大数据-273 Spark MLib - 基础介绍 机器学习算法 决策树 分类原则 分类原理 基尼系数 熵
点一下关注吧!!!非常感谢!!持续更新!!!
大模型篇章已经开始!
- 目前已经更新到了第 22 篇:大语言模型 22 - MCP 自动操作 Figma+Cursor 自动设计原型
Java篇开始了!
- MyBatis 更新完毕
- 目前开始更新 Spring,一起深入浅出!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 数据挖掘(已更完)
- Prometheus(已更完)
- Grafana(已更完)
- 离线数仓(已更完)
- 实时数仓(正在更新…)
- Spark MLib (正在更新…)
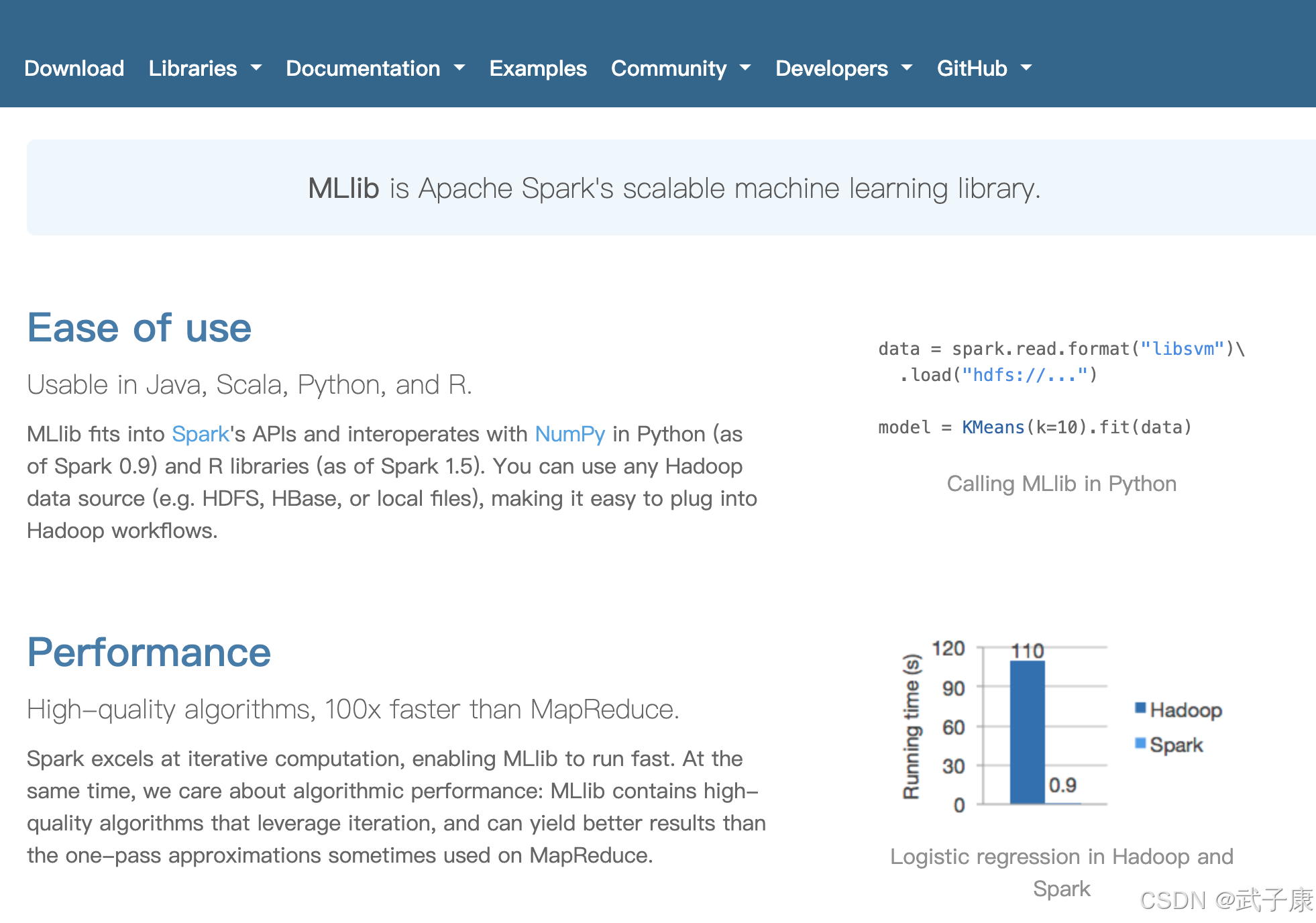
决策树简介
基本介绍
决策树是一种非线性有监督分类模型,程序设计中的条件分支结构就是 if-else 结构
决策树的特点:
● 是一种树形结构,本质上一颗由多个判断节点组成的树
● 其中每个内部节点表示一个属性上的判断
● 每个分支代表一个判断结果的输出
● 最后每个叶节点比代表一种分类结果
下面是一个简单的例子:
核心思想
通过一系列“如果 … 那么 …”的分裂规则,把复杂的决策过程拆解成若干简单判断,最终落到叶节点给出预测或决策。
适用任务
分类(Classification)与 回归(Regression)皆可;也常用于特征工程(如自动分箱)与可解释性分析。
代表算法
ID3、C4.5、CART(最常用),以及衍生的集成方法:随机森林(Random Forest)、梯度提升树(GBDT / XGBoost / LightGBM / CatBoost)。
结构与术语
root┌─┴───────┐internal internalnode1 node2┌──┴──┐ │leaf leaf leaf
- 根节点 (root):包含完整样本集
- 内部节点 (internal/decision node):依据某特征和阈值把样本划分成更“纯净”的子集
- 叶节点 (leaf / terminal node):输出类别标签或数值预测结果
- 路径 (path):从根到叶的一条决策链,相当于一个规则组合
分类原则
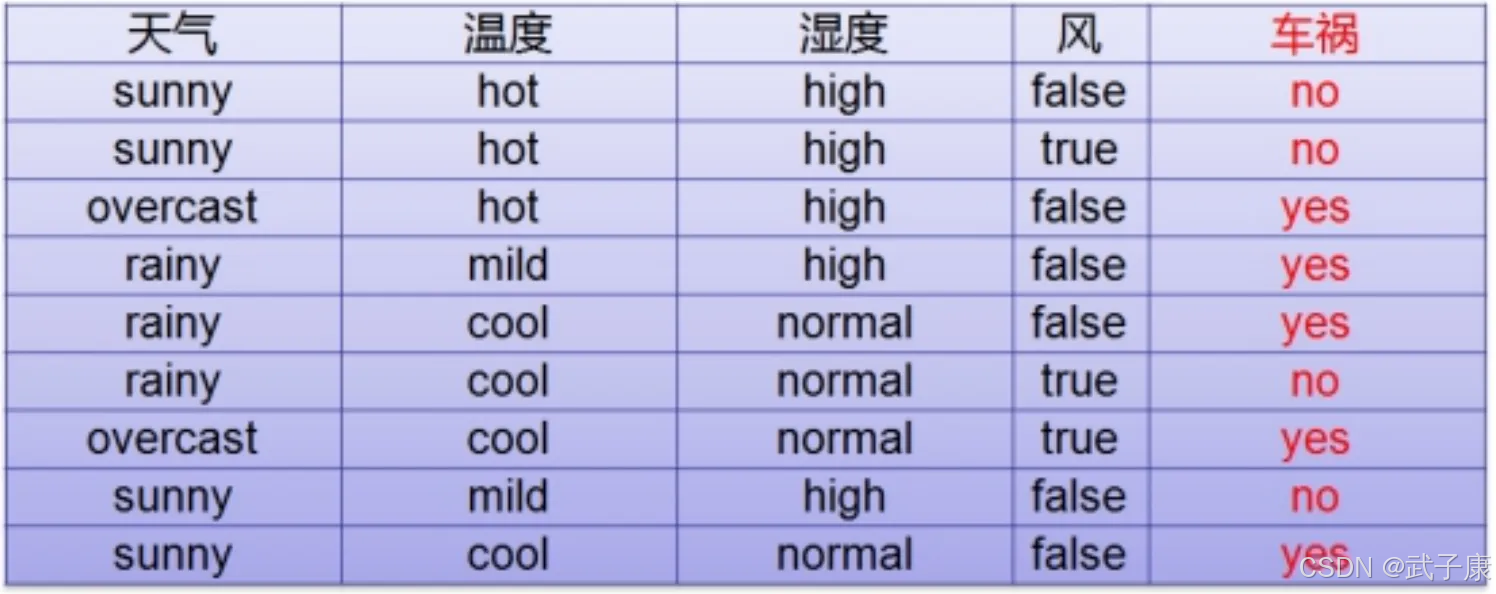
要按照前四列的信息,使用决策树预测车祸的发生,如何选择根节点呢?
