VALUES 与 FILTERS :可见值与筛选值的区别
- 10.4.1 VALUES 与 FILTERS
- 10.4.2 HASONEVALUE vs HASONEFILTER
- 10.5 使用 ALL 避免上下文转换
- 10.5.1 ALL覆盖上下文转换
- 10.5.2 计算列中的实际应用
- 10.6 数据沿袭
- 10.6.1 数据沿袭的定义
- 10.6.2 ISEMPTY检查表是否为空
- 10.6.3 TREATAS函数:修改数据沿袭
- 10.6.3.1 单列修改
- 10.6.3.2 多列修改
- 10.7 理解任意筛选
- 10.7.1 简单筛选与任意筛选
- 10.7.2 任意筛选的复杂性
- 10.7.2.1 错误分析
- 10.7.2.2 改进一:迭代唯一列
- 10.7.2.3 改进二:使用KEEPFILTERS保留原始筛选
- 10.7.3 最佳实践
- 十一、层级
- 11.1 计算层级占比
- 11.2 父子层级处理
- 11.2.1 父子层级的背景与挑战
- 11.2.2 数据模型的转换
- 11.2.2.1 创建计算列
- 11.2.2.2 LOOKUPVALUE与 PATHITEM
- 11.2.2.3 构建层级列
- 11.2.3 可视化优化
- 11.2.3.1 删除空行
- 11.2.3.2 控制层级显示
- 十二、表
- 12.1 CALCULATETABLE
- 12.1.1 基本语法
- 12.1.2 与 FILTER 的区别
- 12.1.3 CALCULATETABLE 的限制
- 12.2 使用 `ADDCOLUMNS`扩展表结构
- 12.2.1 基本语法与用法
- 12.2.2 复杂筛选
- 12.3 使用 `SUMMARIZE`进行分组与聚合
- 12.4 使用 `CROSSJOIN`生成笛卡尔积
- 12.4.1 基本语法
- 12.4.2 复杂筛选优化(重要)
- 12.5 使用 `UNION`合并表
- 12.5.1 输入表沿袭不同时,合并表失去数据沿袭
- 12.5.2 对策一:直接筛选(手动处理沿袭)
- 12.5.3 使用 TREATAS 恢复沿袭
- 12.6 使用 `INTERSECT`求交集
- 12.6.1 数据沿袭问题
- 12.6.2 推荐使用TREATAS
- 12.7 使用 `EXCEPT`求差集
- 12.8 用表做筛选
- 12.8.1 OR筛选
- 12.8.1.1 使用 CROSSJOIN 生成所有可能的组合
- 12.8.1.2 使用 SUMMARIZE 生成有效组合
- 12.8.1.3 使用 UNION 进一步优化
- 12.8.2 时间维度计算
- 12.8.2.1 计算客户生命周期价值(LTV)
- 12.8.2.2 计算新客户
- 12.8.3 使用 IN、CONTAINSROW 和 CONTAINS
- 12.8.4 使用 DETAILROWS 实现表表达式的复用(略)
- 12.9 创建计算表
- 12.9.1 SELECTCOLUMNS
- 12.9.2 用 ROW 创建单行静态表
- 12.9.3 使用 DATATABLE 创建多行静态表
- 12.9.4 使用 GENERATESERIES 创建序列表
- 12.9.4.1 基本语法与用法
- 12.9.4.2 使用场景
十、筛选上下文
在DAX中,不同的筛选上下文会导致公式返回不同的结果。在设计度量时,需要检查当前的筛选上下文是否符合公式的要求。比如一个公式可能在月级数据中正常工作,但在年度数据中返回错误结果;或者在单个客户筛选下正常工作,但在多个客户筛选下返回错误结果。如果不符合,返回空白值比返回没有意义的错误值更好。
10.1 HASONEVALUE 和 SELECTEDVALUE:选择单一值
10.1.1 HASONEVALUE:确保筛选器返回单一值
在许多数据分析场景中,我们希望某些计算仅在筛选上下文中存在单一值时才进行。假设我们有以下 QTD 销售额的公式:
-- 季度至今
QTD Sales := CALCULATE ( [Sales Amount], DATESQTD ( 'Date'[Date] ) )
这个公式在月度级别上运行良好,但在年度级别上,它会返回最后一个季度的值,这可能会让用户感到困惑。实际上,QTD 的聚合运算在月度级别及以下才是有意义的,不应该在季度及以上级别进行计算。为了确保 这一点,我们可以使用 HASONEVALUE 函数:
QTD Sales :=
IF (HASONEVALUE ( 'Date'[Month] ),CALCULATE ( [Sales Amount], DATESQTD ( 'Date'[Date] ) )
)

在这个公式中,HASONEVALUE 检查 'Date'[Month] 是否只有一个值。如果是,计算继续;如果不是,返回空白。这样,QTD 销售额仅在月度级别上显示,避免了在季度和年度级别上的误导性结果。同样的,许多的时间智能函数只有在筛选上下文筛选了一个特定时间段(比如一个月、一个季度)才有意义,其它时候,都应该返回空白。
扩展开来,如果某个公式在筛选上下文中不能产生准确的结果,那么最好验证筛选上下文中是否满足最小要求并进行相应操作。另一个常见的应用场景是客户排名。我们希望当前筛选上下文中只有一个客户被选中时,才进行排名计算,避免在多个客户被选中时返回错误的排名结果。使用 HASONEVALUE 可以实现这一点。
10.1.2 SELECTEDVALUE:没有单一值时返回默认值
SELECTEDVALUE 函数是 HASONEVALUE 的一个扩展,它不仅检查筛选上下文中是否存在单一值,还可以在没有单一值时提供一个默认值。这在处理用户输入的参数时非常有用。
假设我们有一个报告,允许用户通过切片器选择一个通货膨胀率,然后根据这个通货膨胀率调整前几年的销售额。最终报告效果如下:

为了区分无效选择(选择多个值或者没有选择),我们可以使用 HASONEVALUE 检查用户是否已使用切片器选择了单个值:
User Selected Inflation :=
IF (HASONEVALUE ( 'Inflation Rate'[Inflation] ),VALUES ( 'Inflation Rate'[Inflation] ),0
)
由于这种模式非常普遍,因此 DAX 也提供了其他选择,即SELECTEDVALUE:
-- 检查 'Inflation Rate'[Inflation]是否有一个单一值,有就返回,没有则返回默认值0
User Selected Inflation := SELECTEDVALUE ( 'Inflation Rate'[Inflation], 0 )
接下来,我们可以使用这个通货膨胀率来计算膨胀系数和最终调整后的销售额:
-- 膨胀系数Inflation Multiplier公式略Inflation Adjusted Sales :=
SUMX (VALUES ( 'Date'[Calendar Year] ),[Sales Amount] * [Inflation Multiplier]
)
SELECTEDVALUE 也可以用于其他动态参数选择的场景。例如,我们可以让用户选择一个日期范围,然后根据这个日期范围计算特定的指标。如果用户未选择任何日期范围,我们可以提供一个默认的日期范围。
10.2 ISFILTERED 和 ISCROSSFILTERED:确认筛选器状态
ISFILTERED 函数和ISCROSSFILTERED 都用于指定的列或表进行检查,前者检查是否存在直接筛选器,后者检查是否存在交叉筛选器。两者都返回布尔值(True或False)。交叉筛选器是指通过其它列的筛选器间接影响当前列或表的筛选器。
- 列级别:如果某个列上有直接筛选器 / 交叉筛选器,ISFILTERED / ISCROSSFILTERED返回True;
- 表级别:如果某个表的任何一列上有直接筛选器 / 交叉筛选器,ISFILTERED / ISCROSSFILTERED返回True。
10.2.1 检查直接筛选器
-
公式筛选:以下公式中,
CALCULATE函数对'Product'[Color]列应用了一个直接筛选器。因此,ISFILTERED('Product'[Color])会返回TRUE。RedColors := CALCULATE ( [Sales Amount], 'Product'[Color] = "Red" ) -
报表筛选:如果我们在报表中对
Customer[Gender]列应用了筛选器,Filter Gender会返回TRUEFilter Gender := ISFILTERED ( Customer[Gender] )
10.2.2 检查交叉筛选器
筛选器会因为关系的传递,而作用于整个数据模型,所以对某个表或表列进行筛选,那么所有相关联的表都会被交叉筛选。以下面的模型来说,假设对’Product’[Color]列进行筛选,那么Sales 表中的任何列都会被此筛选器进行交叉筛选(Sales 和 Product 之间是双向交叉关系)。

下面进行验证,我们对 Customer[Gender] 列应用了筛选器:
Filter Gender := ISFILTERED ( Customer[Gender] )
Cross Filter Customer := ISCROSSFILTERED ( Customer )
Cross Filter Sales := ISCROSSFILTERED ( Sales )
Cross Filter Product := ISCROSSFILTERED ( 'Product' )
Cross Filter Store := ISCROSSFILTERED ( Store )
把以上结果放入矩阵,以 Customer [Continent] 列和 Customer[Gender]列为行(顾客地区和顾客性别),结果如下:

- 当 Customer [Continent] 列或 Customer[Gender] 列上有筛选器时,整个 Customer 表将被交叉筛选的。
- Customer[Gender] 列只在那些在其上有活动筛选器的行上是被筛选的。在小计级别,筛选器只作用在Customer[Continent] 列,Customer[Gender] 列没有被筛选。
- 只要 Customer 表的一列上都存在一个筛选器,Sales 表就会被交叉筛选,但Store 表不会。因为Customer表的关系可以传递到 Sales 表,而Store表只能单向传递到Sales 表,但不能反过来。
ISFILTERED 和 ISCROSSFILTERED一般有两种常用的场景:
-
通过检查是否存在筛选器,根据筛选上下文动态调整计算逻辑,比如:
Dynamic Calculation := IF (ISFILTERED ( Customer[Gender] ),[Sales Amount for Female],[Total Sales Amount] ) -
处理层次结构:将在第 11 章“处理层次结构”中介绍。
10.3 ALLEXCEPT 和 ALL / VALUES 的差异
10.3.1 筛选器检测误区
ISFILTERED和ISCROSSFILTERED函数可以检查列或表上是否存在筛选器,但这并不能确定筛选器是否真正影响了可见的数据范围。即使某个列被筛选器筛选,它仍然可能显示所有可能的值。
以Customer表举例,其中 Customer[Type] 列显示顾客是个人还是公司,Customer[Gender] 列显示顾客性别。对于公司类型,性别都是BLANK()。我们使用NumOfCustomers度量对Customer表的行进行数,使用Filtered Gender 度量检查Customer [Gender] 列上是否应用了直接筛选(ISFILTERED ):
NumOfCustomers := COUNTROWS ( Customer )
Filtered Gender:= ISFILTERED ( Customer[Gender] )

可以看到,对于公司类型客户而言,即使使用了筛选器(Filtered Gender返回True),但实际上返回了整个数据集,没有发生任何筛选行为,因为它的值(空白)不在筛选器筛选范围内。要判断是否发生了实际的筛选行为,更可靠的方法是,在筛选与不筛选的上下文中对行数进行计数。因为有顾客性别和顾客类型两种维度,所以可以在这两种维度上分别进行筛选判断。
10.3.2 使用 ALL清除特定列筛选器
使用ALL 清除性别列上的筛选器,保留所有其它的筛选器:
All Gender :=
CALCULATE (
[NumOfCustomers],
ALL ( Customer[Gender] )
)
All customers visible度量用于判断列上是否所有值都可见,即是否发生了实际的筛选行为:

这种方法简单直接,但缺点是硬编码了特定列名,当报表使用其他列进行筛选时(比如将 Gender列换成Continent 列切片),这种方法就会失效(All customers visible 度量值始终为 TRUE,没有发生任何筛选) 。

10.3.3 使用ALLEXCEPT保留特定筛选器
更通用的方法是使用ALLEXCEPT只保留Customer Type列的筛选:
AllExcept Type :=
CALCULATE( [NumOfCustomers], ALLEXCEPT( Customer, Customer[Customer Type] )
)
这样,无论按什么列进行切片,Customer Type列都会被实际筛选(交叉筛选):


但这个方式有一个隐藏的陷进:当Customer Type列不在报表中时,ALLEXCEPT会清除所有筛选器,比如下图中的性别筛选器)。

ALLEXCEPT 的核心行为是:保留指定列的直接筛选器,清除表中所有其他列的筛选器。当报表中没有 Customer Type 列时,表示 Customer Type 列没有被直接筛选,所以它不会保留任何筛选器,最终效果等同于:
CALCULATE( [NumOfCustomers], ALL( Customer ) ) -- 清除所有 Customer 表的筛选
10.3.4 最佳实践:ALL与VALUES组合
AllValues Type :=
CALCULATE( [NumOfCustomers], ALL( Customer ), VALUES( Customer[Customer Type] )
)
先使用ALL(Customer)清除Customer表上的所有筛选器,再使用VALUES(Customer[Customer Type])重新添加特定列的可见值(这包括直接筛选和交叉筛选)。所以,即使 Customer Type 不在报表中,VALUES 仍然能捕获到它的有效筛选状态。

总结:
ALLEXCEPT: 仅保留显式直接筛选,如果目标列不在报表中(无直接筛选),它会清除所有筛选,导致意外结果。ALL + VALUES:能捕获直接和间接筛选,更健壮,适用于动态分析场景。
10.4 VALUES 与 FILTERS :可见值与筛选值的区别
10.4.1 VALUES 与 FILTERS
在《DAX 权威指南1:DAX计算、表函数与计算上下文》3.5 VALUES与 DISTINCT章节中,介绍过这两个函数都用于返回“唯一值”,但它们在处理空白行时表现不同:
| 函数 | 返回结果 | 说明 |
|---|---|---|
VALUES(Column) | 返回列的唯一值列表,考虑筛选器和空白行(如果存在) | 如果某列包含关联表中不存在的值 计算引擎会添加一个空白项来表示这种不匹配 |
VALUES(TableName) | 返回表的所有行,再加一个空白行(如果存在不匹配情况) | 仅接受表引用 |
DISTINCT(Column) | 返回唯一值列表,考虑筛选器但不考虑空白行 | 纯粹基于列本身的去重,不检查关联表的有效性。 |
DISTINCT(Table) | 返回表的唯一行,不考虑空白行 | 接受任何有效的表表达式。 |
- 常规关系中,当关系无效时,DAX 引擎会自动在表中添加一个空白行,以维护引用完整性(简单理解就是即使不匹配的项,也添加一个空白行来匹配它,详见《PowerBI数据建模基础操作1》2.7章节)。
- 在计算列或计算表中,因为不存在筛选器,
VALUES与DISTINCT和ALL返回的结果是一样的,如果是在度量值中,因为考虑筛选器,结果会不一样。
而对于VALUES和FILTERS,两者都返回指定列筛选之后的值,但是也有区别:
VALUES:返回当前筛选上下文中实际可见值的唯一值列表(自动去重),这表示:- 考虑所有直接和间接过滤器的影响(直接筛选和所有交叉筛选)
- 考虑行上下文和筛选上下文
- 如果应用于表,返回当前上下文中的可见行
- FILTERS:直接应用于指定列的所有筛选值,无论这些值在当前上下文中是否有对应的数据存在
- 只能作用于列
- 只考虑直接筛选,不考虑交叉筛选(不考虑来自其他列的间接或相关过滤器)。
假设我们有一个产品表,下面分别使用两个切片器对产品进行筛选。在颜色切片器中选择了黑色、棕色、蓝色和天蓝色,在类别切片器中选择了"TV and Video"类别。我们先使用VALUES来显示被筛选后的颜色:
Selected Colors :=
"Showing "& CONCATENATEX (VALUES ( 'Product'[Color] ),'Product'[Color],", ",'Product'[Color], ASC) & " colors."

因为在"TV and Video"类别中,只有黑色和棕色的产品,所以Selected Colors 度量值只显示这两种颜色,也就是VALUES实际上考虑了当前类别这个筛选上下文,只返回实际有的值。
如果将代码中的 VALUES 改为FILTERS:
Selected Colors :=
"Showing "& CONCATENATEX(FILTERS('Product'[Color]),'Product'[Color],", ",'Product'[Color], ASC) & " colors."
结果显示了被切片器选择的所有颜色,不考虑交叉筛选,不论是否存在对应数据:

10.4.2 HASONEVALUE vs HASONEFILTER
| 对比维度 | HASONEVALUE | HASONEFILTER |
|---|---|---|
| 功能 | 检查列在当前上下文中是否只有一个可见值 | 检查列上是否只有一个活动的筛选器 |
| 考虑范围 | 考虑直接筛选和交叉筛选 | 仅考虑直接应用于该列的筛选器 |
| 典型用途 | 验证计算是否在单个值的上下文中运行 | 检查用户是否对特定列应用了单一筛选 |
| 数据存在性 | 只计数当前上下文中实际存在的值 | 不考虑筛选器是否实际影响数据,即使筛选的值不存在于当前上下文中,也会计数 |
| 性能开销 | 较高(需评估实际数据) | 较低(仅检查筛选状态) |
HASONEFILTER函数通常更快,因为只关注筛选器本身,不关注数据,不受其他表关系影响,常用于调试或高级筛选逻辑。而在大型模型中,过度使用HASONEVALUE可能影响性能。
10.5 使用 ALL 避免上下文转换
10.5.1 ALL覆盖上下文转换
上下文转换在许多场景中非常有用,它允许我们在不同的数据上下文中重新计算度量值。然而在某些情况下,它可能会导致意外的结果或性能问题。ALL 函数可以清除表上的所有筛选器,我们可以用它来避免上下文转换。
SUMX (Sales,CALCULATE (...,ALL ( Sales ))
)
当使用CALCULATE函数时,DAX引擎会按照以下精确顺序执行操作:
- 计算筛选器参数
- 如果存在行上下文,则发生上下文转换,将行上下文转为筛选上下文
- 应用CALCULATE修饰符(修改器)
- 将最终的筛选器参数结果应用到筛选上下文中
本例中,CALCULATE在SUMX生成的行上下文中运行。按照原本的执行顺序,仍然会执行上下文转换。但由于ALL作为修饰符会清除Sales表上的任何筛选器,所以DAX优化器会识别这一点,直接跳过无用的上下文转换步骤。
10.5.2 计算列中的实际应用
ALL作为CALCULATE修饰符使用时,能够覆盖上下文转换的效果,这种技术特别适用于计算列中需要突破当前行上下文限制的场景。比如在计算列中,计算当前产品占所有产品的销售百分比:
-- 计算全局销售百分比
'Product'[GlobalPct] =
VAR SalesProduct = [Sales Amount]
VAR SalesAllProducts =CALCULATE ( [Sales Amount], ALL ( 'Product' ) ) -- 清除所有产品筛选器
VAR Result =DIVIDE ( SalesProduct, SalesAllProducts )
RETURNResult
ALLEXCEPT提供了更精细的控制,可以保留特定列的筛选上下文,我们可以用它来计算同一类别中所有产品的百分比:
-- 计算类别销售百分比
'Product'[CategoryPct] =
VAR SalesProduct = [Sales Amount]
VAR SalesCategory =CALCULATE ( [Sales Amount], ALLEXCEPT ( 'Product', 'Product'[Category] ) )
VAR Result =DIVIDE ( SalesProduct, SalesCategory )
RETURNResult

10.6 数据沿袭
10.6.1 数据沿袭的定义
在DAX中,数据沿袭是一个关键概念,它标识了数据在模型中的“身份”和“归属”。简单来说,数据沿袭标记了数据的来源和它在数据模型中的位置。
未命名表不具有数据沿袭,不能进行筛选:通过表达式生成新的数据时,这些数据则会失去原有的沿袭,成为匿名数据。比如我们想筛选出 'Product’表中红色和蓝色的产品,直接使用未命名表是无法实现筛选的。以下代码就是一个典型的例子:
Test :=
CALCULATE ([Sales Amount],{ "Red", "Blue" } -- 未命名表,无数据沿袭,DAX不知道这些值代表什么。
)

保留数据沿袭,实现正确筛选:通过使用 FILTER 和 ALL 函数,可以显式地保留数据沿袭:
Test :=
CALCULATE ([Sales Amount],FILTER (ALL ( 'Product'[Color] ),'Product'[Color] IN { "Red", "Blue" })
)
- ALL ( ‘Product’[Color] ) 返回一个包含 Product 表中所有颜色的表,并保留了 Color 列的数据沿袭。
- FILTER 函数扫描这个表,并检查每种颜色是否在 { “Red”, “Blue” } 中
- 最终,FILTER 返回一个带有数据沿袭的表,CALCULATE 函数可以正确地应用筛选。

以上代码只是为了详细说明,实际上使用布尔筛选器更简洁。
10.6.2 ISEMPTY检查表是否为空
传统方法中,我们使用 COUNTROWS 函数来检查表是否为空:
COUNTROWS ( VALUES ( 'Product'[Color] ) ) = 0
ISEMPTY 函数也可以用于测试表是否为空, 且更加简便:
ISEMPTY ( VALUES ( 'Product'[Color] ) )
ISEMPTY明确告知引擎只需检查表是否为空,而非计算具体行数,通常不需要完全扫描目标表,所以性能更优。假设需要计算从未购买某些产品的客户数量,可以使用以下公式:
NonBuyingCustomers :=
VAR SelectedCustomers =CALCULATETABLE ( DISTINCT ( Sales[CustomerKey] ), ALLSELECTED () )
VAR CustomersWithoutSales =FILTER ( SelectedCustomers, ISEMPTY ( RELATEDTABLE ( Sales ) ) )
VAR Result =COUNTROWS ( CustomersWithoutSales )
RETURNResult

