【Doris基础】Apache Doris中FE和BE的职责详解
目录
1 Doris简介
2 Doris架构概述
3 Frontend(FE)职责详解
3.1 FE核心功能
3.2 FE组件架构
3.3 FE详细职责解析
3.3.1 元数据管理
3.3.2 查询处理流程
3.3.3 集群管理
3.3.4 数据导入管理
4 Backend(BE)职责详解
4.1 BE核心功能
4.2 BE组件架构
4.3 BE详细职责解析
4.3.1 数据存储模型
4.3.2 查询执行流程
4.3.3 数据导入处理
4.3.4 数据压缩与合并
5 FE与BE的协同工作机制
5.1 查询处理的完整流程
5.2 数据导入的协同流程
5.3 故障恢复协同
6 总结
1 Doris简介
Apache Doris(原百度Palo)是一个现代化的MPP(大规模并行处理)分析型数据库,专为实时分析和大规模数据仓库场景设计。Doris采用分布式架构设计,主要由两个核心组件构成:Frontend(FE)和Backend(BE)。这两个组件各司其职,共同协作完成数据的存储、计算和查询处理。
Doris的主要特点包括:
- 实时分析能力:支持实时数据导入和实时查询
- 高并发:能够支持数千QPS的查询请求
- 易用性:兼容MySQL协议,支持标准SQL
- 高可用:通过多副本机制保证数据可靠性
- 弹性扩展:支持在线扩容,不影响业务运行
2 Doris架构概述
Doris的整体架构采用主从模式,由FE和BE两类节点组成:
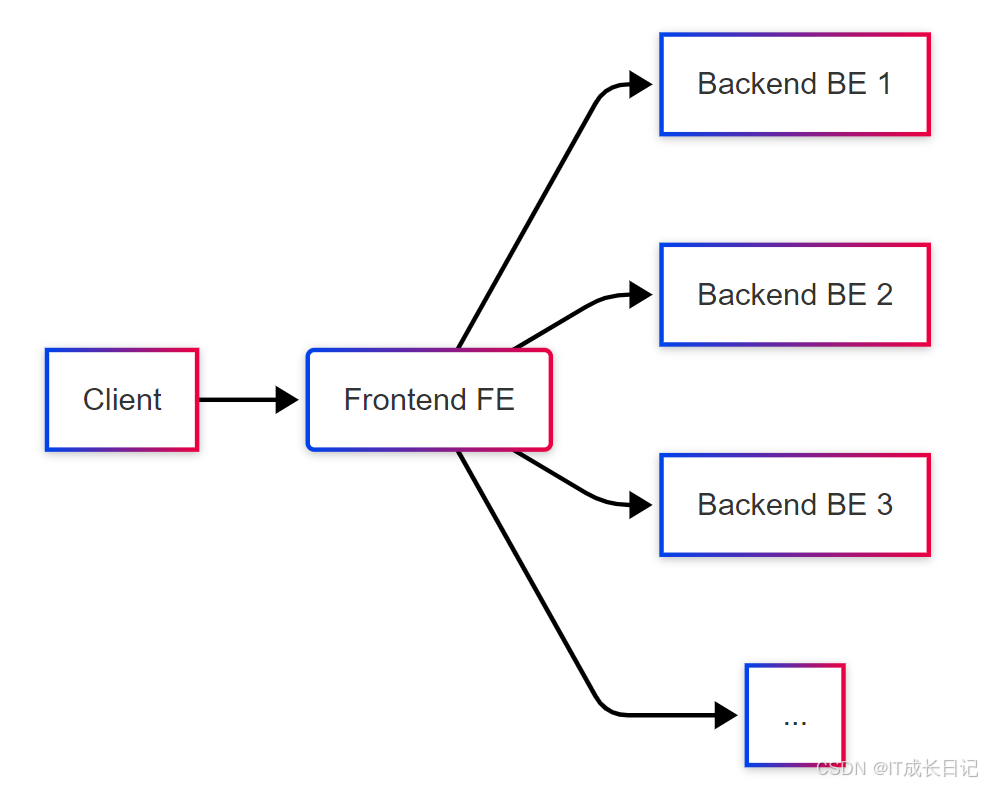
- FE节点负责元数据管理、查询解析和协调
- BE节点负责数据存储和查询执行
- 客户端通过MySQL协议与FE交互
- FE将查询计划分发给多个BE并行执行
3 Frontend(FE)职责详解
3.1 FE核心功能
FE是Doris集群的大脑,主要负责以下核心功能:
- 元数据管理:存储和管理所有数据库、表、分区等元数据信息
- 查询解析与优化:接收SQL查询,解析并生成最优执行计划
- 集群管理:管理BE节点,监控集群状态
- 协调调度:协调多个BE节点完成查询执行
- 访问控制:管理用户权限和认证
3.2 FE组件架构
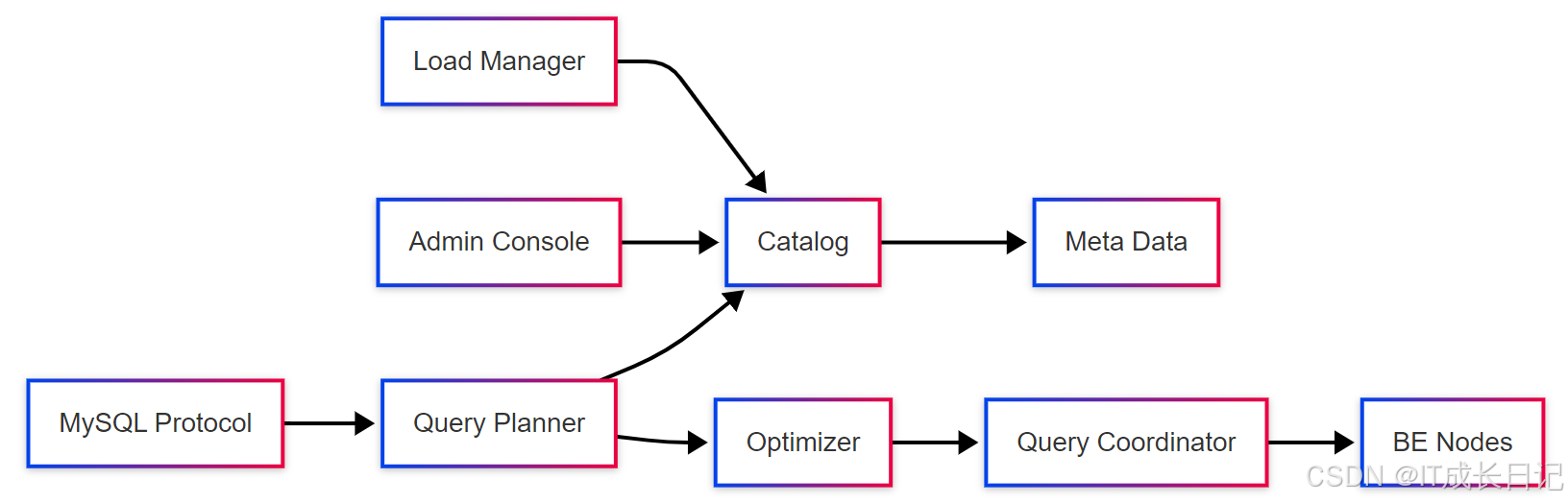
FE内部主要包含以下组件:
- Catalog:元数据存储核心,记录所有数据库对象信息