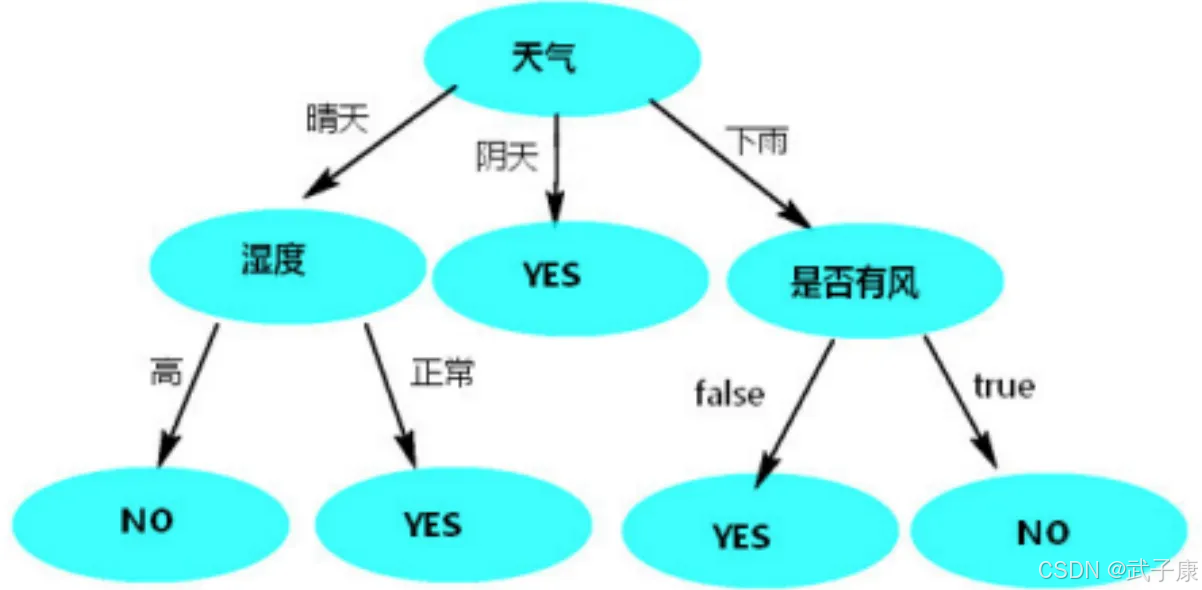
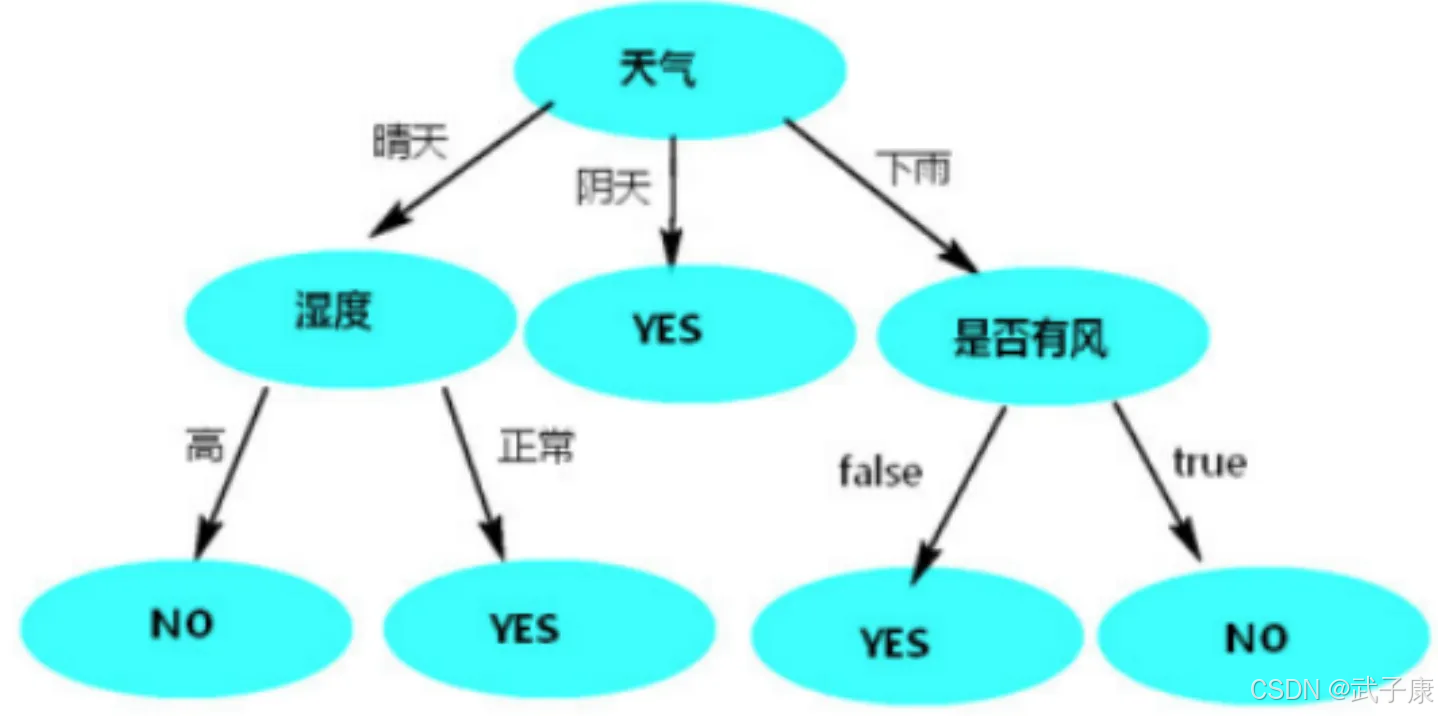
按照天气
按照“天气”列作为根节点,使用决策树预测,如图:
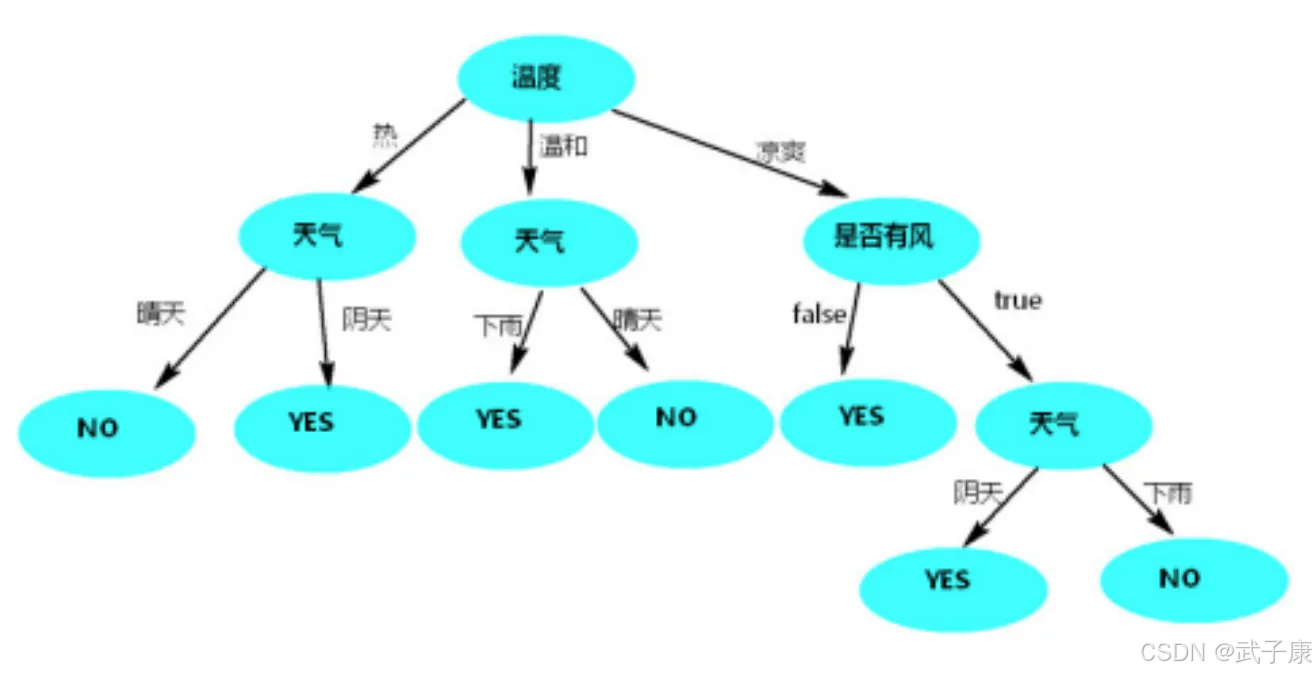
按照温度
按照“温度”列作为根节点,使用决策树预测,如图:
按照湿度

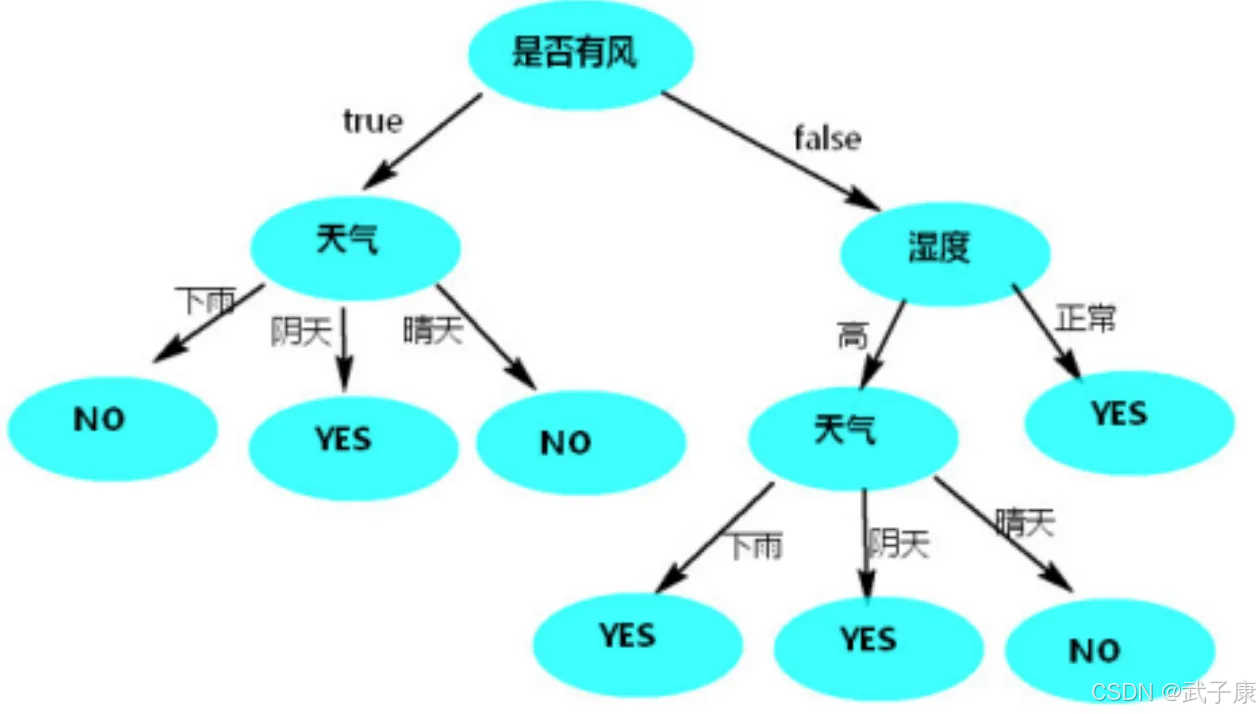
按照风
简单总结
只有使用天气作为根节点时,决策树的高度相对低而且树的两边能将数据分类的更彻底(其他列作为根节点时,树两边分类不纯粹,都有天气)
