UDP数据报
学习网络协议,主要就是在学习协议格式
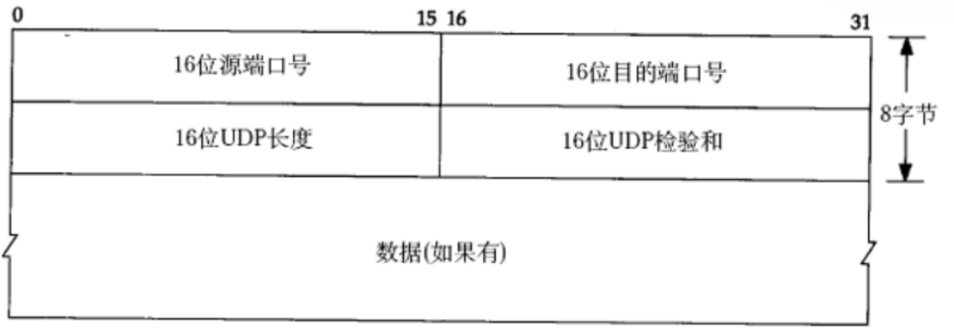
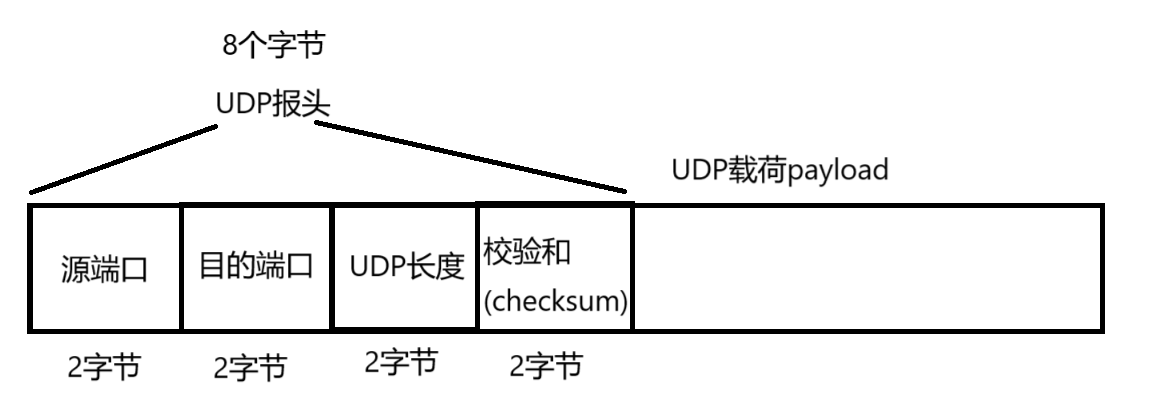
端口号是一个整数,1个字节,无符号(不分正负) 0 - 65535
网络协议,是有专门的组织来负责制定标准的
此处的长度是 2 个字节,表示的数据范围就是 0 - 65535 => 64kb
一个UDP数据报,最大的长度就是 64 kb
如果需要传输比较大的数据,就有可能装不下
放到 30 年前,当时的计算机,内存也就 1MB,此时的 64 KB 非常庞大
但是放到现在已经是不够用了
为什么 大佬们不把 UDP 协议扩充一下?
在技术上来说,该一下格式就可以,两个字节变成四个字节...
但是在具体落实的时候,就是非常困难的
通信双方的设备,都得一起升级才有效
这个实施起来是非常困难的,世界上任意两个设备之间都有可能使用 UDP 进行通信
一旦升级,一定会出现,一部分是设备是新版本,一部分设备是旧版本的情况
新版设备和旧版设备之间就无法完成正常的通信了,造成的结果是难以估量的
协议标准升级好,协议的具体实现,是在各个操作系统厂商手中的,需要这些厂商的配合你升级
可见短期之内,UDP 都很难得到升级
相比于升级 UDP 不如搞一个新的协议代替 UDP 可能是成本更低的做法
64KB 上线很快就要达到了
1.应用层,对数据进行拆分(没采用,开发量很大)
拆成多个之后,如果其中一部分丢包了怎么办?
如果其中某个部分出错了怎么办?
如果发送顺序和接受顺序不一样怎么办,接受方如何重组?
2.换成 TCP 协议(没有明确的上限)
校验和:验证 UDP 数据报是否在传输的过程中出错
网络数据包传输是否会出错??肯定会
比特翻转(1 -> 0, 0 -> 1)
本质上是 电信号/光信号/电磁波
概率性事件
比特翻转,客观存在的
无法 100% 避免,只能甄别出,当前的数据是否出错的
校验和,就是用来甄别数据是否出错的有效方案
发送方,构造 UDP 数据报,构造完成之后,把数据报的每个字节的数据,都进行累加,结果累加到一个 16 位的整数上,溢出,就溢出此时得到的结果,就是校验和(check1),填充到 UDP 报头和字段
接收方收到 UDP 数据报之后,就会按照相同的算法,在计算一遍校验和(check2)
接收方就可以比较 check1 == check2 如果相对,就可以视为数据在传输的过程中是没有出错的
如果不相等,就说明数据在传输的过程中出错了
如果发送的数据和接受的数据,每一个字节都是一致的,计算得到的校验和就一定是一致的
反之,发现校验和不一样,就意味着一定是数据在传输的过程中发生了比特翻转 出现了问题
虽然不知道是哪个比特位发生了翻转,但是可以知道 出错/没出错,如果出错了就把数据丢弃掉就可以
CRC 校验和(循环冗余校验)
是否存在极端情况
恰好是两个 比特位 发生翻转,导致翻转后算出来的校验和和翻转前的算出来的校验和碰巧是一样的呢?
这种情况,理论上是存在的,实践中,概率非常小,忽略不计
如果对于是准确度要求非常高的场景,是有其他的算法的