- Query Planner:SQL解析器,将SQL转换为逻辑执行计划
- Optimizer:查询优化器,基于代价模型优化执行计划
- Query Coordinator:查询协调器,分发任务到BE并收集结果
- Load Manager:管理数据导入作业
- Admin Console:管理界面和API
3.3 FE详细职责解析
3.3.1 元数据管理
FE负责维护Doris集群的所有元数据,包括:
- 数据库、表、分区、物化视图等对象的定义
- 表的Schema信息(列名、类型、索引等)
- 数据分布信息(Tablet到BE的映射关系)
- 用户权限信息
元数据存储在FE的内存中,并通过BDB(Berkeley DB)持久化到磁盘,FE采用类似RAFT的协议保证元数据的高可用
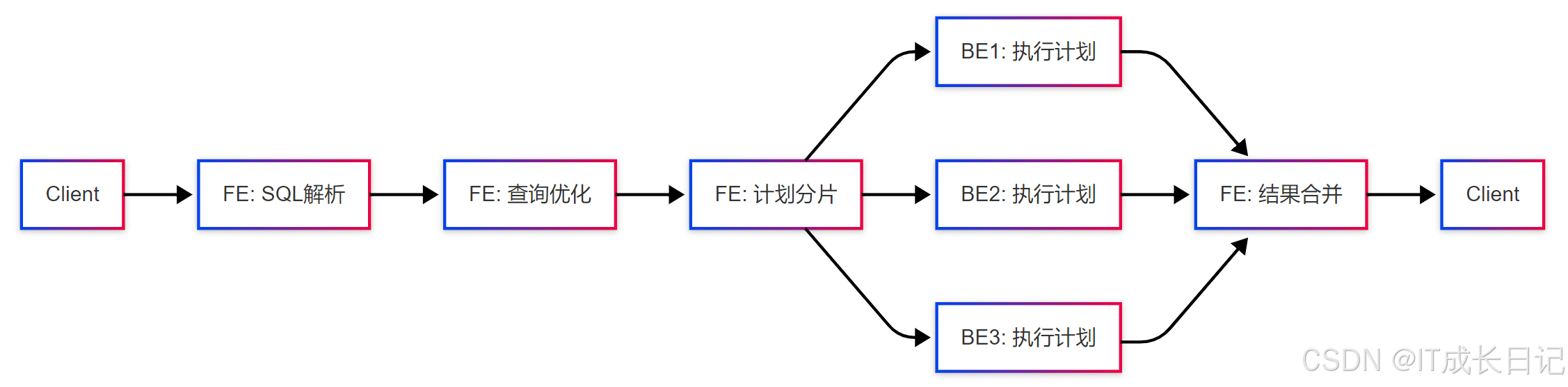
3.3.2 查询处理流程
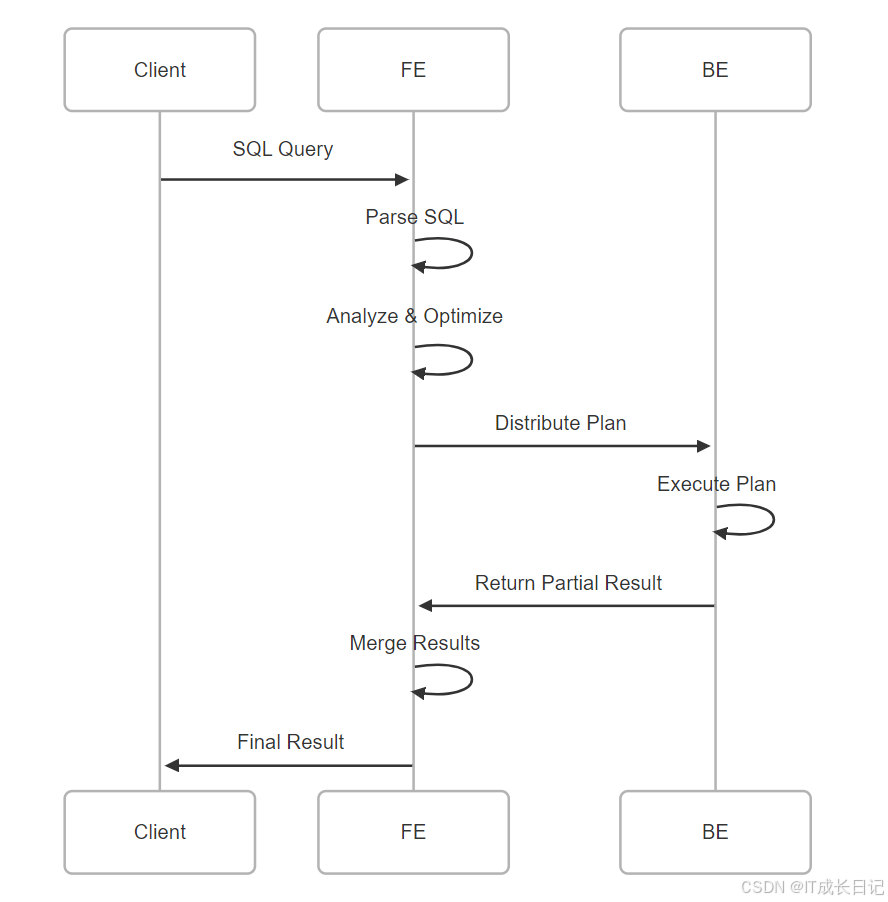
- SQL解析:将SQL文本解析为抽象语法树(AST)
- 语义分析:验证SQL语义正确性,检查表是否存在、权限等
- 逻辑优化:应用规则优化(谓词下推、列裁剪等)