分类原则总结:
决策树构建过程就是数据不断分裂的递归过程,每一次分裂,尽可能让类别一样的数据在树的一边,当树的叶子节点的数据都是一类的时候,则停止分类。这样分类的数据,每个节点两边的数据不同,将相同的数据分类到树的一侧,能将数据分类的更加纯粹,减少树的高度和训练决策树的迭代次数。
分类原理
熵的介绍
物理学上,熵 Entropy 是 “混乱”程度的量度,系统越有序,熵值越低,系统越混乱或者分散,熵值越高。1948年香农提出了信息熵的概念。
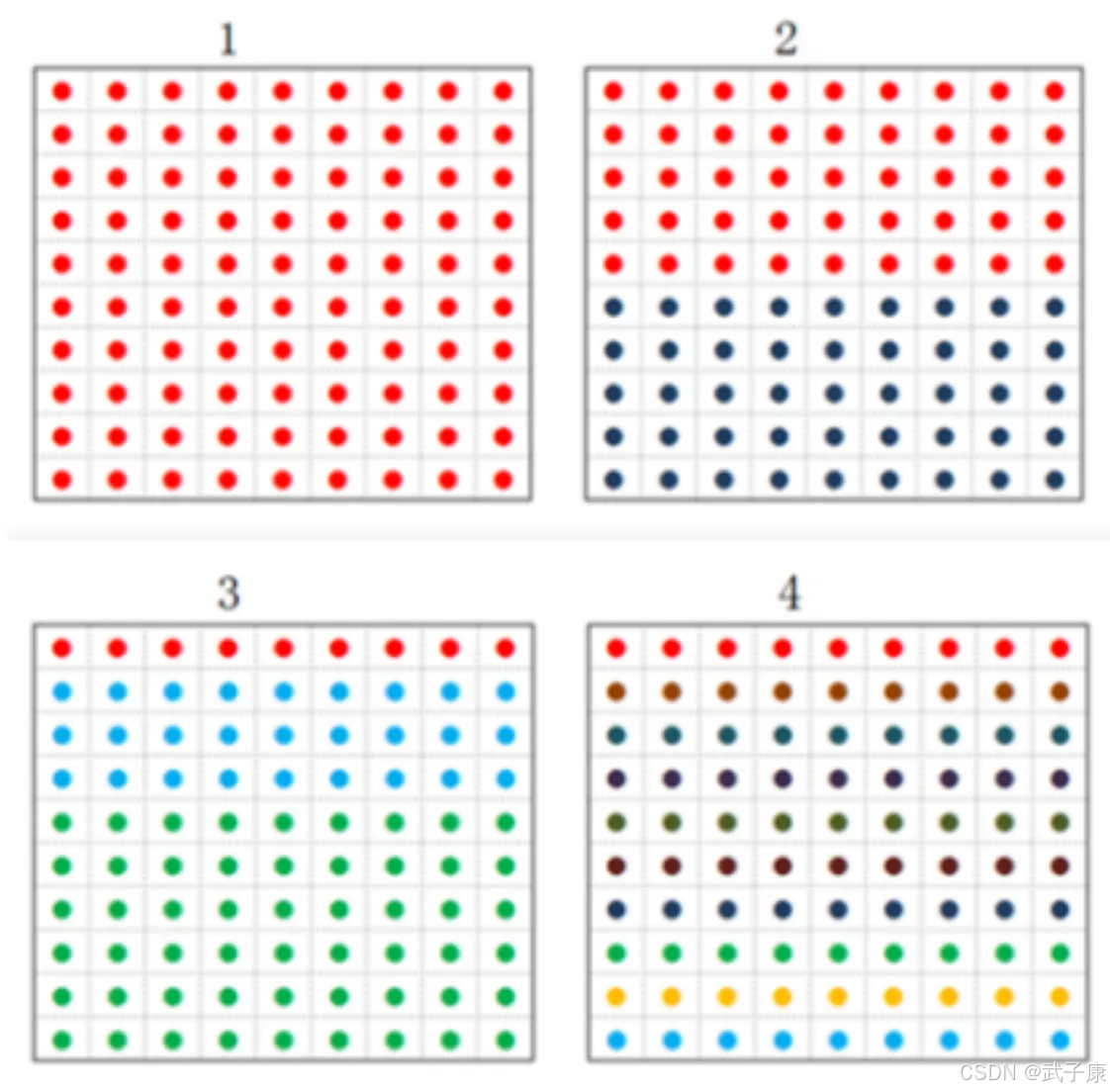
如何衡量纯粹和混乱(信息量的大小)指标,可以使用信息熵或者基尼系数。