- 通过 DISTINCT获取当前筛选上下文中的唯一的客户列表
SelectedCustomers - 检查每个客户是否在
Sales表中没有相关记录(即RELATEDTABLE ( Sales )是否为空) - 计算未购买任何所选产品的客户数量
示例中一个关键点是DAX如何知道CustomerKey值与Sales表的关系。这得益于DAX维护的数据沿袭特性。数字本身没有意义,比如一个单独的值如120,可以表示客户ID或产品数量。但DAX通过跟踪值的来源(数据沿袭)可以理解其业务含义。
在本例中,Sales[CustomerKey] 是从 Sales 表中提取的,所以即使 SelectedCustomers 是一个独立的表,DAX 仍然知道这些客户键的来源是 Sales 表的 CustomerKey 列,数据沿袭确保了 DAX 引擎能够正确地识别和应用这种关联关系。当 RELATEDTABLE ( Sales ) 被调用时,DAX 会利用数据沿袭信息,知道如何将 SelectedCustomers 中的客户键与 Sales 表中的行进行关联。
10.6.3 TREATAS函数:修改数据沿袭
10.6.3.1 单列修改
TREATAS 可用于修改表表达式中一列或多列的数据沿袭。继续上面的例子,我们使用TREATAS函数,为匿名列赋予正确的数据沿袭,使其能够正确地筛选数据模型:
Test :=
CALCULATE ([Sales Amount],TREATAS ( { "Red", "Blue" }, 'Product'[Color] )
)
10.6.3.2 多列修改
在第 8 章“时间智能计算”中,有一个示例是计算每个客户的每日余额信息。由于每个客户的最后结余日期不同,直接使用LASTNONBLANK将无法正确处理总计信息。
-- LASTNONBLANK返回最后一个非空值
LastBalanceNonBlank :=
CALCULATE (SUM ( Balances[Balance] ), LASTNONBLANK ( 'Date'[Date], COUNTROWS ( RELATEDTABLE ( Balances ) ) )
)

上面各个客户的结果是正确的,但是当不同客户有不同的最后结余日期时,它无法正确计算总数。上图中Total的结果是1950,而不是三个人余额的总和。
当筛选上下文没有筛选客户名时,LASTNONBLANK 会查找所有客户中的最后一个有值的日期。在这个例子中,Maurizio Macagno 的最后结余日期是 2023-07-18,这是所有客户中最后的日期。因此,LASTNONBLANK 会返回 2023-07-18 作为最后日期,计算的总余额只会包括 Maurizio Macagno 的余额,即 1950。
正确处理方式是分别计算每个客户的最后结余,然后汇总结果:
LastBalanceIndividualCustomer :=
SUMX (VALUES ( Balances[Name] ),CALCULATE (SUM ( Balances[Balance] ),LASTNONBLANK ( 'Date'[Date], COUNTROWS ( RELATEDTABLE ( Balances ) ) ))
)

此方法可以得到正确的结果,但问题是使用了嵌套迭代,会产生性能问题。优化方案是直接创建一个包含客户名称和最后余额日期的表,并将其用于筛选,以避免嵌套迭代。
LastBalanceIndividualCustomer Optimized :=
VAR LastCustomerDate =ADDCOLUMNS (VALUES ( Balances[Name] ),"LastDate",CALCULATE (MAX ( Balances[Date] ),DATESBETWEEN ( 'Date'[Date], BLANK (), MAX ( Balances[Date] ) )))
--
VAR FilterCustomerDate =TREATAS ( LastCustomerDate, Balances[Name], 'Date'[Date] )
VAR SumLastBalance =CALCULATE ( SUM ( Balances[Balance] ), FilterCustomerDate )
RETURNSumLastBalance
LastCustomerDate表:由Balances[Name]列和一个未命名列组成,分别表示客户名及其最后结余日期FilterCustomerDate表:通过 TREATAS 函数修改数据沿袭,使其能够用于筛选
10.7 理解任意筛选
10.7.1 简单筛选与任意筛选
在 DAX 中,筛选可以分为两种类型:简单筛选(Simple Filtering)和任意筛选(Arbitrary Filtering)。
-
列筛选:最简单的筛选形式是列筛选,即仅针对单列的值进行筛选,例如:
CALCULATE ([Sales Amount],'Product'[Color] IN { "Red", "Blue", "Green" } ) -
简单筛选(多列组合):简单筛选可以包含多列,可以很容易地表示为列这些列的所有可能组合,比如:
CALCULATE ([Sales Amount],'Product'[Color] IN { "Red", "Blue" },'Date'[Calendar Year Number] IN { 2007, 2008, 2009 } )这等价于:
CALCULATE ([Sales Amount],TREATAS ({( "Red", 2007 ),( "Red", 2008 ),( "Red", 2009 ),( "Blue", 2007 ),( "Blue", 2008 ),( "Blue", 2009 )},'Product'[Color],'Date'[Calendar Year Number]) ) -
任意筛选(复杂筛选):任意筛选通常涉及多列的非完全组合,所以无法表示为简单筛选,例如:
CALCULATE ([Sales Amount],TREATAS ({( "CY 2007", "December" ),( "CY 2008", "January" )},'Date'[Calendar Year],'Date'[Month]) )在这个例子中,筛选条件涉及 Date[Calendar Year] 和 Date[Month] 两列,但并不是这两列的所有组合。这种筛选方式无法通过简单的列筛选实现。而以下多列筛选是简单筛选:
CALCULATE ([Sales Amount],TREATAS ({( "CY 2007", "December" ),( "CY 2008", "December" )},'Date'[Calendar Year],'Date'[Month]) )可以通过以下方式将前一个表达式重写为两个列筛选的组合:
CALCULATE ([Sales Amount],'Date'[Calendar Year] IN { "CY 2007", "CY 2008" },'Date'[Month] = "December" )
10.7.2 任意筛选的复杂性
通过 Excel 和 Power BI 轻松定义任意筛选,比如以下筛选了 2007 年和 2008 年的不同月份。


10.7.2.1 错误分析
当 CALCULATE 在某一列上应用新的筛选条件时,它会用新的筛选条件替换掉原有的筛选条件。如果原有的筛选条件是一个复杂的任意筛选(涉及多个列的特定组合,而不是简单的列筛选)这种替换行为可能会导致原有的筛选逻辑被破坏,使得公式计算的结果不准确。而且在原有的任意筛选逻辑被覆盖后,很难通过常规方式追溯或发现这种错误,从而导致问题难以被察觉和解决。
假设你定义了一个度量值,将年份固定为 2007 年:
Sales Amount 2007 :=
CALCULATE ([Sales Amount],'Date'[Calendar Year] = "CY 2007"
)

可以看到,当选择 2008 年时,CALCULATE 会将年份替换为 2007 年,但月份筛选保持不变,于是 2008 年 1 月显示的是 2007 年 1 月的销售额。
更复杂的情况是计算月平均销售额。如果直接迭代月份名称,可能会导致合计值异常高,因为每次迭代时,CALCULATE 会将当前月份添加到筛选上下文中,从而覆盖原始的任意筛选。
Monthly Avg :=
AVERAGEX (VALUES ( 'Date'[Month] ),[Sales Amount]
)

“合计”行的筛选上下文如下:
TREATAS ({( "CY 2007", "September" ),( "CY 2007", "October" ),( "CY 2007", "November" ),( "CY 2007", "December" ),( "CY 2008", "January" ),( "CY 2008", "February" ),( "CY 2008", "March" )},'Date'[Calendar Year],'Date'[Month]
)
将整个均值计算公式展开就是:
CALCULATE (AVERAGEX (VALUES ( 'Date'[Month] ),-- [Sales Amount]度量值引用会触发CALCULATE的隐式调用CALCULATE ( SUMX ( Sales, Sales[Quantity] * Sales[Net Price] ) )),TREATAS ( { ("CY 2007","September"), ("CY 2007","October"), ..., ("CY 2008","March") },'Date'[Calendar Year], 'Date'[Month] )
)
当AVERAGEX迭代每个月份时,以"January"为例:
- 行上下文:AVERAGEX中,
VALUES('Date'[Month])会为每个月份创建行上下文,此处是"January" - 上下文转换:CALCULATE将行上下文转换为筛选上下文,添加当前月份到筛选条件,即添加
'Date'[Month]="January"筛选 - 覆盖原列筛选:在嵌套CALCULATE中,同列上的筛选内层会覆盖外层,除非使用KEEPFILTERS保留外层筛选器
最后一点展开来就是——原始筛选器为:
'Date'[Calendar Year] IN {"CY 2007", "CY 2008"}'Date'[Month] IN {"September","October","November","December","January","February","March"}
新添加的筛选器:'Date'[Month] = "January"
合并之后为:
'Date'[Calendar Year] IN {"CY 2007", "CY 2008"}'Date'[Month] = "January"
这相当于计算2007年1月 + 2008年1月的销售总额,所以总计行结果偏高。这种行为的根本原因在于DAX的筛选上下文是"列式"存储的,而不是"行式"存储:
- 每列的筛选是独立存储的,列之间的组合关系不会被特别标记
- 当覆盖一列时,DAX引擎无法知道它原来属于某个特定组合,导致原有的组合关系破坏
10.7.2.2 改进一:迭代唯一列
将年-月作为不可分割的整体处理,每次筛选计算锁定一个具体组合,上下文转换不会破坏年-月关联性:
Monthly Avg :=
AVERAGEX (VALUES ( 'Date'[Calendar Year Month] ),[Sales Amount]
)