- 物理优化:基于代价选择最优执行计划
- 计划分片:将执行计划划分为多个可在BE上并行执行的片段
- 结果合并:收集各BE的结果并合并返回给客户端
3.3.3 集群管理
FE负责管理整个Doris集群:
- BE节点注册与心跳检测
- 负载均衡:监控BE负载,调整数据分布
- 故障恢复:检测BE故障并触发副本修复
- 扩容缩容:管理BE节点的添加和删除
3.3.4 数据导入管理
FE协调所有数据导入操作:
- 接收导入请求(Stream Load/Routine Load等)
- 分配导入任务到合适的BE节点
- 监控导入进度
- 维护导入事务的原子性
4 Backend(BE)职责详解
4.1 BE核心功能
BE在Doris集群中主要负责:
- 数据存储:以列式格式存储表数据
- 查询执行:执行FE下发的查询计划片段
- 本地计算:在数据所在节点进行计算(MPP模型)
- 数据导入:接收并处理数据写入请求
- 副本管理:维护数据的多副本一致性
4.2 BE组件架构
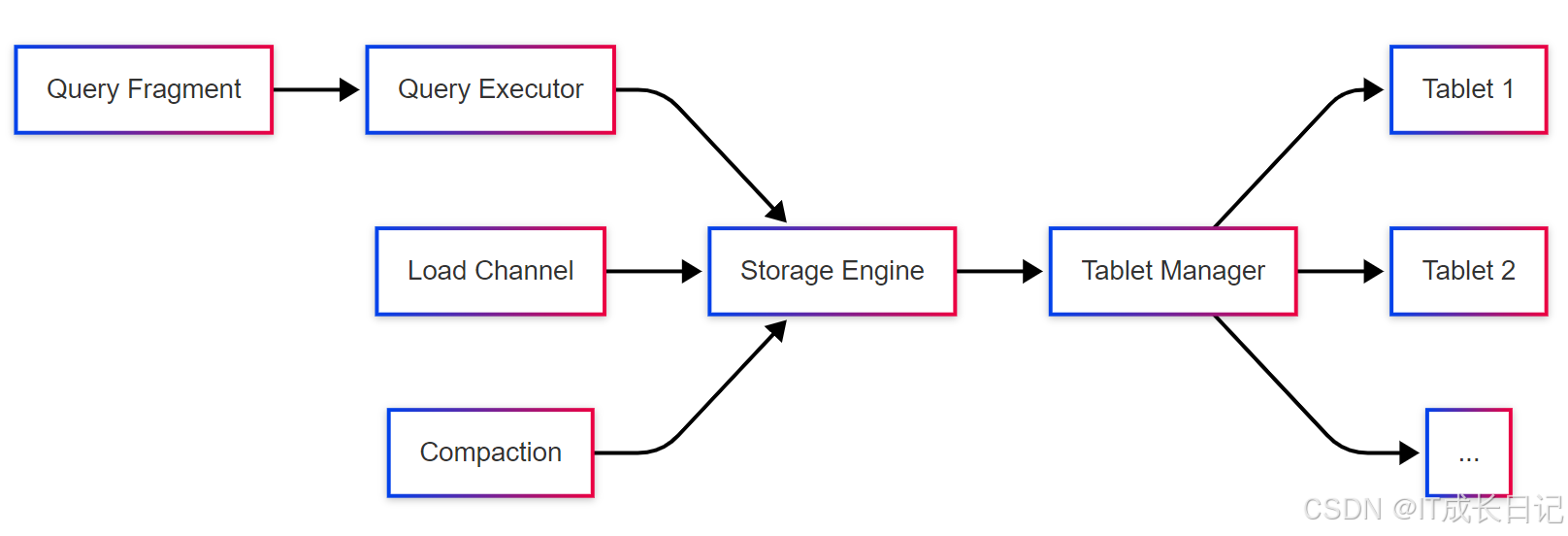
BE内部主要组件:
- Storage Engine:存储引擎,管理数据读写
- Query Executor:查询执行器,处理查询请求
- Tablet Manager:管理本地存储的Tablet
- Load Channel:处理数据导入
- Compaction:负责数据压缩合并
4.3 BE详细职责解析
4.3.1 数据存储模型
Doris采用分区-分桶两级分片:
- 分区(Partition):按照分区键(通常是时间)将表水平分割
- 分桶(Bucket):每个分区进一步哈希分桶,形成Tablet
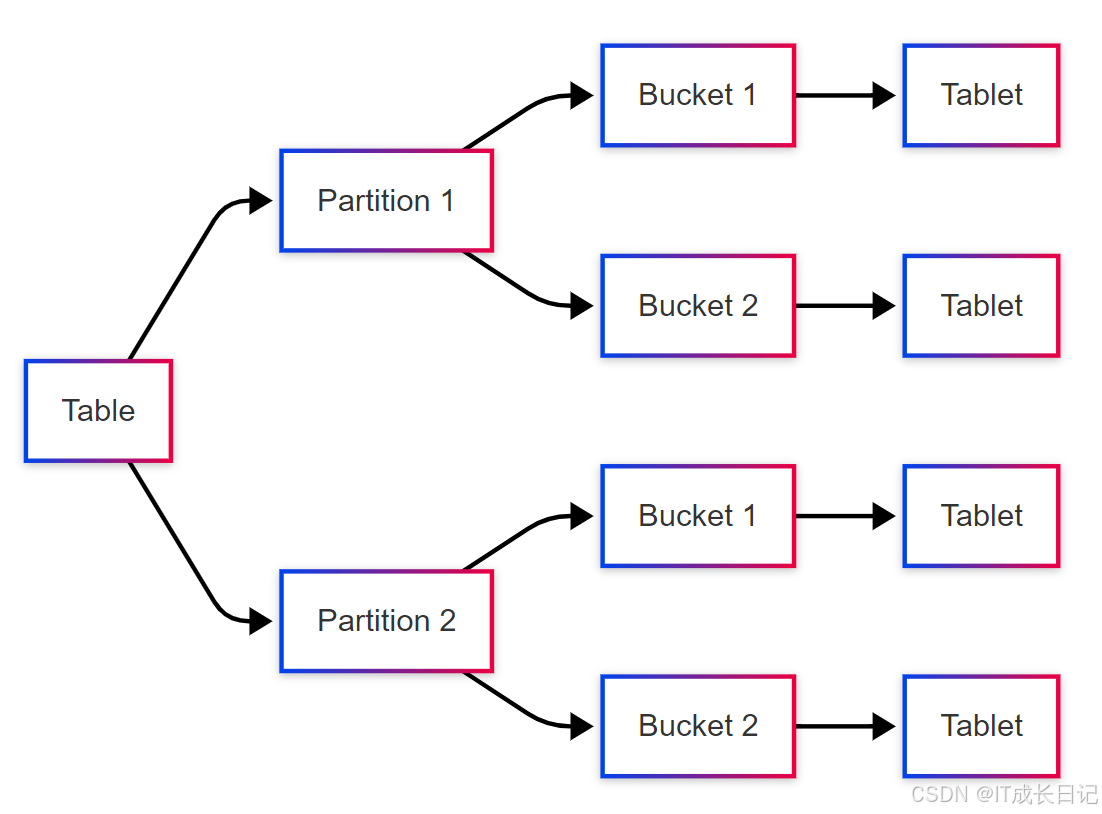
每个Tablet:
- 是数据移动、复制的最小单位
- 默认3副本,分布在不同的BE上
- 包含数据的多个Segment文件
4.3.2 查询执行流程
BE执行查询的主要步骤:
- 接收计划片段:从FE获取查询计划片段
- 数据本地化:优先读取本地存储的数据
- 并行执行:利用多线程并行处理数据
- 数据交换:与其他BE节点交换中间结果(如join/shuffle)
- 结果返回:将部分结果返回给FE
4.3.3 数据导入处理
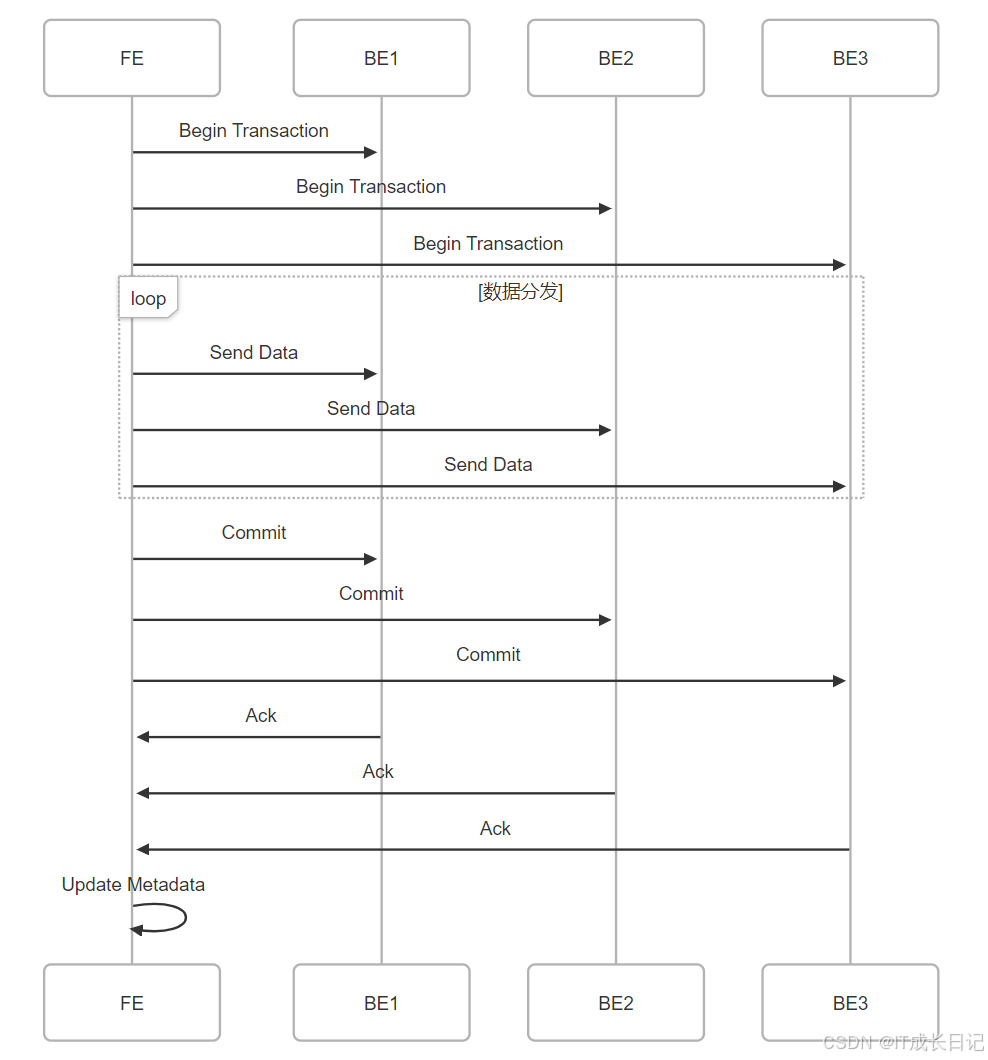
关键点:
- 采用两阶段提交保证多副本一致性
- 数据先写入内存buffer,再异步刷盘
- 支持批量导入和流式导入
4.3.4 数据压缩与合并
BE后台持续进行数据维护:
- Base Compaction:合并小文件,减少IO放大
- Cumulative Compaction:合并增量数据,优化查询性能
- Schema Change:异步执行Schema变更操作
- Clone:副本修复和均衡
5 FE与BE的协同工作机制
5.1 查询处理的完整流程
5.2 数据导入的协同流程
- FE接收导入请求并分配事务ID
- FE根据分桶规则将数据分发到多个BE
- BE接收数据并写入临时存储
- FE协调所有BE进行两阶段提交
- 提交成功后,FE更新元数据
5.3 故障恢复协同
当BE节点故障时:
- FE检测到心跳丢失
- FE将故障节点标记为不可用
- FE调度其他BE副本进行数据修复
- 新数据导入会避开故障节点
- 节点恢复后自动重新加入集群
6 总结
Doris通过FE和BE的明确职责划分实现了高效的分析处理能力:
- FE作为控制中心,负责"思考"工作:查询解析、优化、协调
- BE作为执行单元,负责"体力"工作:数据存储、计算、导入