PyTorch 入门学习笔记
一、简介
PyTorch 是由 Meta(原 Facebook) 开源的深度学习框架。其前身 Torch 是一个基于 LuaJIT 的科学计算框架,核心功能是提供高效的张量(Tensor)操作和神经网络支持。由于 Lua 语言的生态限制,Torch 逐渐被 Google 的 TensorFlow 等框架取代。2016年,Meta 的 AI 研究团队基于 Torch 的核心设计理念,使用 Python 重构了动态计算图架构,并创新性地实现了自动微分系统(Autograd),最终发布了 PyTorch。如今 PyTorch 已成为最主流的 AI 框架之一。
二、安装
1 首先,确保已安装 python 和 pip,并且版本满足 PyTorch 的要求。最新版本的 PyTorch 需要 Python 3.9 及更高版本。
python --version pip --version2 使用 pip 安装 pytorch:
pip3 install torch torchvision
3 测试是否安装成功,将这段代码存储到 test.py 文件里,在终端运行 python3 test.py 查看是否正常运行并输出内容。
import torchprint("PyTorch version:", torch.__version__)
x = torch.rand(5, 3)
print("Random tensor:", x)三、概念
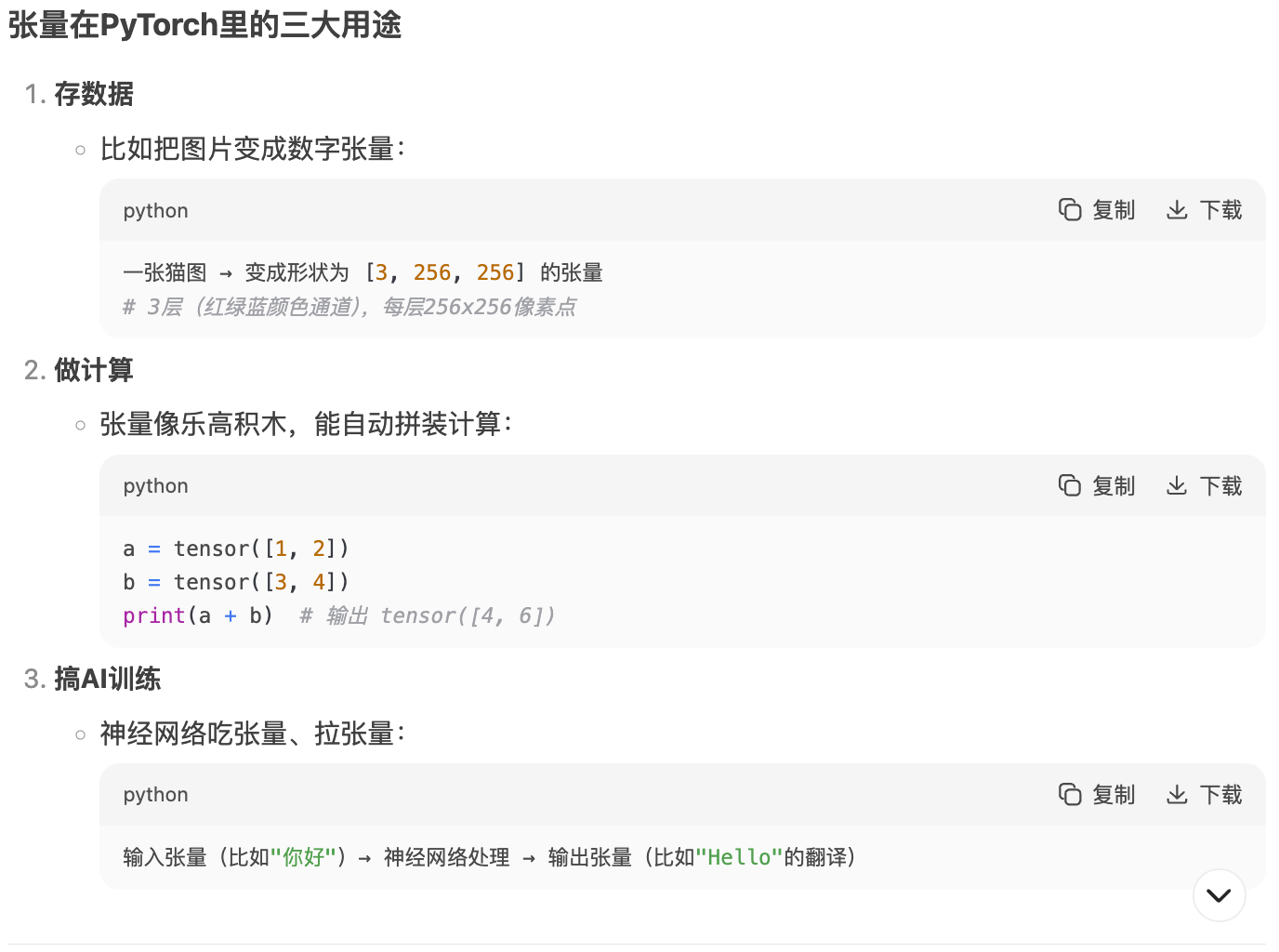
1 张量(Tensor)
PyTorch 中的核心数据结构,用于存储和操作多维数组。在 PyTorch 中,张量的概念类似于 NumPy 中的数组,但是 PyTorch 的张量可以运行在不同的设备上,比如 CPU 和 GPU,这使得它们非常适合于进行大规模并行计算,特别是在深度学习领域。
- 维度(Dimensionality)指数据的多维数组结构。例如,一个标量(0维张量)是一个单独的数字,一个向量(1维张量)是一个一维数组,一个矩阵(2维张量)是一个二维数组,以此类推。
- 形状(Shape)指每个维度上的大小。例如,一个形状为(3, 4)的张量意味着它有3行4列。
- 数据类型(Dtype)定义了存储每个元素所需的内存大小和解释方式。PyTorch 支持多种数据类型,包括整数型(如torch.int8、torch.int32)、浮点型(如torch.float32、torch.float64)和布尔型(torch.bool)。
import torch# 创建一个2x3的全0张量
a = torch.zeros(2, 3)
print(a)# 创建一个2x3的全1张量
b = torch.ones(2, 3)
print(b)# 创建一个2x3的随机数张量
c = torch.randn(2, 3)