10.7.2.3 改进二:使用KEEPFILTERS保留原始筛选
Monthly Avg KeepFilters :=
AVERAGEX (KEEPFILTERS ( VALUES ( 'Date'[Month] ) ),[Sales Amount]
)
10.7.3 最佳实践
简单筛选之所以不容易出现问题,是因为所有可能的组合都已存在,覆盖一列筛选不会创建原始数据中不存在的组合。
-- 简单筛选所有年份的Q4月份
-- 月平均计算正确,因为所有年份都包含完整的季度月份
CALCULATE ([Monthly Avg],'Date'[Calendar Year] IN { "CY 2007", "CY 2008" },'Date'[Month] IN { "September", "October", "November", "December" }
)
任意筛选可能出错:
-- 任意筛选特定年-月组合
-- 直接使用月平均计算会出错,因为破坏了原始组合关系,不会有("CY 2007","January")等
CALCULATE ([Monthly Avg],TREATAS ({ ("CY 2007", "December"), ("CY 2008", "January") },'Date'[Calendar Year], 'Date'[Month])
)
总结:任意筛选 是 DAX 中一种强大的筛选方式,但需要谨慎使用。通过迭代唯一列或使用 KEEPFILTERS,可以避免因 CALCULATE 覆盖筛选而导致的问题。
十一、层级
11.1 计算层级占比
在数据分析中,经常需要根据层级结构计算百分比。一个典型的层级结构是产品类别->子类别->产品名称。计算不同层级的百分比公式如下:
PercOnSubcategory := DIVIDE([Sales Amount], CALCULATE([Sales Amount], ALLSELECTED(Product[Product Name])))
PercOnCategory := DIVIDE([Sales Amount],CALCULATE([Sales Amount], ALLSELECTED(Product[Subcategory])))
PercOnTotal := DIVIDE([Sales Amount], CALCULATE([Sales Amount], ALLSELECTED(Product[Category])))
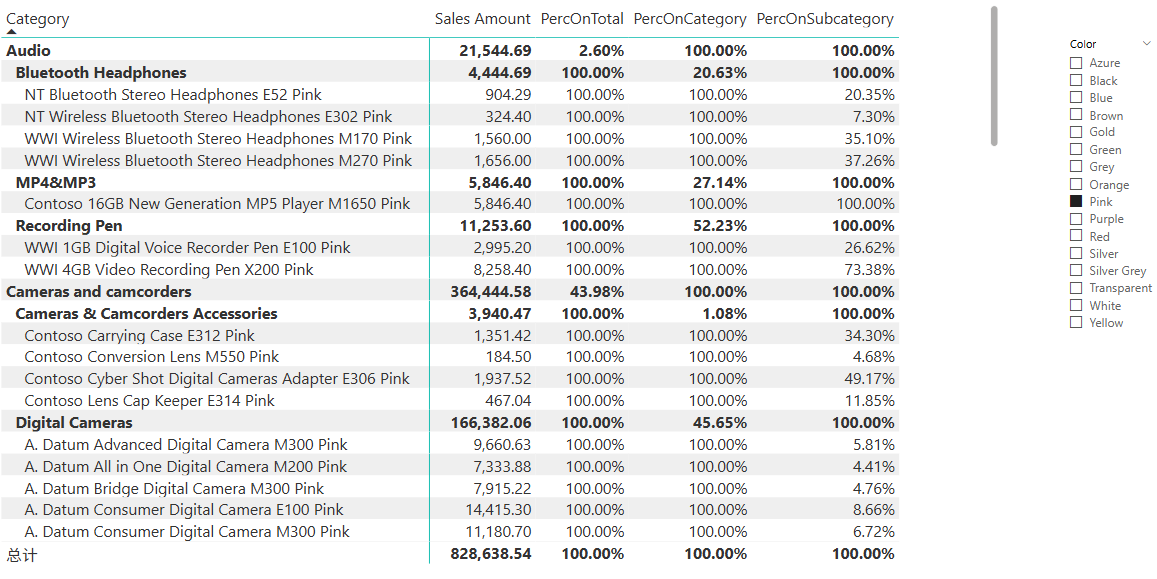
为了避免在不相关的层级上显示100%的无用值,可以使用ISINSCOPE函数来检查当前层级是否在报表中被使用。比如PercOnSubcategory公式可改为:
PercOnSubcategory :=
IF (ISINSCOPE ( Product[Product Name] ),DIVIDE ([Sales Amount],CALCULATE ([Sales Amount],ALLSELECTED ( Product[Product Name] )))
)
ISINSCOPE(<columnName>)含义为:表的列column是否正用于当前的分组汇总计算的分组中。
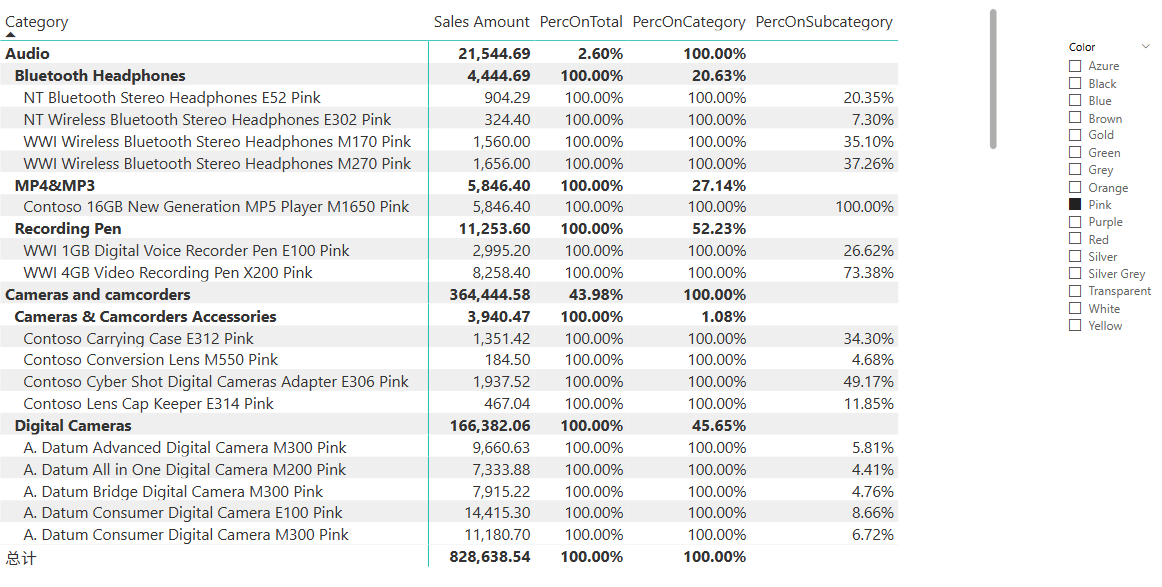
进一步的,为了简化,可以创建一个通用的PercOnParent度量值,根据当前层级动态计算百分比。IF条件的顺序很重要,需要从最内层的层级开始检查,然后一步一步地检查外层。
PercOnParent :=
VAR CurrentSales = [Sales Amount]
VAR SubcategorySales =CALCULATE ( [Sales Amount], ALLSELECTED ( Product[Product Name] ) )
VAR CategorySales =CALCULATE ( [Sales Amount], ALLSELECTED ( Product[Subcategory] ) )
VAR TotalSales =CALCULATE ( [Sales Amount], ALLSELECTED ( Product[Category] ) )
VAR RatioToParent =IF (ISINSCOPE ( Product[Product Name] ),DIVIDE ( CurrentSales, SubcategorySales ),IF (ISINSCOPE ( Product[Subcategory] ),DIVIDE ( CurrentSales, CategorySales ),IF ( ISINSCOPE ( Product[Category] ), DIVIDE ( CurrentSales, TotalSales ) )))
RETURNRatioToParent
11.2 父子层级处理
11.2.1 父子层级的背景与挑战
父子层级是一种典型的层级数据结构(通常缩写为 P / C),用于表示具有层级关系的数据。其中每个节点都有一个父节点,形成一个树状结构。比如,一个组织架构可以表示为父子层级,其中每个部门有一个上级部门,最终汇聚到根节点(如公司总部)。在 DAX 中,这种层级结构的处理面临以下挑战:
- 层级深度的不确定性:在设计数据模型时,很难预知层级的最大深度。例如,一个组织架构可能从公司到部门,再到小组,甚至到个人,层级深度变化很大。

- 年,季度,月,日期;这个层级是 4 列,在构建表的时候就知道了这个表会具有 4 列,这就叫做设计时已知
- 而对于上图这种,层级深度在设计时是很难预知的,但是最好可以预先知道最大的深度,以便可以展开到最深层(列数表示了层级的深度)
- 数据模型的限制:层级通常在单个表中表示,存储指向每行的父级的链接。但DAX 使用的表格型数据模型不支持真正的自引用关系。这意味着不能直接在同一个表中定义父子关系。以下是一个
P / C层级的规范表示, ParentKey 是每个节点的父节点的键:

下图分别显示了每个人的销售额和最终需要得到的层级聚合结果:

尽管在 DAX中,处理父子层级并非直接支持,但可以通过一些巧妙的方法实现,包括数据模型的转换、计算列和度量值的创建,以及最终的可视化实现。
11.2.2 数据模型的转换
为了在 DAX 中处理父子层级,我们需要将父子层级转换为基于列的层级。具体步骤如下:
11.2.2.1 创建计算列
首先,我们需要创建一个计算列,用于存储每个节点的完整路径。这可以通过 PATH函数实现,其语法为:
Persons[FullPath] = PATH ( Persons[PersonKey], Persons[ParentKey] )
PATH 函数接收两个参数:表的键和父键。它会递归地遍历表,并为每个节点生成一个由管道(|)分隔的键列表,表示从根节点到当前节点的路径,称之为路径字符串。

11.2.2.2 LOOKUPVALUE与 PATHITEM
LOOKUPVALUE 函数用于在表中查找特定值,并返回与该值相关联的其他列的值。它类似于 SQL 中的 SELECT 语句,可以根据一个或多个条件查找并返回指定的值。如果没有找到匹配项,则返回 BLANK()。
LOOKUPVALUE (<result_columnName>, -- 要返回的列,通常是文本类型。<search_columnName>, -- 用于查找的列,通常是键列。<SearchValue>, -- 查找的值,必须与 search_columnName 的数据类型匹配。[<SearchColumn2>, <SearchValue2>, ...] -- 可选的额外查找条件
)
- LOOKUPVALUE 函数要求查找列和返回列必须在同一个表中。
- 如果查找条件有多个匹配项,LOOKUPVALUE 将返回第一个匹配项的值。如果没有找到匹配项,将返回
BLANK()。
假设有一个 Persons 表,包含以下列:
- PersonKey:人员的唯一标识符
- Name:人员的名称
- ParentKey:父级人员的标识符
现在,我们想根据 ParentKey 查找对应的 Name。
ParentName = LOOKUPVALUE (Persons[Name], -- 要返回的列Persons[PersonKey], -- 查找的列Persons[ParentKey] -- 查找的值
)
在这个例子中,ParentName 将返回每个人员的父级人员的名称。
PATHITEM 函数用于从由 PATH 函数生成的路径字符串中提取特定位置的值,其语法为:
PATHITEM (<Path>, -- 由 PATH 函数生成的路径字符串。<ItemNumber>, -- 要提取的项的编号,从 1 开始计数<Type> -- 返回值的类型(可选,默认为 TEXT)
)-- 返回路径字符串中指定位置的值。如果没有找到指定位置的值,则返回 BLANK()。
对于Persons[FullPath]列:
Persons[FullPath] = PATH ( Persons[PersonKey], Persons[ParentKey] )
我们想提取路径中的第一个和第二个节点的键值,可以使用公式:
Level1Key = PATHITEM ( Persons[FullPath], 1, INTEGER )
Level2Key = PATHITEM ( Persons[FullPath], 2, INTEGER )
在这个例子中,Level1Key 和Level2Key将分别返回路径中的第一个节点和第二个节点的键值。
- PATHITEM 函数只能处理由 PATH 函数生成的路径字符串。
- 如果 ItemNumber 超出了路径的实际长度,PATHITEM 将返回 BLANK()。
11.2.2.3 构建层级列
接下来,我们需要通过FullPath列为每个层级创建计算列。例如,如果最大层级深度为 3,我们需要创建 Level1、Level2 和 Level3 三个计算列。
Persons[Level1] =
LOOKUPVALUE (Persons[Name],Persons[PersonKey], PATHITEM ( Persons[FullPath], 1, INTEGER )
)
Persons[Level2] =
LOOKUPVALUE (Persons[Name],Persons[PersonKey], PATHITEM ( Persons[FullPath], 2, INTEGER )
)
Persons[Level3] =
LOOKUPVALUE (Persons[Name],Persons[PersonKey], PATHITEM ( Persons[FullPath], 3, INTEGER )
)这段代码的处理逻辑是:
- 使用 PATHITEM 函数从 Persons[FullPath] 中提取路径的第 n 个节点的键值。
- 使用 LOOKUPVALUE 函数根据提取的键值查找对应的 Name 列的值。
- 将查找结果存储为新的计算列 Persons[Level1]、Persons[Level2] 和 Persons[Level3]
FullPath是通过 PATH 函数生成的路径字符串,表示从根节点到当前节点的路径。
- 如果 PersonKey 是 1,ParentKey 是 NULL,则 FullPath 是 1。
- 如果 PersonKey 是 2,ParentKey 是 1,则 FullPath 是 1|2。
- 如果 PersonKey 是 3,ParentKey 是 2,则 FullPath 是 1|2|3。
对于Persons[Level1]来说,PATHITEM 函数从 Persons[FullPath] 中提取路径的第一个节点(ItemNumber = 1),并将其转换为整数类型。LOOKUPVALUE 函数在 Persons 表中查找 PersonKey 等于 1的行,并返回该行的 Name 列的值,最终Persons[Level1] 列将存储每个节点的根节点名称。
以此类推,Persons[Level2] 列将存储每个节点的第二级节点名称。Persons[Level3] 列将存储每个节点的第三级节点名称。

在实际处理时,需要在数据模型设计阶段预先确定一个最大层级深度,并据此创建足够多的层级列。通过预留一些额外的层级列,可以提高数据模型的灵活性和扩展性,而无需频繁更新数据模型。
11.2.3 可视化优化
11.2.3.1 删除空行
如果一个节点只有1级深度,直接取PATHITEM第2项会得到空白,回退到Level1可以确保总是显示有意义的名称。所以,为了删除空行,我们需要修改层级列的公式,确保在路径末尾时重复上一级别的值:
PC[Level2] =
IF (PATHLENGTH ( Persons[FullPath] ) >= 2,LOOKUPVALUE (Persons[Name],Persons[PersonKey], PATHITEM ( Persons[FullPath], 2, INTEGER )),Persons[Level1]
)
使用相同的方式更新Level3 (Level1 不需要修改,因为总是有第一级)。

11.2.3.2 控制层级显示
在处理父子层级数据时,我们需要控制层级的显示深度,以确保报告中只显示有意义的层级节点。例如,在报告中我们希望显示 Annabel 的第二级节点,但不希望显示第三级节点,因为第三级节点的路径已经超出了我们希望显示的范围。

为了控制层级显示,我们需要两个关键信息:
-
每个节点的深度: 这是层级中每一行的固定值,表示该节点在层级中的位置。这个值可以通过计算列来存储。
Persons[NodeDepth] = PATHLENGTH ( Persons[FullPath] )
-
报告的当前浏览深度:这是一个动态值,它表示当前报告中显示的层级深度。例如,如果用户在报告中选择了 Annabel 的第一级和第二级节点,那么当前浏览深度为 2。这个值需要通过度量值来计算,因为它会根据报告的过滤器上下文动态变化。
-- 该公式利用了布尔值可以转换为数字的事实,其中 TRUE 的值为 1,FALSE 的值为 0 BrowseDepth := ISINSCOPE ( Persons[Level1] ) + ISINSCOPE ( Persons[Level2] ) + ISINSCOPE ( Persons[Level3] )
通过这两个值,我们可以定义一个规则:当报告的当前浏览深度小于或等于节点的深度时,该节点应该显示;否则,应该隐藏。
例如,如果 Annabel 的路径长度为 1,而报告的当前浏览深度为 2,那么 Annabel 的节点应该显示,但她的子节点(如 Catherine)的子节点(如 Michael)应该隐藏,因为它们的路径长度超过了当前浏览深度。
最终,创建一个度量值来控制显示内容:
PC Amount :=
IF (MAX ( Persons[NodeDepth] ) < [BrowseDepth],BLANK (),SUM ( Sales[Amount] )
)

MaxNodeDepth表示在当前过滤器上下文中,所有相关节点的最大深度。它反映了当前视图下最深的节点能达到的层级深度。
在当前的可视化结果中,节点的值显示不完整。例如,Annabel 的总值为 3,200,但她的子节点只显示了 2,600,缺少了 Annabel 自己的值 600。所以还需要使得非叶节点(即有子节点的节点)的值能够清晰地显示在报表中。

显示非叶节点的值:在 Persons 表中创建一个计算列 IsLeaf,用于标识节点是否为叶节点。叶节点是没有其他节点将其作为父节点的节点。
Persons[IsLeaf] =
VAR CurrentPersonKey = Persons[PersonKey]
VAR PersonsAtParentLevel =CALCULATE (COUNTROWS ( Persons ),ALL ( Persons ),Persons[ParentKey] = CurrentPersonKey)
VAR Result = ( PersonsAtParentLevel = 0 )
RETURNResult

现在我们可以识别叶节点了,最终公式为:
FinalFormula =
-- 判断当前浏览深度是否超出了节点的最大深度加1,如果为 TRUE,表示当前节点的层级太深,不应该显示。
VAR TooDeep = [MaxNodeDepth] + 1 < [BrowseDepth]
-- 判断当前浏览深度是否正好等于节点的最大深度加1,如果为 TRUE,表示当前节点处于一个额外的层级,可能需要特殊处理。
VAR AdditionalLevel = [MaxNodeDepth] + 1 = [BrowseDepth]
VAR Amount = SUM ( Sales[Amount] )
-- 判断当前节点是否有数据(即销售金额是否不为空)
VAR HasData = NOT ISBLANK ( Amount )
-- 判断当前节点是否为叶节点。SELECTEDVALUE 函数确保在没有明确值时返回 FALSE。
VAR Leaf = SELECTEDVALUE ( Persons[IsLeaf], FALSE )
VAR Result =IF (NOT TooDeep,IF ( AdditionalLevel, IF ( NOT Leaf && HasData, Amount ), Amount ))
RETURNResult
- 如果当前节点浏览深度没有超出最大深度加1,则进入下一步判断,否则返回 BLANK()(即隐藏当前节点)。
- 如果当前浏览深度正好等于节点的最大深度加1,进入特殊处理逻辑;否则直接返回 Amount(即显示当前节点的值)。
- 如果当前节点不是叶节点且有数据,则返回 Amount(即显示当前节点的值);否则返回 BLANK()(即隐藏当前节点)。
最终,根据当前节点的层级、是否有数据以及是否为叶节点,动态决定是否显示当前节点的值。
如果模型处于兼容级别 1400,则可以启用名为 “隐藏成员” 的特殊属性的行为。 隐藏成员会自动隐藏空白成员,效果更好,也不用编写上述DAX 代码来隐藏不平衡层级的级别。
十二、表
12.1 CALCULATETABLE
12.1.1 基本语法
CALCULATETABLE是CALCULATE函数的表版本,两者在运行时执行相同的操作,唯一的区别在于CALCULATE返回单个值(标量),而CALCULATETABLE返回一个表。两者的语法如下:
CALCULATE(<expression>[, <filter1> [, <filter2> [, …]]])
CALCULATETABLE(<expression>[, <filter1> [, <filter2> [, …]]])
其中,<expression> 是要计算的表达式,<filter1>, <filter2>, ... 是可选的筛选条件,用于修改筛选上下文。例如,如果需要生成仅包含红色产品的表,可以使用以下表达式:
CALCULATETABLE ('Product','Product'[Color] = "Red"
)
12.1.2 与 FILTER 的区别
上面的表达式也是可以用 FILTER来书写:
FILTER ('Product','Product'[Color] = "Red"
)
虽然 CALCULATETABLE 和 FILTER 在某些情况下看起来很相似,但它们的语义和执行方式截然不同。
| 函数 | 筛选生效阶段 | 上下文影响范围 |
|---|---|---|
CALCULATETABLE | 先应用筛选 → 再计算 | 影响整个表达式内部 |
FILTER | 先计算 → 后过滤结果 | 仅影响最终输出行 |
记忆技巧:
FILTER是"事后筛选",而CALCULATETABLE是"事前筛选"。
Red Products CALCULATETABLE =
CALCULATETABLE (ADDCOLUMNS (VALUES ( 'Product'[Color] ),"Num of Products", COUNTROWS ( 'Product' )),'Product'[Color] = "Red"
)
在这个例子中,CALCULATETABLE 首先改变了筛选上下文,然后再计算表达式,确保COUNTROWS 只计算红色产品的数量。

FILTER是一个迭代函数,其语法为:
FILTER(<table>,<filter>) -- filte是需要逐行计算的布尔表达式
如果用 FILTER 替换 CALCULATETABLE:
Red Products FILTER external =
FILTER (ADDCOLUMNS (VALUES ( 'Product'[Color] ),"Num of Products", COUNTROWS ( 'Product' )),'Product'[Color] = "Red"
)

这等价于:
-- 1. 先执行 ADDCOLUMNS(无筛选)
TempTable =
ADDCOLUMNS (VALUES('Product'[Color]), -- 所有颜色(Red, Blue, Green...)"Num of Products", COUNTROWS('Product') -- 始终=2517(全表计数)
)-- 2. 再执行 FILTER(仅筛选颜色列)
Result =
FILTER (TempTable, -- 包含所有颜色和全表计数的临时表[Color] = "Red" -- 仅保留颜色为 Red 的行
)
也就是说,FILTER先迭代table,再检索能满足条件的行,它不会改变筛选上下文。在本例中,FILTER 函数会先执行 ADDCOLUMNS 函数,此时 ADDCOLUMNS 函数会直接迭代所有的产品,COUNTROWS 函数会计算所有产品的数量。最后,FILTER 函数会从所有颜色中选择一个红色的产品,但此时已经无法改变之前计算出的总数了。
如果需要用 FILTER 实现相同效果,必须 将筛选条件提前到计算前,并通过 CALCULATE 强制上下文转换:
-- 先通过 FILTER 限制颜色为红色,再使用CALCULATE 确保 COUNTROWS 在红色产品的上下文中计算Red Products FILTER internal =
ADDCOLUMNS (FILTER (VALUES ( 'Product'[Color] ),'Product'[Color] = "Red"),"Num of Products",CALCULATE (COUNTROWS ( 'Product' ))
)
12.1.3 CALCULATETABLE 的限制
CALCULATETABLE通常性能更好,因为它直接操作筛选上下文;FILTER需要迭代每一行数据,在大数据量时可能较慢,但是使用CALCULATETABLE也有限制:CALCULATETABLE 只能应用于数据模型中的列,而不能直接对度量值进行筛选,但FILTER 可以。
FILTER 的工作方式是 逐行检查条件,它不修改筛选上下文,而是迭代表(如 Customer 表的每一行),在每一行的上下文中计算度量值(如 [Sales Amount]),最后保留符合条件的行,所以可用于筛选度量值:
-- FILTER 可以正确运行,因为它在每一行计算 [Sales Amount]
LargeCustomers =
FILTER (Customer,[Sales Amount] > 10000 -- 在每一行的上下文中计算
)
而 CALCULATETABLE 无法逐行计算,它只能 预先修改整个表的筛选上下文,比如'Product'[Color] = "Red",只能应用于数据模型中的列(DAX 引擎可以直接修改这些列的筛选上下文)。而度量值(如 [Sales Amount])是动态计算的,没有固定的存储值,每次计算都依赖当前上下文。如果尝试 CALCULATETABLE(Table, [Measure] > 10000),DAX 引擎不知道如何提前应用这个筛选。
-- ❌ 错误!CALCULATETABLE 不能直接筛选度量值
LargeCustomers =
CALCULATETABLE (Customer,[Sales Amount] > 10000 -- 无法直接应用筛选
)
虽然 CALCULATETABLE 不能直接筛选度量值,但可以通过 计算列或变量 间接实现类似效果:
- 创建计算列。缺点是计算列占用存储空间,且不会自动更新。
-- 1. 在 Customer 表中创建计算列 Customer[TotalSales] = [Sales Amount]LargeCustomers = CALCULATETABLE (Customer,Customer[TotalSales] > 10000 -- 现在可以筛选 ) - 使用变量 + FILTER 结合
-- 先计算符合条件的客户列表,再传递给 CALCULATETABLE LargeCustomers = VAR FilteredCustomers = FILTER (Customer,[Sales Amount] > 1000000) RETURNCALCULATETABLE (FilteredCustomers,-- 可以再叠加其他筛选条件Customer[Country] = "USA")
最佳实践:
- 优先使用CALCULATETABLE:需要对模型中的列进行筛选、需要使用上下文转换或改变筛选上下文、需要配合使用ALL、USERELATIONSHIPS、CROSSFILTER等函数时
- 优先使用CALCULATE:动机与CALCULATETABLE完全相同,只是如果期望返回值就用 CALCULATE
- 优先使用FILTER的情况:需要基于度量值进行筛选,或复杂条件筛选
| 对比维度 | CALCULATETABLE | FILTER |
|---|---|---|
| 返回类型 | 返回表 | 返回表 |
| 执行顺序 | 先修改筛选上下文 → 再计算表达式 | 先迭代表 → 再逐行检查条件 |
| 上下文处理 | 会改变筛选上下文 | 保持原始筛选上下文不变 只有需嵌套CALCULATE时才强制转换 上下文 |
| 筛选对象与用途 | 只能筛选模型中的列, 支持ALL/USERELATIONSHIP等上下文修改器 | 可筛选列和度量值 |
| 适用场景 | 需要改变上下文时(如时间智能计算) | 需要复杂逻辑判断时(如动态阈值筛选) |
12.2 使用 ADDCOLUMNS扩展表结构
12.2.1 基本语法与用法
ADDCOLUMNS是一个迭代器函数,它能够在不改变原始表结构的前提下,为表添加新的计算列。这对于在现有数据基础上进行进一步分析非常有用。其语法为:
ADDCOLUMNS(<table>, <name>, <expression>[, <name>, <expression>]…)
例如,我们可以通过 ADDCOLUMNS 为产品表添加销售额列,从而快速生成包含产品颜色和销售额的报表。
ColorsWithSales =
ADDCOLUMNS (VALUES ( 'Product'[Color] ),"Sales Amount", [Sales Amount]
)
注意,这里的列名必须使用双引号,否则报错。表名才可以使用单引号。
在上述代码中,VALUES ( 'Product'[Color] ) 生成了一个包含所有产品颜色的表,而 "Sales Amount", [Sales Amount] 则为每一行添加了一个新的列,显示对应颜色的销售额。这种操作在生成动态报表时非常高效,因为它允许我们在运行时计算并添加新的数据列,而无需修改原始数据模型。
此外,ADDCOLUMNS 还可以与 FILTER 函数结合使用,对临时表进行过滤。例如,筛选出销售额超过 150,000 的产品:
HighSalesProducts =
VAR ProductsWithSales =ADDCOLUMNS (VALUES ( 'Product'[Product Name] ),"Product Sales", [Sales Amount])
VAR Result =FILTER (ProductsWithSales,[Product Sales] >= 150000)
RETURNResult

这种简单场景实际上可以直接使用 FILTER + 度量值筛选解决:
FILTER (
VALUES ( 'Product'[Product Name] ),
[Sales Amount] >= 150000
)
12.2.2 复杂筛选
在复杂场景中,比如计算出销售额累计占比不超过15%的“顶级产品”,就需要多个中间步骤来完成。ADDCOLUMNS 可以逐步构建临时表,在每一步添加必要的列,最终通过逻辑组合解决问题。
- 计算每个产品的销售额(ProductSales列)。
- 计算销售额的累计总和(RunningTotal列)。
- 将累计总和转换为百分比(隐式计算)。
- 筛选满足条件(≤15%)的产品。
在一个步骤中创建完整查询会复杂而且没必要,分为四个步骤逻辑更加清晰:
Top Products =
VAR TotalSales = [Sales Amount] -- 计算总销售额
VAR ProdsWithSales = -- 为每个产品添加销售额列ADDCOLUMNS (VALUES ( 'Product'[Product Name] ),"ProductSales", [Sales Amount])
VAR ProdsWithRT = -- 为每个产品添加运行总计列ADDCOLUMNS (ProdsWithSales,"RunningTotal",VAR SalesOfCurrentProduct = [ProductSales] -- 当前产品的销售额RETURNSUMX (FILTER (ProdsWithSales,[ProductSales] >= SalesOfCurrentProduct -- 筛选销售额大于或等于当前产品的所有产品),[ProductSales] -- 计算这些产品的总销售额))
VAR Top15Percent = -- 筛选出累计占比不超过15%的顶级产品FILTER (ProdsWithRT,[RunningTotal] / TotalSales <= 0.15)
RETURNTop15Percent

最终得到的Top15Percent 是一个计算表,还可以进行进一步的分析,比如使用 SUMX 函数进行迭代 ,计算这些顶级产品的总销售额:
Top15PercentSalesAmount = SUMX ( Top15Percent, [ProductSales] )
“模块化”设计哲学:DAX 的强大之处在于 组合简单函数解决复杂问题。ADDCOLUMNS 是“构建模块”之一,它允许:
- 创建临时计算列(不污染原数据模型)
- 链式依赖计算(后续步骤依赖前一步的结果)。
这种分步方法比强行写一个超长公式更易维护和调试。当你的逻辑无法通过单一度量或简单筛选完成时,可以使用它。注意结合VAR分步存储中间表,避免重复计算。
12.3 使用 SUMMARIZE进行分组与聚合
SUMMARIZE函数用于对数据进行分组和汇总,生成一个新的表,其中包含分组后的聚合结果。其语法为:
SUMMARIZE(<Table>, -- 要进行汇总的表<GroupBy_Expression1>, ..., -- 分组表达式,可以有多个<Name1>, <Expression1>, ... -- 定义新列的名称和表达式,可以有多个[, <Filter_Expression>] -- 可选的过滤表达式
)
SUMMARIZE只返回多列的有效组合,例如以下公式只返回销售表中有销售记录的颜色,而非所有颜色(对比VALUES)。
Num of colors := COUNTROWS (VALUES ( 'Product'[Color] ))
Num of colors sold := COUNTROWS ( SUMMARIZE ( Sales, 'Product'[Color] ) )

SUMMARIZE 支持按多个列进行分组,但需遵循多对一或一对一关系。,例如每个产品每天的平均销售量,未销售日期不会出现在结果中:
AvgDailyQty :=
VAR ProductsDatesWithSales =SUMMARIZE ( Sales, 'Product'[Product Name], 'Date'[Date] )
VAR Result =AVERAGEX ( ProductsDatesWithSales, CALCULATE ( SUM ( Sales[Quantity] ) ) )
RETURNResult

在本例中,我们使用 SUMMARIZE 扫描 Sales 并按产品名称和日期对其进行分组。生成的表包含产品名称和日期,AVERAGEX 负责计算 SUMMARIZE 返回的临时表中的每一行的平均值。
12.4 使用 CROSSJOIN生成笛卡尔积
12.4.1 基本语法
CROSSJOIN 用于返回输入表的所有可能组合(即笛卡尔积),其语法为;
CROSSJOIN(<table>, <table>[, <table>]…)
例如,以下表达式返回产品名称和年份的所有组合,结果是一个新的表:
EVALUATE
CROSSJOIN (ALL ( 'Product'[Category] ),ALL ( 'Date'[Calendar Year] )
)

CROSSJOIN主要用于查询,但在特定情况下,出于性能优化或多表列筛选的的需要,也可用于度量值,下一节将具体说明。
12.4.2 复杂筛选优化(重要)
OR 条件筛选(同表列):在简单场景中,筛选同一表的多个列时,可是使用 SUMMARIZE 生成组合。比如以下公式筛选出“类别=Audio”或“颜色=Black”的产品的销售额。由于Product 表较小,此方式性能较优:
AudioOrBlackSales :=
VAR CategoriesColors =SUMMARIZE ( 'Product', 'Product'[Category], 'Product'[Color] )
-- 产品类别为"Audio"或者产品颜色为"Black"的产品表
VAR AudioOrBlack =FILTER (CategoriesColors,OR ( 'Product'[Category] = "Audio", 'Product'[Color] = "Black" ))
VAR Result =CALCULATE ( [Sales Amount], AudioOrBlack )
RETURNResult如果改成查询,则是:
-- 直接在筛选表的基础上,使用ADDCOLUMNS添加一个[Sales Amount]度量的计算列
-- 新列计算表达式,直接引用度量值,不需要显示书写CALCULATE函数,自动在计算表中进行逐行迭代计算
EVALUATE
VAR CategoriesColors =SUMMARIZE ( 'Product', 'Product'[Category], 'Product'[Color] )
VAR AudioOrBlack =FILTER (CategoriesColors,OR ( 'Product'[Category] = "Audio", 'Product'[Color] = "Black" ))
VAR Result =ADDCOLUMNS ( AudioOrBlack, "Sales Amount", [Sales Amount] )
RETURNResult

OR 条件筛选(跨表列):在复杂场景中,比如筛选来自不同表的列(“类别=Audio”或“年份=CY 2007”),如果还是用 SUMMARIZE,就需要扫描大表 Sales,这种方式效率极低(即使结果很少)。
AudioOr2007 Sales :=
VAR CategoriesYears =SUMMARIZE ( Sales, 'Product'[Category], 'Date'[Calendar Year] )
VAR Audio2007 =FILTER (CategoriesYears,OR ( 'Product'[Category] = "Audio", 'Date'[Calendar Year] = "CY 2007" ))
VAR Result =CALCULATE ( [Sales Amount], Audio2007 )
RETURNResult
如果改用 CROSSJOIN + VALUES 先生成所有有效组合(56行),就可以避免扫描大表,大大优化查询性能:
AudioOr2007 Sales :=
-- 生成所有有效组合,共56行
VAR CategoriesYears =CROSSJOIN ( VALUES ( 'Product'[Category] ), VALUES ( 'Date'[Calendar Year] ) )
-- 筛选出特定组合,共14行
VAR Audio2007 =FILTER (CategoriesYears,OR ( 'Product'[Category] = "Audio", 'Date'[Calendar Year] = "CY 2007" ))
VAR Result =CALCULATE ( [Sales Amount], Audio2007 )
RETURNResult