熵的定义如下:
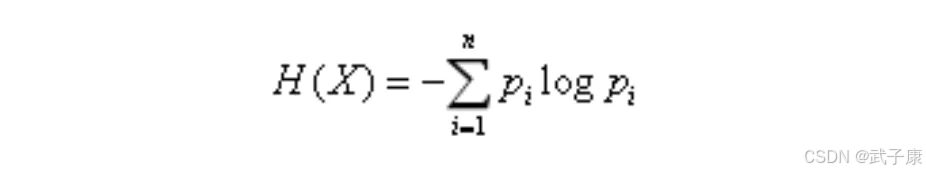
● 某个类别下信息量越多,熵越大
● 信息量越少,熵越小
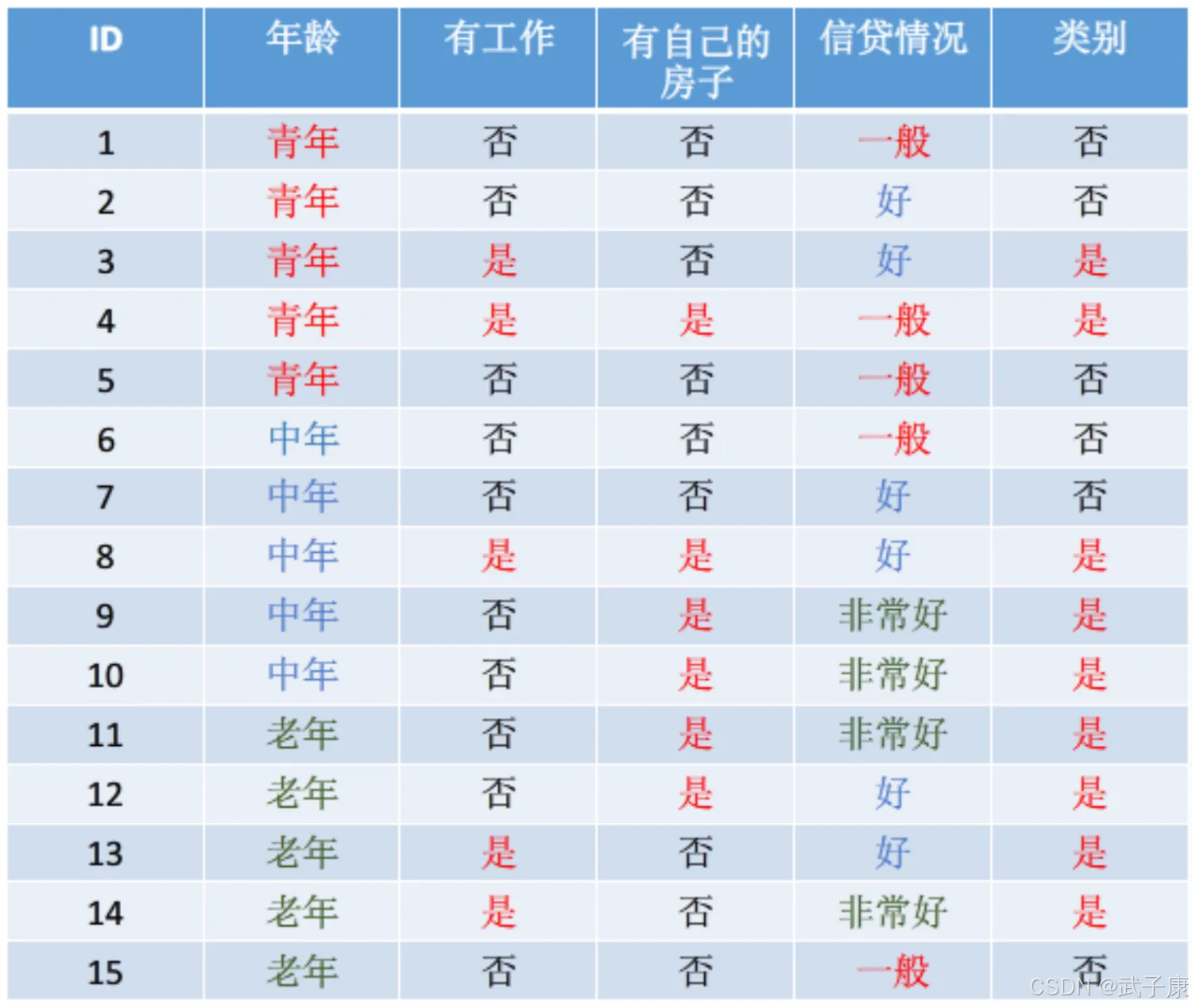
● 假设“有工作”这列下只有“否”这个信息类别,那么“有工作”这列的信息熵为:H=-(1xlog1)=0
上图中,如果按照“有工作”、“年龄”、“信贷情况”、“有房子”列使用决策树来预测“类别”。如何选择决策树的根节点分类条件,就是找到某列作为分类条件时,使“类别”这列分类更彻底,也就是找到在某个列作为分类条件下时,“类别”信息熵相对于没有这个分类条件时信息熵降低最大(降