print(c)# 从 NumPy 数组创建张量
import numpy as np
numpy_array = np.array([[1, 2], [3, 4]])
tensor_from_numpy = torch.from_numpy(numpy_array)
print(tensor_from_numpy)# 在指定设备(CPU/GPU)上创建张量
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
d = torch.randn(2, 3, device=device) print(d)输出结果:

再通俗一点的理解:


2 梯度和自动微分

import torch# 创建一个需要梯度的张量
# requires_grad=True 表示需要自动计算该张量的梯度(类似"请跟踪我的变化"标签)
x = torch.tensor([1.0], requires_grad=True)# 定义计算图:y = (x + 2)^2
# PyTorch 会自动跟踪所有涉及 x 的操作(相当于用荧光笔标记计算路径)
y = (x + 2) ** 2# 反向传播计算梯度
# 对于标量 y,不需要传入梯度参数(默认为1.0)
# 计算过程:dy/dx = 2*(x+2),当 x=1 时,dy/dx=2*(1+2)=6
y.backward()# 输出 x 的梯度,注意 x.grad 会累积梯度,重复计算时需要清零
print(x.grad) # 输出:tensor([6.])对于梯度的理解,可参考下面两个例子:
- 梯度=8 表示:「增大x会使y剧烈上升」
- 梯度=0.01 表示:「x对y几乎没影响」
3 自动求导(Autograd)
PyTorch 提供了自动求导功能,通过 autograd 模块来自动计算梯度。
在深度学习中,自动求导主要用于两个方面:一是在训练神经网络时计算梯度,二是进行反向传播算法的实现。
自动求导基于链式法则(Chain Rule),这是一个用于计算复杂函数导数的数学法则。链式法则表明,复合函数的导数是其各个组成部分导数的乘积。在深度学习中,模型通常是由许多层组成的复杂函数,自动求导能够高效地计算这些层的梯度。
自动求导和自动微分实际上是同一个概念的不同表述。自动求导是自动微分的一种实现方式,用于计算梯度,从而支持反向传播和模型参数的更新。
动态图与静态图:动态图(Dynamic Graph):在动态图中,计算图在运行时动态构建。每次执行操作时,计算图都会更新,这使得调试和修改模型变得更加容易。PyTorch 使用的是动态图。静态图(Static Graph):在静态图中,计算图在开始执行之前构建完成,并且不会改变。TensorFlow 最初使用的是静态图,但后来也支持动态图。
反向传播(Backpropagation):一旦定义了计算图,可以通过 .backward() 方法来计算梯度。