CROSSJOIN 生成的组合是独立的,不自动关联到 Sales 表,无直接数据沿袭。但在最后计算时, CALCULATE 的筛选器会将 Category 和 Year 的值通过模型关系传递到 Sales(前提是这些列与 Sales 存在多对一关系)。
12.5 使用 UNION合并表
12.5.1 输入表沿袭不同时,合并表失去数据沿袭
UNION用于合并两个表,保留所有行(包括重复项),比如合并客户表和商店表中的国家地区。
AllCountryRegions =
UNION (ALL ( Customer[CountryRegion] ),ALL ( Store[CountryRegion] )
)
如果需要删除重复项,可以使用 DISTINCT 函数,它返回表的不同行。
如果两表沿袭相同,保留输入表沿袭;如果沿袭不同,结果将失去原有沿袭。由于Customer[CountryRegion] 和Store[CountryRegion]的数据沿袭不同,所以CountryRegions表没有数据沿袭,也就无法用于筛选。因此,下面的计算表返回所有行的总销售额:
在 DAX 中,数据沿袭是指筛选器如何从一个表传递到另一个表。这通常通过表之间的关系发生。
DistinctCountryRegions =
VAR CountryRegions =UNION ( ALL ( Customer[CountryRegion] ), ALL ( Store[CountryRegion] ) )
VAR UniqueCountryRegions =DISTINCT ( CountryRegions )
VAR Result =ADDCOLUMNS ( UniqueCountryRegions, "Sales Amount", [Sales Amount] )
RETURNResult

如果在此基础上,需要同时计算销售额和商店数量,那么情况更加复杂。
12.5.2 对策一:直接筛选(手动处理沿袭)
通过 ADDCOLUMNS 迭代合并后的国家列表,在每行中动态筛选原表数据。使用变量 CurrentRegion 捕获当前行的国家名称,显式传递给 CALCULATE 筛选条件。这种方式需要为每列单独编写筛选逻辑。
DistinctCountryRegions =
VAR CountryRegions =UNION ( ALL ( Customer[CountryRegion] ), ALL ( Store[CountryRegion] ) )
VAR UniqueCountryRegions =DISTINCT ( CountryRegions )
VAR Result =ADDCOLUMNS (UniqueCountryRegions,"Customer Sales Amount",VAR CurrentRegion = [CountryRegion]RETURNCALCULATE ( [Sales Amount], Customer[CountryRegion] = CurrentRegion ), -- 直接筛选 Customer 表"Number of stores",VAR CurrentRegion = [CountryRegion]RETURNCALCULATE ( COUNTROWS ( Store ), Store[CountryRegion] = CurrentRegion ) -- 直接筛选 Store 表)
RETURNResult

12.5.3 使用 TREATAS 恢复沿袭
利用 TREATAS 将合并后的国家列表的沿袭绑定到目标列。此方式代码更简洁,避免重复编写筛选逻辑。要注意的是,TREATAS 会自动忽略目标列中不存在的值。
DistinctCountryRegions =
VAR CountryRegions =UNION ( ALL ( Customer[CountryRegion] ), ALL ( Store[CountryRegion] ) )
VAR UniqueCountryRegions =DISTINCT ( CountryRegions )
VAR Result =ADDCOLUMNS (UniqueCountryRegions,"Customer Sales Amount",CALCULATE ([Sales Amount],TREATAS ( { [CountryRegion] }, Customer[CountryRegion] )),"Number of stores",CALCULATE (COUNTROWS ( Store ),TREATAS ( { [CountryRegion] }, Store[CountryRegion] )))
RETURNResult

12.6 使用 INTERSECT求交集
12.6.1 数据沿袭问题
INTERSECT 用于求两个表的交集(共有的行), 在处理数据沿袭时会保留第一个表的数据沿袭。比如计算“既有客户又有商店的国家”的销售额时,所以以下代码只会返回由 Store[CountryRegion] 筛选的销售额,而不是 Customer[CountryRegion] :
EVALUATE
VAR CountriesWithStoresAndCustomers =INTERSECT (ALL ( Store[CountryRegion] ),ALL ( Customer[CountryRegion] ))
VAR Result =ADDCOLUMNS (CountriesWithStoresAndCustomers,"StoresSales", [Sales Amount])
RETURNResult

12.6.2 推荐使用TREATAS
INTERSECT的限制:
- 数据沿袭问题:计算结果会保留第一个表的沿袭,这意味着:如果两个输入表的沿袭不同,结果可能无法正确筛选目标表。
- INTERSECT 要求两个表的列结构完全一致,否则会报错。这在跨表计算时限制较大。
- INTERSECT 是静态的集合运算,无法灵活适应动态筛选上下文(如时间智能计算)。
相反,TREATAS 是一种更灵活的筛选方式,它显式建立虚拟关系,不受数据沿袭限制,适用于更多场景:
-
不依赖原始沿袭:TREATAS 可以强制将一列的值映射到另一列,即使它们原本没有关系
-
TREATAS 不要求列名相同,只需数据类型匹配:
-- 将 Product[Name] 的值映射到 Sales[ProductKey] 的筛选 TREATAS ( VALUES(Product[Name]), Sales[ProductKey] ) -
TREATAS 可以结合 CALCULATE 动态调整筛选逻辑,而 INTERSECT 是静态的:
-- 动态计算去年和今年都购买的客户 VAR CustomersLastYear = CALCULATETABLE(VALUES(Sales[CustomerKey]), DATEADD('Date'[Date], -1, YEAR)) VAR CustomersThisYear = VALUES(Sales[CustomerKey]) RETURNCALCULATE([Sales Amount],TREATAS(CustomersLastYear, Sales[CustomerKey]), // 动态筛选CustomersThisYear)
12.7 使用 EXCEPT求差集
EXCEPT返回表1中存在但表2中不存在的行(集合减法),并保留第一个表的数据沿袭。其语法为:
EXCEPT (<table1>, <table2>)
应用场景一:统计在2007年购买且2008年未购买的客户
CustomersBuyingIn2007butNotIn2008 =
VAR Customers2007 =CALCULATETABLE (SUMMARIZE ( Sales, Customer[Customer Code] ),'Date'[Calendar Year] = "CY 2007")
VAR Customers2008 =CALCULATETABLE (SUMMARIZE ( Sales, Customer[Customer Code] ),'Date'[Calendar Year] = "CY 2008")
VAR Result =EXCEPT ( Customers2007, Customers2008 )
RETURNResult
应用场景二:统计新客户销售总额(去年未购买,今年购买):
SalesOfNewCustomers :=
-- 获取当前时间段内所有有购买记录的客户列表
VAR CurrentCustomers = VALUES ( Sales[CustomerKey] )
-- 获取去年(当前时间段之前一年)所有有购买记录的客户列表
VAR CustomersLastYear =CALCULATETABLE (VALUES ( Sales[CustomerKey] ), DATESINPERIOD ( 'Date'[Date], MIN ( 'Date'[Date] ) - 1, -1, YEAR ) )
-- 找出在当前时间段内有购买记录,但在去年没有购买记录的客户(即新客户)
VAR CustomersNotInLastYear =EXCEPT ( CurrentCustomers, CustomersLastYear )
VAR Result =CALCULATE ( [Sales Amount], CustomersNotInLastYear )
RETURNResult

上述实现方法灵活且易于理解,用于任何筛选器,可以按任何列切片,但在性能上可能不是最优的,下一节会介绍优化方法。
应用场景三:计算无门店国家的客户销售额:
SalesInCountriesWithNoStores :=
-- 通过 CALCULATETABLE 和 SUMMARIZE 函数,获取有门店的国家。
VAR CountriesWithActiveStores =CALCULATETABLE ( SUMMARIZE ( Sales, Store[CountryRegion] ), ALL ( Sales ) )
-- 通过 SUMMARIZE 函数,获取有销售记录的国家。
VAR CountriesWithSales =SUMMARIZE ( Sales, Customer[CountryRegion] )
-- 使用 EXCEPT 函数,从有销售记录的国家中剔除有门店的国家,得到无门店国家。
VAR CountriesWithNoStores =EXCEPT ( CountriesWithSales, CountriesWithActiveStores )
-- 计算无门店国家的销售额。
VAR Result =CALCULATE ( [Sales Amount], CountriesWithNoStores )
RETURNResult

| 函数 | 功能描述 | 沿袭规则 | 典型应用场景 |
|---|---|---|---|
| UNION | 合并两个表的所有行 | 保留第一个表的沿袭 | 合并不同来源的同类数据 |
| INTERSECT | 返回两个表共有的行 | 保留第一个表的沿袭 | 找出同时满足两个条件的客户 |
| EXCEPT | 返回表1有但表2没有的行 | 保留第一个表的沿袭 | 计算流失客户、新增客户等 |
12.8 用表做筛选
12.8.1 OR筛选
在 Power BI 等工具中,默认的筛选器行为是“与”(AND)条件,比如报表中不同切片器的选择,最终取的是交集而非并集。下图展示的是销售给高中的家用电器的销售额。

如果想实现OR筛选(销售给高中或家用电器的销售额),有多种方法。
12.8.1.1 使用 CROSSJOIN 生成所有可能的组合
第一个方法是通过 CROSSJOIN 生成所有可能的组合,然后使用 FILTER 函数筛选出满足条件的组合。
OR 1 :=
VAR CategoriesEducations =CROSSJOIN ( ALL ( 'Product'[Category] ), ALL ( Customer[Education] ) )
VAR CategoriesEducationsSelected =FILTER (CategoriesEducations,OR ('Product'[Category] IN VALUES ( 'Product'[Category] ),Customer[Education] IN VALUES ( Customer[Education] )))
VAR Result =CALCULATE ( [Sales Amount], CategoriesEducationsSelected )
RETURNResult

12.8.1.2 使用 SUMMARIZE 生成有效组合
当筛选条件的列中存在大量行时,CROSSJOIN 生成的临时表可能会非常大,从而影响性能。此时,可以使用 SUMMARIZE 来优化。SUMMARIZE 会根据指定的列生成一个汇总表,避免了不必要的组合。
OR 2 :=
VAR CategoriesEducations =CALCULATETABLE (SUMMARIZE ( Sales, 'Product'[Category], Customer[Education] ),ALL ( 'Product'[Category] ),ALL ( Customer[Education] ))
VAR CategoriesEducationsSelected =FILTER (CategoriesEducations,OR ('Product'[Category] IN VALUES ( 'Product'[Category] ),Customer[Education] IN VALUES ( Customer[Education] )))
VAR Result =CALCULATE ( [Sales Amount], CategoriesEducationsSelected )
RETURNResult
此代码和第一个代码唯一明显的区别是 SUMMARIZE 替代了 CROSSJOIN 。此外,SUMMARIZE 需要在筛选上下文中执行( CALCULATETABLE函数),而不需要在 Category 和 Education 上进行过滤。否则,切片器会影响SUMMARIZE 执行的计算,从而破坏筛选的效果。
12.8.1.3 使用 UNION 进一步优化
在默认的“与”(AND)条件下,只有同时满足两个条件的记录才会被筛选出来。如果要实现“或”(OR)条件,就需要重新设计筛选逻辑。
- 条件 1 的扩展:如果产品类别属于选定的类别值,那么无论客户教育水平是什么,都应该被选中。
- 条件 2 的扩展:如果客户教育水平属于选定的教育水平值,那么无论产品类别是什么,都应该被选中。
换句话说,我们可以将问题分解为两个独立的筛选条件(两个筛选表),然后将它们的结果合并起来。UNION 函数会自动去除重复的行,最终得到的结果就是满足任一条件的记录集合。
OR 3 :=
-- 表 1:包含所有选定类别值的记录,忽略教育水平。
VAR Categories =CROSSJOIN ( VALUES ( 'Product'[Category] ), ALL ( Customer[Education] ) )
-- 表 2:包含所有选定教育水平值的记录,忽略产品类别。
VAR Educations =CROSSJOIN ( ALL ( 'Product'[Category] ), VALUES ( Customer[Education] ) )
VAR CategoriesEducationsSelected =UNION ( Categories, Educations )
VAR Result =CALCULATE ( [Sales Amount], CategoriesEducationsSelected )
RETURNResult
| 方法 | 临时表大小 | 计算复杂度 |
|---|---|---|
CROSSJOIN + FILTER | 生成所有可能组合的临时表,大小为两个维度的乘积,占用大量内存 | 对临时表进行FILTER筛选,计算复杂度较高 |
SUMMARIZE + FILTER | 生成有效组合的汇总表,临时表仍较大 | 同上 |
UNION | 分别生成两个较小的表,再通过UNION合并,避免生成庞大的临时表 | 不用使用FILTER筛选,计算复杂度更低 |
12.8.2 时间维度计算
12.8.2.1 计算客户生命周期价值(LTV)
下一个示例是在计算那些在第一年购买产品的客户,在后续年份的销售额。此指标的意义在于追踪 客户群体的留存和生命周期价值(LTV)。
SalesOfFirstYearCustomers :=
-- 使用 FIRSTNONBLANK 函数找到任何产品销售的第一年
VAR FirstYearWithSales =CALCULATETABLE (FIRSTNONBLANK ( 'Date'[Calendar Year], [Sales Amount] ),ALLSELECTED ())
-- 找到在第一年有购买记录的所有客户(CustomerKey)。
VAR CustomersFirstYear =CALCULATETABLE (VALUES ( Sales[CustomerKey] ),FirstYearWithSales,ALLSELECTED ())
-- 计算这些“第一年客户”在后续年份的销售额。KEEPFILTERS 确保在计算时,只考虑第一年客户群体,而忽略其他客户。
VAR Result =CALCULATE ( [Sales Amount], KEEPFILTERS ( CustomersFirstYear ) )
RETURNResult
假设数据如下,此度量值计算结果为:
| 年份 | 活跃客户 | 新增客户 | 总销售额 | 度量值结果(仅第一年客户销售额) |
|---|---|---|---|---|
| 2019 | A, B, C | - | 100万 | 100万(全部为第一年客户) |
| 2020 | A, B, D | D | 80万 | 80万(仅A、B,忽略D) |
| 2021 | A, E | E | 30万 | 30万(仅A,忽略E) |
客户生命周期价值(LTV),用于识别高价值客户群体(第一年客户)的长期贡献,分析客户的忠诚度或流失率。如果销售额逐年下降(如下图所示),说明客户复购率低或流失严重:

进一步分析:
- 对比不同获客渠道的第一年客户在后续的留存表现。
- 分群分析:按客户属性(如地区、渠道)分组,观察不同群体的留存差异。
- 加入时间衰减模型:计算客户留存率或回购周期。
- 对比新老客户贡献:新增一个度量值计算“非第一年客户”的销售额,与现有结果对比。
12.8.2.2 计算新客户
上一节使用EXCEPT 函数计算新客户,是分别建立所有有购买记录的客户列表,以及去年(当前时间段之前一年)的客户列表。二者的差集,就是新客户列表(最近一年才购买产品)。
另一种实现逻辑是,先计算每个客户首次购买产品的日期,然后从中筛选出新客户。
New Customers :=
-- 获取每个客户的首次购买日期
VAR CustomersFirstSale =CALCULATETABLE (ADDCOLUMNS (VALUES ( Sales[CustomerKey] ),"FirstSale", CALCULATE ( MIN ( Sales[Order Date] ) )),ALL ( 'Date' ))
-- 筛选出首次购买日期在当前时间段内的客户,即为新客户
VAR CustomersWith1stSaleInCurrentPeriod =FILTER ( CustomersFirstSale, [FirstSale] IN VALUES ( 'Date'[Date] ) )
VAR Result =COUNTROWS ( CustomersWith1stSaleInCurrentPeriod )
RETURNResult

New Customers 的计算逻辑可以根据用户在报表中应用的其他筛选器(如产品类别、商店等)动态调整,即“新客户”的定义可以根据上下文变化。这意味着同一个客户可能在不同筛选条件下被多次计为新客户(例如首次购买A品类时算新客户,首次购买B品类时又算一次)。
为了避免此情况,可以通过在第一个变量中添加不同的CALCULATE修饰符,改变"新客户"的定义:
- 添加ALL(Product) - 客户只在首次购买(任何产品)时被视为新客户
- 添加ALL(Store) - 客户只在首次购买(任何商店)时被视为新客户
这是一个动态的新客户计算模型,其行为取决于筛选上下文和ALL修饰符的使用方式,可以根据业务需求灵活调整新客户的定义标准。
12.8.3 使用 IN、CONTAINSROW 和 CONTAINS
IN、CONTAINSROW 和 CONTAINS 是用于检查表中是否存在特定值的函数。IN 是最直观和性能最优的选择,在内部,IN 被转换为CONTAINSROW 函数调用,因此两种语法之间的性能没有差异:
Product[Color] IN { "Red", "Blue", "Yellow" }
CONTAINSROW ( { "Red", "Blue", "Yellow" }, Product[Color] )
还可以进行多列判定:
( 'Date'[Year], 'Date'[MonthNumber] ) IN { ( 2018, 12 ), ( 2019, 1 ) }CONTAINSROW ( { ( 2018, 12 ), ( 2019, 1 ) },'Date'[Year],'Date'[MonthNumber] )
在某些旧版本的 DAX 中这两个函数可能不可用,只能使用 CONTAINS,其效率效率低于 IN 和 CONTAINSROW:
VAR Colors =UNION (ROW ( "Color", "Red" ),ROW ( "Color", "Blue" ),ROW ( "Color", "Yellow" ))
RETURNCONTAINS ( Colors, [Color], Product[Color] )
12.8.4 使用 DETAILROWS 实现表表达式的复用(略)
12.9 创建计算表
表构造函数{}和 SELECTCOLUMNS比较实用;ROW,DATATABLE 这两个函数已经用的很少了。
12.9.1 SELECTCOLUMNS
SELECTCOLUMNS 函数是 DAX 中用于减少表中列数并添加新列的工具。它类似于 SQL 中的 SELECT 语句,能够从现有表中选择特定的列(会包含重复值),并可以对这些列进行重命名或计算新值,其语法如下:
SELECTCOLUMNS (<Table>,<Name1>, <Expression1>, -- 新列的名称及生成表达式[<Name2>, <Expression2>],...
)
假设我们有一个名为 Customer 的表,包含 Education 和 Gender 列。使用SELECTCOLUMNS可以仅返回这两列,同时添加一个新列 Customer(由 Name 和 Customer Code 拼接而成)
SELECTCOLUMNS (Customer,"Education", Customer[Education],"Gender", Customer[Gender],"Customer",Customer[Name] & " (" & Customer[Customer Code] & ")"
)

SELECTCOLUMNS 在处理数据沿袭时有特殊行为。如果表达式是单列引用,则维护数据沿袭;如果使用表达式,则生成新的数据沿袭。例如:
-- 第一列具有 Customer[Name] 的数据沿袭,而第二列则没有
SELECTCOLUMNS (Customer,"Customer Name with lineage", Customer[Name],"Customer Name without lineage",Customer[Name] & ""
)
12.9.2 用 ROW 创建单行静态表
ROW 函数用于创建一个只有一行的表。它的语法如下:
ROW (<Name1>, <Expression1>, -- 列名与列值表达式[<Name2>, <Expression2>],...
)
比如以下表达式创建一个包含两列的表,分别表示销售额和销售数量:
ROW ("Sales", [Sales Amount],"Quantity", SUM ( Sales[Quantity] )
)
上述功能也可以使用表构造函数{}来实现。在使用表构造函数语法时,行之间需要用逗号分隔。如果需要包含多个列,则必须使用括号将这些列封装在同一行中。
{( [Sales Amount], SUM ( Sales[Quantity] ) )
}
二者区别在于:ROW 函数需要显式指定列的名称,而花括号语法会自动生成列的名称。由于花括号语法生成的列名是自动生成的,这可能会导致在后续引用列值时变得不够直观和方便。
12.9.3 使用 DATATABLE 创建多行静态表
DATATABLE 函数用于创建多行表。它允许指定列名、数据类型和每行的内容。语法如下:
DATATABLE (<ColumnName1>, <DataType1>,<ColumnName2>, <DataType2>,...,{{ <Value1>, <Value2>, ... },{ <Value1>, <Value2>, ... },...}
)
<ColumnName> 是列的名称,<DataType> 是列的数据类型,可以是 INTEGER、DOUBLE、STRING、BOOLEAN、CURRENCY 或 DATETIME。{} 内是表的内容,每行用 {} 包裹。DATATABLE 的一个主要限制是表的内容必须是常量值,不能使用 DAX 表达式,这使得它在某些场景下的应用受到限制。表构造函数更具表达力。
可以使用 DATATABLE 来定义简单,常量的计算表。以下表达式创建一个包含三行的表,用于聚类价格:
DATATABLE ("Segment", STRING,"Min", DOUBLE,"Max", DOUBLE,{{ "LOW", 0, 20 },{ "MEDIUM", 20, 50 },{ "HIGH", 50, 99 }}
)

12.9.4 使用 GENERATESERIES 创建序列表
12.9.4.1 基本语法与用法
GENERATESERIES 函数用于生成一个列表。它需要三个参数:初始值,结束值和步长(默认为1),语法如下:
GENERATESERIES (<StartValue>,<EndValue>,[<Step>]
)
生成的结果取决于输入值,可以是数字或日期时间。比如以下表达式生成一个从 1 到 20 的数字序列:
GENERATESERIES ( 1, 20, 1 )
以下表达式生成一个包含当天每秒时间的表:
Time =
GENERATESERIES (TIME ( 0, 0, 0 ), -- Start valueTIME ( 23, 59, 59 ), -- End valueTIME ( 0, 1, 0 ) -- Step: 1 second
)
通过调整步长,可以生成更粗粒度的时间表,还可以添加格式化的时间列:
Time =
SELECTCOLUMNS (GENERATESERIES ( TIME ( 0, 0, 0 ), TIME ( 23, 59, 59 ), TIME ( 0, 30, 0 ) ),"Time", [Value],"HH:MM AMPM", FORMAT ( [Value], "HH:MM AM/PM" ),"HH:MM", FORMAT ( [Value], "HH:MM" ),"Hour", HOUR ( [Value] ),"Minute", MINUTE ( [Value] )
)

12.9.4.2 使用场景
GENERATESERIES 生成的表可以作为数据模型中的一个独立表,主要用途有:
- 参数化选择:将其将其作为切片器的来源,从而动态地影响报告中的其他可视化内容;
- X 轴数据:生成一个时间序列或数字序列,用作图表的 X 轴数据
- 构造一列数:生成一个数字序列,用于计算或显示特定的数值范围
- 测试生成随机数据:你可以生成一个数字序列或时间序列,然后基于这些序列测试其他计算逻辑。