低最大,就是熵越低,分类越彻底),这个条件就是分类节点的分类条件,这里要使用条件熵和信息增益。
条件熵
定义:在某个分类条件下某个类别的信息熵叫做条件熵,在知道Y的情况下,X的不确定性。
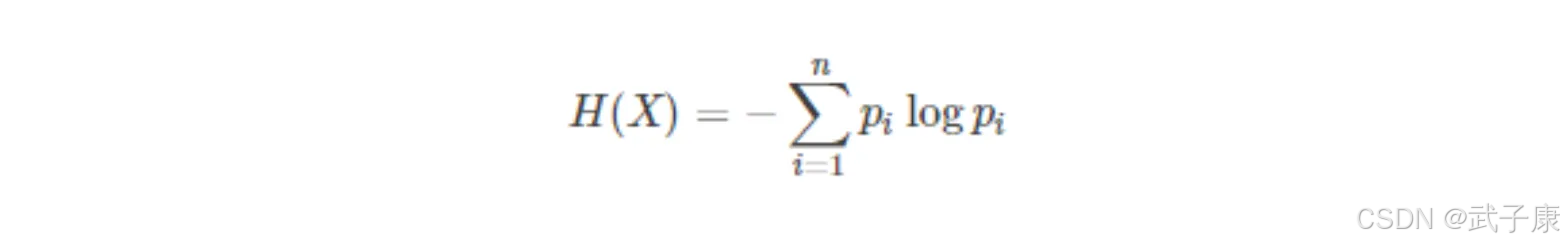
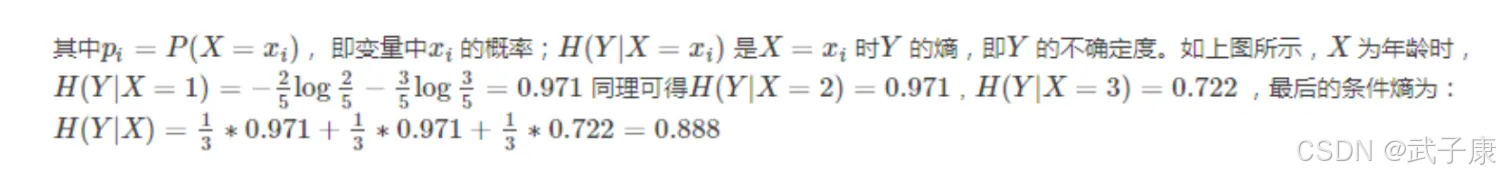
信息增益
定义:代表熵的变化程度,分类前的信息熵减去分类后的信息熵
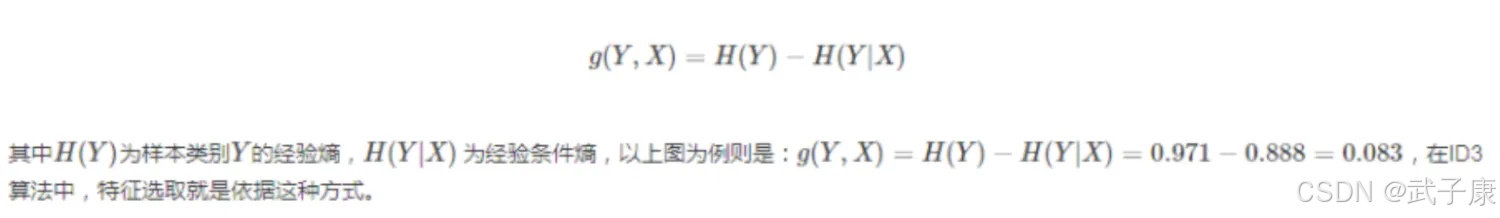
在构建决策树时,选择信息增益大的属性作为分类节点的方法也叫ID3分类算法。
基尼系数