如果你不希望某些张量的梯度被计算(例如,当你不需要反向传播时),可以使用 torch.no_grad() 或设置 requires_grad=False。
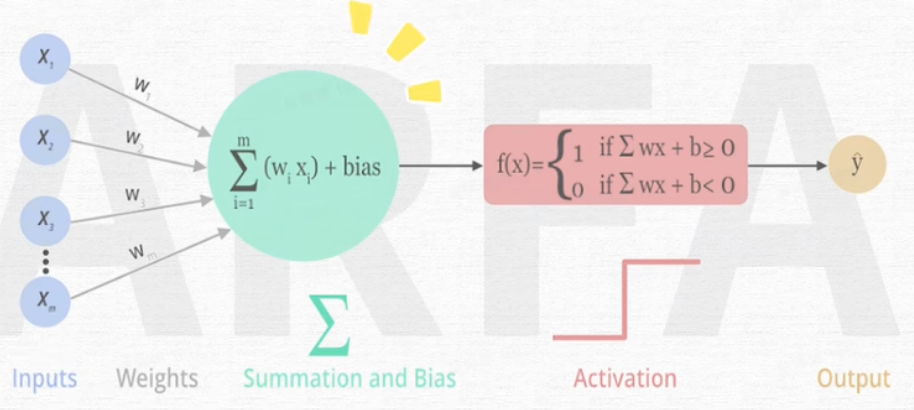
4 神经网络(nn.Module)
神经网络是一种模仿人脑神经元连接的计算模型,由多层节点(神经元)组成,用于学习数据之间的复杂模式和关系。神经网络通过调整神经元之间的连接权重来优化预测结果,这一过程涉及前向传播、损失计算、反向传播和参数更新。神经网络的类型包括前馈神经网络、卷积神经网络(CNN)、循环神经网络(RNN)和长短期记忆网络(LSTM),它们在图像识别、语音处理、自然语言处理等多个领域都有广泛应用。
PyTorch 提供了一个非常方便的接口来构建神经网络模型,即 torch.nn.Module。
我们可以继承 nn.Module 类并定义自己的网络层。
创建一个简单的神经网络:
import torch.nn as nn
import torch.optim as optim# 定义一个简单的全连接神经网络
class SimpleNN(nn.Module):def __init__(self):super(SimpleNN, self).__init__()self.fc1 = nn.Linear(2, 2) # 输入层到隐藏层self.fc2 = nn.Linear(2, 1) # 隐藏层到输出层def forward(self, x):x = torch.relu(self.fc1(x)) # ReLU 激活函数x = self.fc2(x)return x# 创建网络实例
model = SimpleNN()# 打印模型结构
print(model)训练过程
1)前向传播(Forward Propagation): 在前向传播阶段,输入数据通过网络层传递,每层应用权重和激活函数,直到产生输出。
2)计算损失(Calculate Loss): 根据网络的输出和真实标签,计算损失函数的值。
3)反向传播(Backpropagation): 反向传播利用自动求导技术计算损失函数关于每个参数的梯度。
4)参数更新(Parameter Update): 使用优化器根据梯度更新网络的权重和偏置。
5)迭代(Iteration): 重复上述过程,直到模型在训练数据上的性能达到满意的水平。
总体:
Pythorch 解题思路(五步解题法):准备数据、定义模型、训练模型、评估模型、做出预测。
关于训练集和测试集,可以这样通俗地理解:

代码实例:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset# 创建一些随机数据作为示例
inputs = torch.randn(100, 10) # 100个样本,每个样本10个特征