基尼系数也可以表示样本的混乱程度,公式如下:
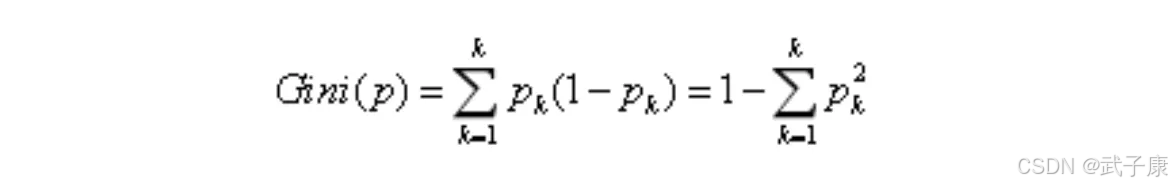
其中,K代表当前列表有K个类别。
基尼系数越小代表信息越纯,类别越少,基尼系数越大,代表信息越混乱,类别越多。基尼增益的计算和信息增益相同,假设某列只有一类值,这列基尼系数为0。
信息增益率
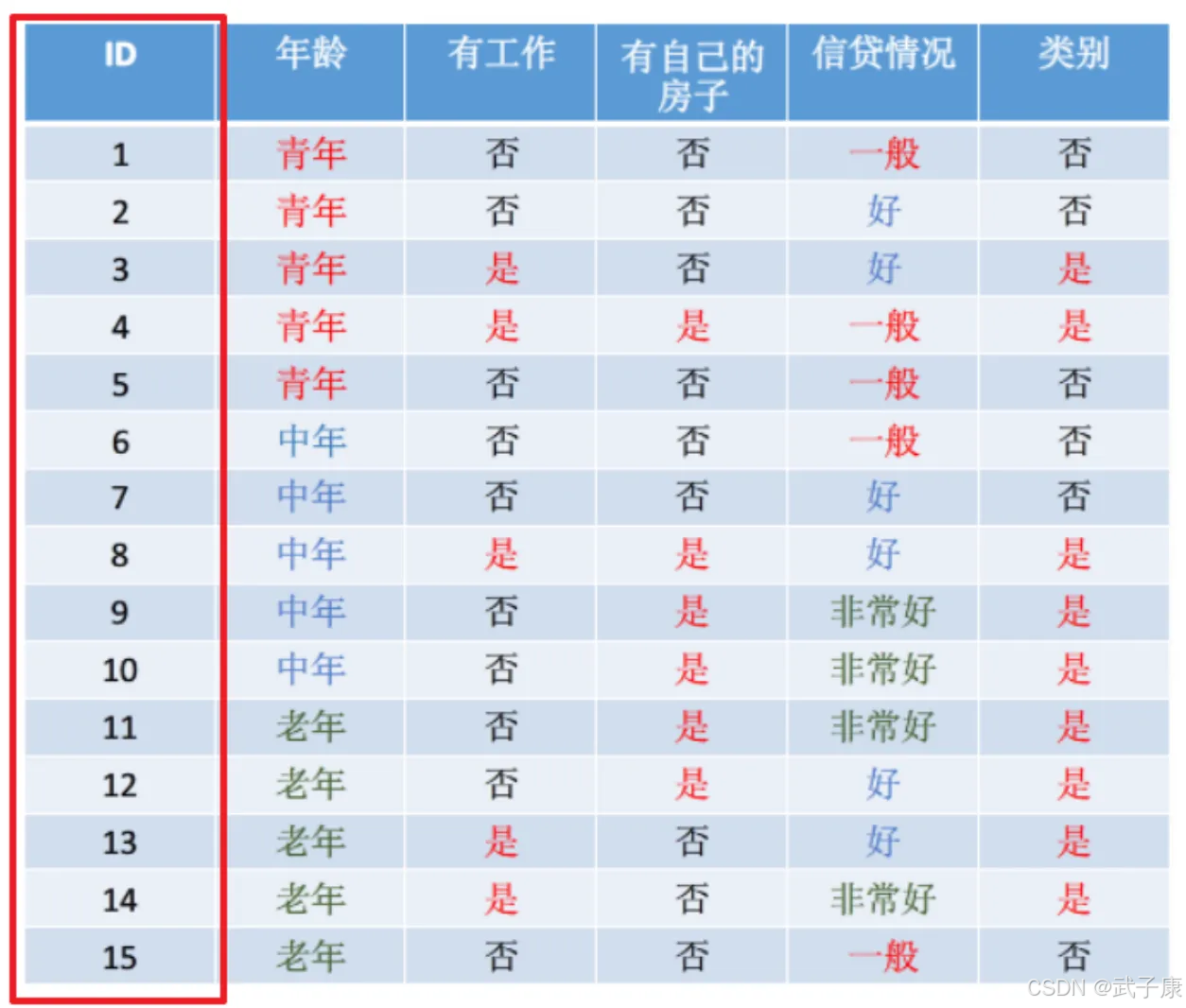
在上图中,如果将“记录ID”也作为分类条件的话,由于“记录ID”对于“是否贷款”列的条件熵为0,可以得到“是否贷款”在“记录ID”这个分类条件下信息增益最大。如果选择“记录ID”作为分类条件,可以将样本完全分开,分类后的信息熵为0,分类结果完全正确,信息增益最大,这种方式我们得到了一颗庞大的树,这种分类方式是不合理的。
使用信息增益来筛选分类条件,更倾向于更混杂的属性,容易出现你过拟合的问题,可以使用信息增益率来解决这个问题。
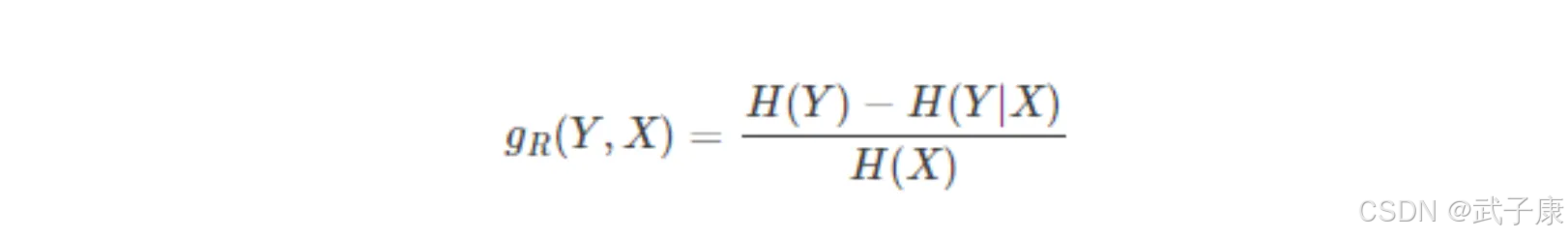
例如在“记录ID”条件下,“是否贷款”的信息增益最大,信息熵H(记录ID)也比较大,两者相除就是在“记录ID”条件下的增益率,结果比较小,笑出了当某些属性比较混杂时,使用信息增益来选择分类条件的弊端。
使用信息增益率来构建决策树的算法也叫C4.5算法,一般对于信息增益来说,选择信息增益率选择分类条件比较合适。