labels = torch.randint(0, 2, (100,)) # 100个样本的标签,0或1# 创建数据集和数据加载器
dataset = TensorDataset(inputs, labels)
dataloader = DataLoader(dataset, batch_size=10, shuffle=True)# 定义一个简单的神经网络
class SimpleNN(nn.Module):def __init__(self):super(SimpleNN, self).__init__()self.fc1 = nn.Linear(10, 50) # 输入层到隐藏层self.fc2 = nn.Linear(50, 2) # 隐藏层到输出层def forward(self, x):x = torch.relu(self.fc1(x)) # 激活函数x = self.fc2(x)return x# 实例化模型、定义损失函数和优化器
model = SimpleNN()
criterion = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = optim.SGD(model.parameters(), lr=0.01) # 随机梯度下降# 训练模型
num_epochs = 10
for epoch in range(num_epochs):model.train() # 设置模型为训练模式running_loss = 0.0for inputs, labels in dataloader:optimizer.zero_grad() # 清空梯度outputs = model(inputs) # 前向传播loss = criterion(outputs, labels) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数running_loss += loss.item()print(f"Epoch {epoch+1}, Loss: {running_loss/len(dataloader)}")# 评估模型(这里简单使用训练数据作为示例)
model.eval() # 设置模型为评估模式
correct = 0
total = 0
with torch.no_grad(): # 禁用梯度计算for inputs, labels in dataloader:outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()
print(f"Accuracy: {100 * correct / total}%")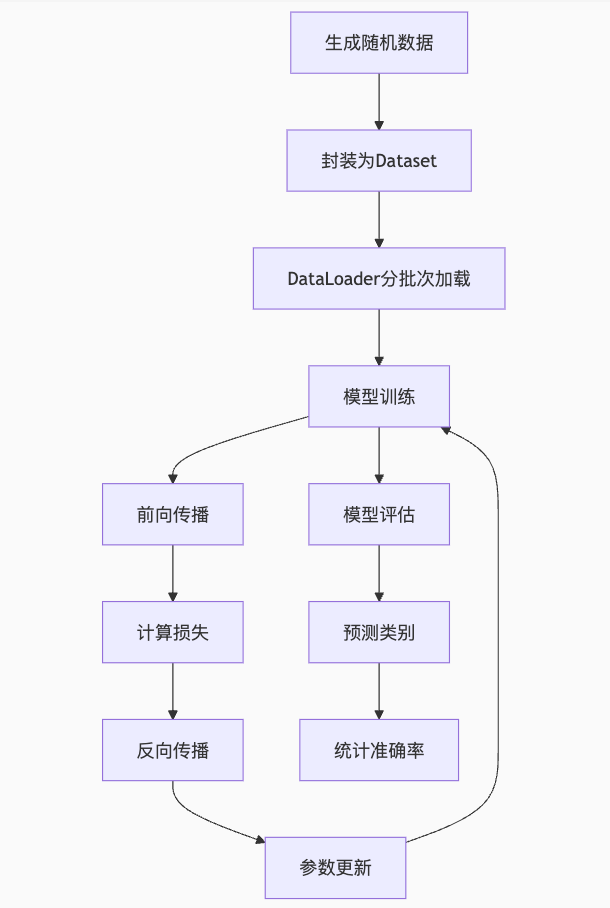
关于向前传播和向后传播的通俗理解:


