Unity-编辑器扩展-其二
今天我们来基于之前提到的编辑器扩展的内容来做一些有实际用处的内容:
检查丢失的组件
首先是一个比较实际的内容:当我们在做项目时,经常会涉及到预设体在不同项目或者不同文件路径下的转移,这个时候很容易在某个具体的prefab对象上丢失组件,这个时候如果有一个脚本专门帮助我们来检查预设体上可能有的丢失的组件的话就非常好了。
需要的代码如下:
using System.Collections;
using System.Collections.Generic;
using UnityEditor;
using UnityEngine;namespace ToolKits
{public class MissingComponentChecker{private const string PATH = "Assets/Prefabs"; private const string PrefabNameColor = "#00FF00";private const string PathColor = "#0000FF";[MenuItem("Tools/CheckMissingComponent", priority = 8)]private static void MissingComponentCheck(){var guids = AssetDatabase.FindAssets("t:GameObject", new[] { PATH });var length = guids.Length;var index = 1;foreach (var guid in guids){var path = AssetDatabase.GUIDToAssetPath(guid);EditorUtility.DisplayProgressBar("玩命检查中", "玩命检查中..." + path, (float)index / length);var prefab = AssetDatabase.LoadAssetAtPath<GameObject>(path);FindMissingComponentRecursive(prefab, prefab, path);index++;}EditorUtility.ClearProgressBar();EditorUtility.DisplayDialog("提示", "检查结束", "OK");}private static void FindMissingComponentRecursive(GameObject gameObject, GameObject prefab, string path){var cmps = gameObject.GetComponents<Component>();for (int i = 0; i < cmps.Length; i++){if (null == cmps[i]){Debug.LogError($"<color={PrefabNameColor}>{GetRelativePath(gameObject, prefab)}</color> has missing components! path is: <color={PathColor}>{path}</color>");}}foreach (Transform trans in gameObject.transform){FindMissingComponentRecursive(trans.gameObject, prefab, path);}}private static string GetRelativePath(GameObject gameObject, GameObject prefab){if (null == gameObject.transform.parent){return gameObject.name;}else if (gameObject == prefab){return gameObject.name;}else{return GetRelativePath(gameObject.transform.parent.gameObject, prefab) + "/" + gameObject.name;}}}
}我们先来看效果:我们新建一个Prefab,然后在这个预设体上面新加一个脚本,然后再去把这个脚本删除后:
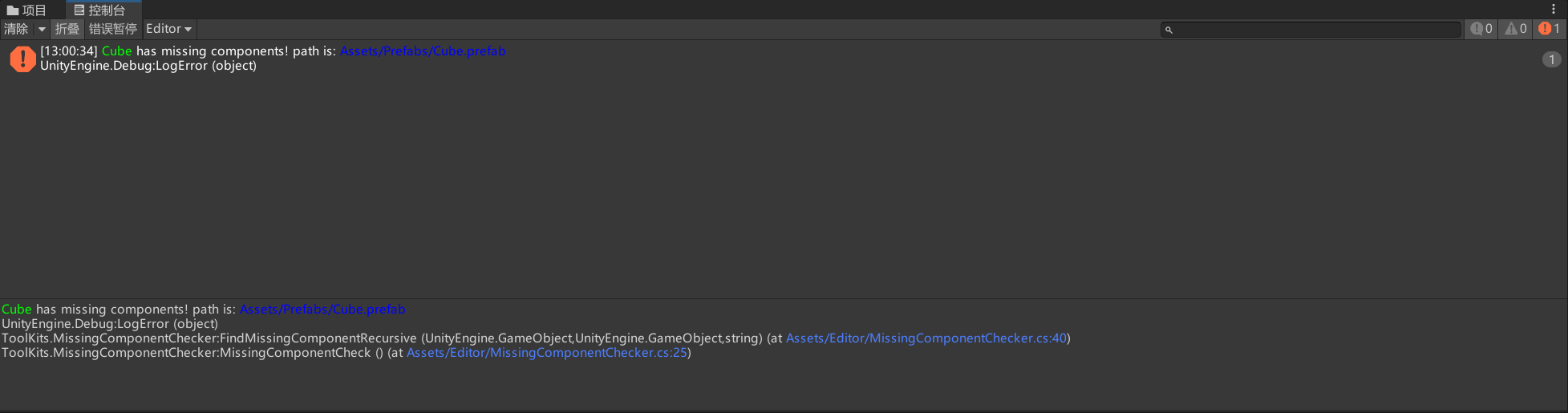
他就可以检查出问题所在了。
接着我们来分析代码:
这段代码实现了一个Unity编辑器工具,通过在菜单"Tools/CheckMissingComponent"创建入口,执行时它首先调用AssetDatabase.FindAssets获取指定路径下所有GameObject类型资源的GUID,然后循环遍历这些GUID,利用AssetDatabase.GUIDToAssetPath将GUID转换为资源路径并使用EditorUtility.DisplayProgressBar显示检查进度,接着用AssetDatabase.LoadAssetAtPath加载每个预制体,针对每个预制体及其所有子对象,采用递归方式调用FindMissingComponentRecursive函数深度遍历GameObject层级结构,在遍历过程中使用GetComponents<Component>()获取所有组件并检查是否存在null值(表示丢失的组件),一旦发现丢失组件便通过Debug.LogError输出带有颜色标记的错误信息,显示问题对象在预制体中的相对路径(通过GetRelativePath递归构建)和预制体的资源路径,最后调用EditorUtility.ClearProgressBar清除进度条并使用EditorUtility.DisplayDialog弹出对话框通知用户检查完成,整个工具有效地帮助开发者在项目开发过程中及时发现和定位预制体中的丢失组件问题,提高项目质量和稳定性。
其中的GUID:

EditorUtility:
EditorUtility是Unity编辑器中的一个核心API类,专门为编辑器扩展提供各种实用工具函数。它是UnityEditor命名空间下的一个静态类,主要用于增强编辑器功能、提供编辑器交互界面以及处理资源操作的便捷方法。EditorUtility提供了丰富的功能,包括显示进度条、文件对话框、消息提示框、资源保存和修改提示、对象选择窗口等编辑器级别的UI交互;同时还包括一些特殊的资源处理功能,如序列化复制、对象实例化和复制、预制体操作等;此外,它还提供了文件路径处理、资源导入导出功能以及场景和对象修改状态管理。与Runtime代码不同,EditorUtility类只能在编辑器环境中使用,不能在构建后的游戏中运行,它的主要目的是简化编辑器工具开发工作,让开发者能够创建与Unity编辑器无缝集成的自定义工具和工作流程,提高项目开发效率。
AssetDatabase:
AssetDatabase 是 Unity 编辑器中的核心资源管理类,属于 UnityEditor 命名空间,专为编辑器模式设计,用于在开发阶段高效操作和管理项目资源。

Shader变体统计
首先我们当然要知道什么是Shader变体:
Shader变体(Shader Variant)是同一份Shader源码通过不同宏定义编译出的多个版本,每个版本对应一组特定的关键字(Keywords)组合。其本质是通过预处理指令(如 #pragma multi_compile 或 #pragma shader_feature)动态生成不同的代码分支,从而适应不同渲染需求(如是否启用雾效、光照模型差异、平台适配等)
为什么要去做shader变体的统计呢?这对于性能优化和构建大小控制非常重要,因为着色器变体数量过多会导致诸如编译时间延长,构建大小增加等等问题。
那具体来说怎么去统计Shader的变体呢?比较常见的方法是利用反射来做,通过反射调用ShaderUtil.GetVariantCount,统计所有Shader的变体总数。
代码如下:
using System.Collections;
using System.Collections.Generic;
using System.IO;
using System.Reflection;
using System.Text;
using UnityEditor;
using UnityEngine;namespace ToolKits
{public class ShaderKit{private const string ShaderPath = "Assets/Shaders";private static string OutputPath = "Assets/ShaderOutput";[MenuItem("Tools/变体统计", priority = 21)]public static void CalcAllShaderVariantCount(){var asm = typeof(SceneView).Assembly;System.Type type = asm.GetType("UnityEditor.ShaderUtil");MethodInfo method = type.GetMethod("GetVariantCount",BindingFlags.Static | BindingFlags.Public | BindingFlags.NonPublic);var shaderList = AssetDatabase.FindAssets("t:Shader", new[] { ShaderPath });string date = System.DateTime.Now.ToString("yyyy-MM-dd-hh-mm-ss");string pathF = string.Format("{0}/ShaderVariantCount{1}.csv", OutputPath, date);FileStream fs = new FileStream(pathF, FileMode.Create, FileAccess.Write);StreamWriter sw = new StreamWriter(fs, Encoding.UTF8);EditorUtility.DisplayProgressBar("Shader统计文件", "正在写入统计文件中...", 0f);int ix = 0;sw.WriteLine("Shader 数量:" + shaderList.Length);sw.WriteLine("ShaderFile, VariantCount");int totalCount = 0;foreach (var i in shaderList){EditorUtility.DisplayProgressBar("Shader统计文件", "正在写入统计文件中...", ix / shaderList.Length);var path = AssetDatabase.GUIDToAssetPath(i);Shader s = AssetDatabase.LoadAssetAtPath(path, typeof(Shader)) as Shader;var variantCount = method.Invoke(null, new System.Object[] { s, true });sw.WriteLine(path + "," + variantCount.ToString());totalCount += int.Parse(variantCount.ToString());++ix;}sw.WriteLine("Shader Variant Total Amount: " + totalCount);EditorUtility.ClearProgressBar();sw.Close();fs.Close();}}
}我们现在先去构建一些着色器变体来用。
我们在一个基础的无光照shader中加入以下指令:
#pragma multi_compile_fog#pragma multi_compile _ _MAIN_LIGHT_SHADOWS#pragma multi_compile _ _MAIN_LIGHT_SHADOWS_CASCADE#pragma shader_feature _USENORMALMAP_ON#pragma multi_compile _ _ADDITIONAL_LIGHTS#pragma multi_compile _ _ADDITIONAL_LIGHT_SHADOWS分别是:

从这里看起来似乎我们应该是有2的六次方也就是64个变体,但实际上这些变体之间并不是完全独立的,有些变体的实现必须依赖其他变体,比如:_ADDITIONAL_LIGHT_SHADOWS变体只有在_ADDITIONAL_LIGHTS启用时才会生效(你得有额外光才有额外光阴影吧),_MAIN_LIGHT_SHADOWS_CASCADE变体只有在_MAIN_LIGHT_SHADOWS启用时才会生效。
除此之外,还有一个点就是Unity会自动删除一些不可能实现的变体或者没有意义的变体,这个背后的筛选条件我就不得而知了,反正最后我们通过变体统计之后就可以得到:
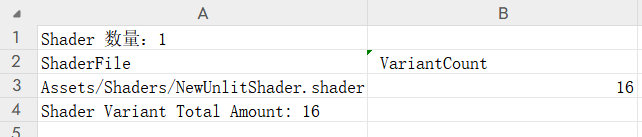
这样我们就实现了Shader变体的统计方法了。
这段代码实现了一个Unity编辑器工具,通过在菜单"Tools/变体统计"创建入口,执行时首先通过反射获取Unity内部ShaderUtil类的GetVariantCount方法,然后使用AssetDatabase.FindAssets在指定路径下查找所有Shader资源,接着创建一个带时间戳的CSV文件用于记录结果,在遍历每个Shader资源的过程中,使用EditorUtility.DisplayProgressBar显示进度条,通过AssetDatabase.GUIDToAssetPath将资源GUID转换为路径,再使用AssetDatabase.LoadAssetAtPath加载Shader资源,调用之前获取的GetVariantCount方法计算每个Shader的变体数量,将结果写入CSV文件并累加总变体数量,最后在CSV文件末尾写入总变体数量,清除进度条并关闭文件流,整个工具通过反射访问Unity内部API和编辑器API,实现了对项目中所有Shader变体数量的统计和导出。
可以看到核心其实就是这个ShaderUtil类的GetVariantCount方法,ShaderUtil.GetVariantCount是Unity编辑器内部的一个方法,通过反射获取后可以计算指定着色器的变体数量,它通过分析着色器中的#pragma multi_compile和#pragma shader_feature指令,考虑变体之间的依赖关系和平台限制,计算所有可能的组合数量。
反射(Reflection)是.NET框架提供的一种机制,允许程序在运行时获取类型信息、访问和操作对象,而不需要在编译时知道这些类型的具体信息。在这段代码中,反射被用来访问Unity编辑器内部的ShaderUtil.GetVariantCount方法。
反射就是程序在运行时可以对元数据进行访问的一个机制,然后像我们着色器变体的信息也是以元数据的形式存储在当前程序集的,理论上我们通过反射可以获取所有程序集中涉及到的所有类型对象方法的内容。
查找代码中的中文
这个功能在有大量代码的时候可以帮助你快速定位特定的代码段,这里要查找的也不一定是中文,还可以是其他内容。
代码如下:
using UnityEngine;
using UnityEditor;
using System.Collections.Generic;
using System.IO;
using System.Collections;
using System.Text.RegularExpressions;
using System.Text;public class FindChineseTool : MonoBehaviour
{[MenuItem("Tools/查找代码中文")]public static void Pack(){Rect wr = new Rect(300, 400, 400, 100);FindChineseWindow window = (FindChineseWindow)EditorWindow.GetWindowWithRect(typeof(FindChineseWindow), wr, true, "查找项目中的中文字符");window.Show();}
}public class FindChineseWindow : EditorWindow
{private ArrayList csList = new ArrayList();private int eachFrameFind = 4;private int currentIndex = 0;private bool isBeginUpdate = false;private string outputText;public string filePath = "/Scripts";private void GetAllFIle(DirectoryInfo dir){FileInfo[] allFile = dir.GetFiles();foreach (FileInfo fi in allFile){if (fi.DirectoryName.Contains("FindChineseTool"))//排除指定名称的代码continue;if (fi.FullName.IndexOf(".meta") == -1 && fi.FullName.IndexOf(".cs") != -1){csList.Add(fi.DirectoryName + "/" + fi.Name);}}DirectoryInfo[] allDir = dir.GetDirectories();foreach (DirectoryInfo d in allDir){GetAllFIle(d);}}public void OnGUI(){EditorGUILayout.BeginHorizontal();filePath = EditorGUILayout.TextField("Path", filePath);//if (GUILayout.Button("粘贴", GUILayout.Width(100)))//{// TextEditor te = new TextEditor();// te.Paste();//}EditorGUILayout.EndHorizontal();EditorGUILayout.BeginHorizontal();GUILayout.Label(outputText, EditorStyles.boldLabel);if (GUILayout.Button("开始遍历项目")){csList.Clear();DirectoryInfo d = new DirectoryInfo(Application.dataPath + filePath);GetAllFIle(d);outputText = "游戏内代码文件的数量:" + csList.Count;isBeginUpdate = true;outputText = "开始遍历项目";string name = "ChineseTexts.csv";string powerCsv = Application.dataPath + "/../Temp/" + name;if (File.Exists(powerCsv)){File.Delete(powerCsv);}}EditorGUILayout.EndHorizontal();}void Update(){if (isBeginUpdate && currentIndex < csList.Count){int count = (csList.Count - currentIndex) > eachFrameFind ? eachFrameFind : (csList.Count - currentIndex);for (int i = 0; i < count; i++){string url = csList[currentIndex].ToString();currentIndex = currentIndex + 1;url = url.Replace("\\", "/");printChinese(url);}if (currentIndex >= csList.Count){isBeginUpdate = false;currentIndex = 0;outputText = "遍历结束,总共" + csList.Count;}}}private bool HasChinese(string str){return Regex.IsMatch(str, @"[\u4e00-\u9fa5]");}private Regex regex = new Regex("\"[^\"]*\"");private void printChinese(string path){if (File.Exists(path)){string[] fileContents = File.ReadAllLines(path, Encoding.Default);int count = fileContents.Length;string name = "ChineseTexts.csv";string powerCsv = Application.dataPath + "/../Temp/" + name;StreamWriter file = new StreamWriter(powerCsv, true);for (int i = 0; i < count; i++){string printStr = fileContents[i].Trim();if (printStr.IndexOf("//") == 0) //说明是注释continue;if (printStr.IndexOf("#") == 0){continue;}if (printStr.IndexOf("Debug.Log") == 0) //说明是注释continue;if (printStr.Contains("//")) //说明是注释continue;MatchCollection matches = regex.Matches(printStr);Regex regexContent = new Regex("\"(.*?)\"");foreach (Match match in matches){if (HasChinese(match.Value)){Debug.Log("路径:" + path + " 行数:" + i + " 代码:" + printStr);MatchCollection mc = regexContent.Matches(printStr);foreach (var item in mc){//Debug.Log("路径:" + path + " 行数:" + i + " 代码:" + printStr + " 内容:" + item.ToString());StringBuilder sb = new StringBuilder();sb.Append(item.ToString());sb.Append(",");sb.Append(path.Substring(path.IndexOf(filePath) + 7));sb.Append(",");sb.Append(i);sb.Append(",");sb.Append("\"" + printStr.Replace("\"", "\"\"") + "\"");file.WriteLine(sb.ToString());}}}}file.Close();fileContents = null;}}
}然后我们随便写点中文:
using System.Collections;
using System.Collections.Generic;
using UnityEngine;public class ALotOfChinese : MonoBehaviour
{private string str ="老公今晚不在家";
}
点击遍历中文之后就可以看到:
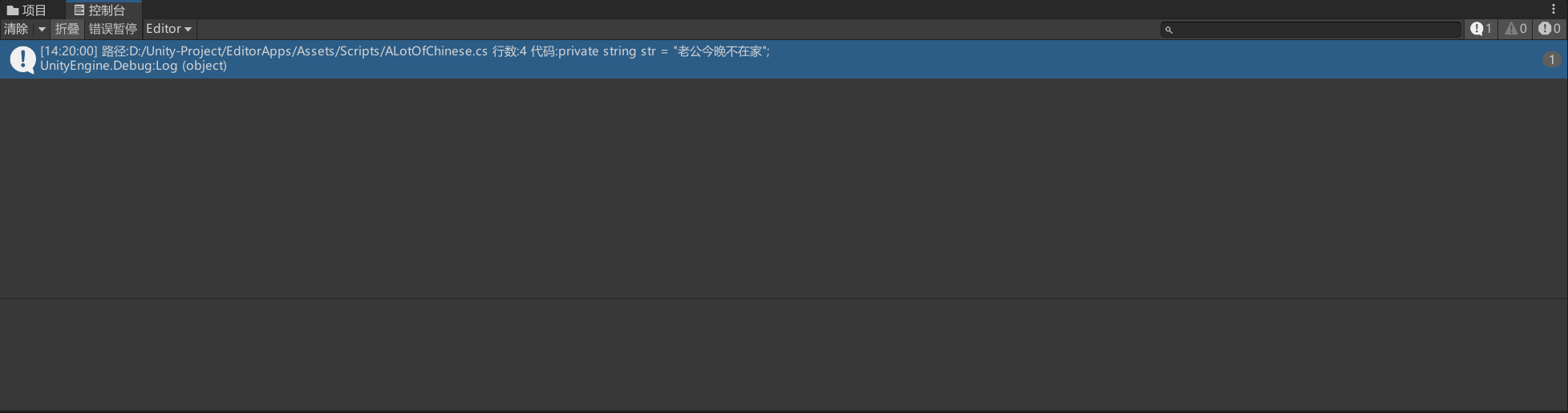
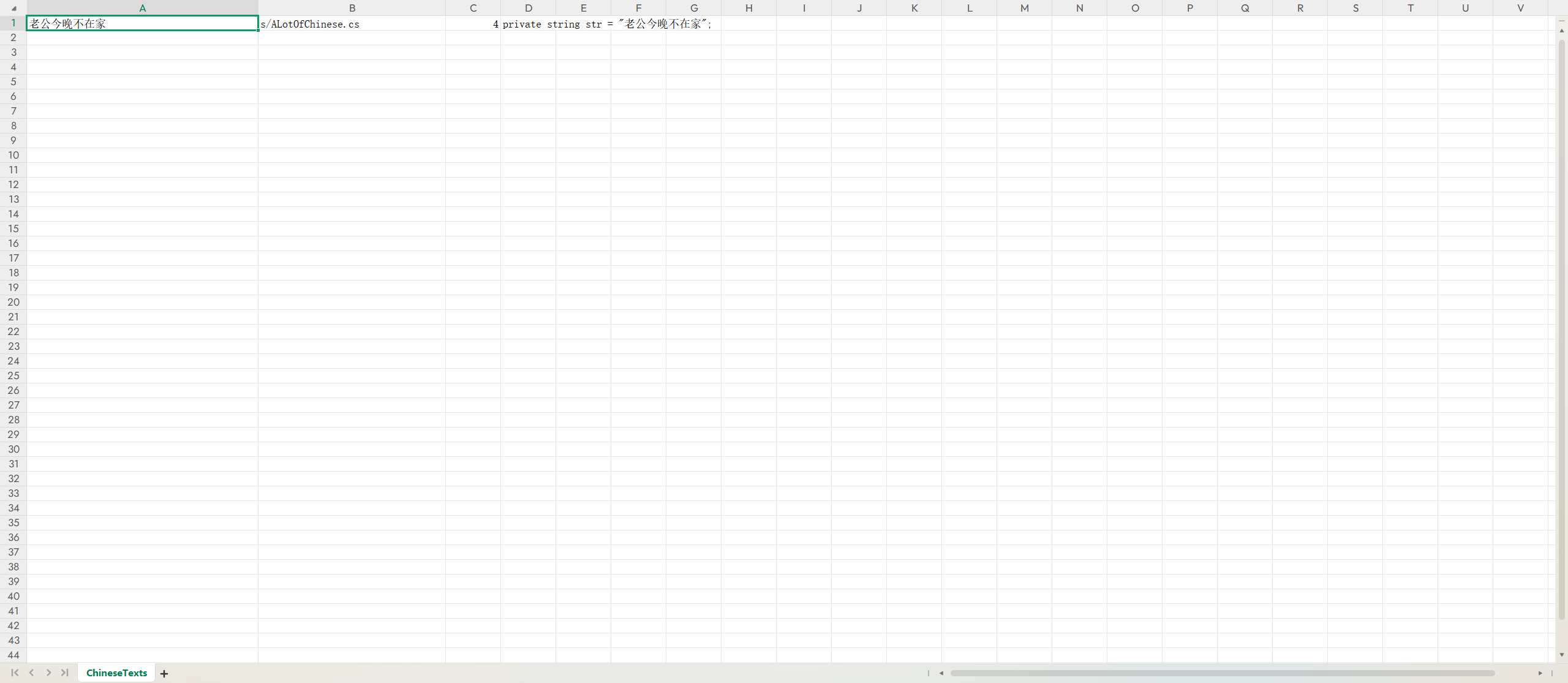
这里必须要说的是,我们的Visual Studio或者是VSCode(反正就是编辑器)的编码格式需要时UTF-8的才可以识别,不然在Unity中会被识别为乱码而无法识别。
这个工具通过Unity编辑器菜单系统创建入口点,启动后显示一个自定义EditorWindow窗口,允许用户指定搜索路径。当用户点击"开始遍历项目"按钮时,工具首先使用DirectoryInfo和FileInfo类递归遍历指定目录下的所有.cs文件(排除包含"FindChineseTool"的文件),将它们添加到待处理列表。然后在Update方法中实现分帧处理机制,每帧处理4个文件,避免大型项目中界面卡顿。对于每个文件,使用File.ReadAllLines以Encoding.Default编码读取内容,逐行分析,跳过各类注释行,通过正则表达式"\"[^\"]\""匹配双引号内的内容,并使用"[\u4e00-\u9fa5]"正则表达式检测是否包含中文字符。当发现中文字符串时,通过Debug.Log输出到Console窗口,同时使用StreamWriter将相关信息(字符串内容、文件路径、行号、代码行)以CSV格式写入临时文件。
Excel导表工具
把Excel表格转换成在开发中实际会使用到的数据类型如C#脚本,XML格式文件或者二进制格式的文件对于程序来说是必需的,我们来看看如何实现:
我们当然首先需要一个Excel文件:

文件路径如下:
接着我们在Unity中执行一些脚本之后得到的输出:
这两个就是我们生成的C#脚本和二进制文件。
实现这两个转换功能的脚本代码非常的长啊,我来总结一下比较重要的几点:
static void Excel2CsOrXml(bool isCs){string[] excelPaths = Directory.GetFiles(ExcelDataPath, "*.xlsx");for (int e = 0; e < excelPaths.Length; e++){//0.读Excelstring className;//类型名string[] names;//字段名string[] types;//字段类型string[] descs;//字段描述List<string[]> datasList;//数据try{string excelPath = excelPaths[e];//excel路径 className = Path.GetFileNameWithoutExtension(excelPath).ToLower();FileStream fileStream = File.Open(excelPath, FileMode.Open, FileAccess.Read);IExcelDataReader excelDataReader = ExcelReaderFactory.CreateOpenXmlReader(fileStream);// 表格数据全部读取到result里DataSet result = excelDataReader.AsDataSet();// 获取表格列数int columns = result.Tables[0].Columns.Count;// 获取表格行数int rows = result.Tables[0].Rows.Count;// 根据行列依次读取表格中的每个数据names = new string[columns];types = new string[columns];descs = new string[columns];datasList = new List<string[]>();for (int r = 0; r < rows; r++){string[] curRowData = new string[columns];for (int c = 0; c < columns; c++){//解析:获取第一个表格中指定行指定列的数据string value = result.Tables[0].Rows[r][c].ToString();//清除前两行的变量名、变量类型 首尾空格if (r < 2){value = value.TrimStart(' ').TrimEnd(' ');}curRowData[c] = value;}//解析:第一行类变量名if (r == 0){names = curRowData;}//解析:第二行类变量类型else if (r == 1){types = curRowData;}//解析:第三行类变量描述else if (r == 2){descs = curRowData;}//解析:第三行开始是数据else{datasList.Add(curRowData);}}}catch (System.Exception exc){Debug.LogError("请关闭Excel:" + exc.Message);return;}if (isCs){//写CsWriteCs(className, names, types, descs);}else{//写XmlWriteXml(className, names, types, datasList);}}AssetDatabase.Refresh();}这段代码的功能是批量读取指定目录下的Excel文件,并根据参数生成C#类或XML数据文件:首先通过Directory.GetFiles遍历所有.xlsx文件路径,使用ExcelDataReader库(核心API为ExcelReaderFactory.CreateOpenXmlReader)将每个Excel内容解析到DataSet对象中,提取前三行分别作为字段名(names)、字段类型(types)和描述(descs),剩余行作为数据存入List<string[]>;随后根据isCs参数调用WriteCs生成C#类代码(包含字段元信息)或WriteXml生成XML结构数据;最终调用AssetDatabase.Refresh(Unity特有API)刷新资源管理器,使生成文件立即可见。
如果只用输出CS文件的话在这个函数之后我们就可以直接调用WriteCs函数即可:
static void WriteCs(string className, string[] names, string[] types, string[] descs){try{StringBuilder stringBuilder = new StringBuilder();stringBuilder.AppendLine("using System;");stringBuilder.AppendLine("using System.Collections.Generic;");stringBuilder.AppendLine("using System.IO;");stringBuilder.AppendLine("using System.Runtime.Serialization.Formatters.Binary;");stringBuilder.AppendLine("using System.Xml.Serialization;");stringBuilder.Append("\n");stringBuilder.AppendLine("namespace Table");stringBuilder.AppendLine("{");stringBuilder.AppendLine(" [Serializable]");stringBuilder.AppendLine(" public class " + className);stringBuilder.AppendLine(" {");for (int i = 0; i < names.Length; i++){stringBuilder.AppendLine(" /// <summary>");stringBuilder.AppendLine(" /// " + descs[i]);stringBuilder.AppendLine(" /// </summary>");stringBuilder.AppendLine(" [XmlAttribute(\"" + names[i] + "\")]");string type = types[i];if (type.Contains("[]")){//type = type.Replace("[]", "");//stringBuilder.AppendLine(" public List<" + type + "> " + names[i] + ";");//可选代码://用_name字段去反序列化,name取_name.item的值,直接返回list<type>。//因为xml每行可能有多个数组字段,这样就多了一层变量item,所以访问的时候需要.item才能取到list<type>//因此用额外的一个变量直接返回List<type>。type = type.Replace("[]", "");stringBuilder.AppendLine(" public List<" + type + "> " + names[i] + "");stringBuilder.AppendLine(" {");stringBuilder.AppendLine(" get");stringBuilder.AppendLine(" {");stringBuilder.AppendLine(" if (_" + names[i] + " != null)");stringBuilder.AppendLine(" {");stringBuilder.AppendLine(" return _" + names[i] + ".item;");stringBuilder.AppendLine(" }");stringBuilder.AppendLine(" return null;");stringBuilder.AppendLine(" }");stringBuilder.AppendLine(" }");stringBuilder.AppendLine(" [XmlElementAttribute(\"" + names[i] + "\")]");stringBuilder.AppendLine(" public " + type + "Array _" + names[i] + ";");}else{stringBuilder.AppendLine(" public " + type + " " + names[i] + ";");}stringBuilder.Append("\n");}stringBuilder.AppendLine(" public static List<" + className + "> LoadBytes()");stringBuilder.AppendLine(" {");stringBuilder.AppendLine(" string bytesPath = \"" + BytesDataPath + "/" + className + ".bytes\";");stringBuilder.AppendLine(" if (!File.Exists(bytesPath))");stringBuilder.AppendLine(" return null;");stringBuilder.AppendLine(" using (FileStream stream = new FileStream(bytesPath, FileMode.Open))");stringBuilder.AppendLine(" {");stringBuilder.AppendLine(" BinaryFormatter binaryFormatter = new BinaryFormatter();");stringBuilder.AppendLine(" all" + className + " table = binaryFormatter.Deserialize(stream) as all" + className + ";");stringBuilder.AppendLine(" return table." + className + "s;");stringBuilder.AppendLine(" }");stringBuilder.AppendLine(" }");stringBuilder.AppendLine(" }");stringBuilder.Append("\n");stringBuilder.AppendLine(" [Serializable]");stringBuilder.AppendLine(" public class " + AllCsHead + className);stringBuilder.AppendLine(" {");stringBuilder.AppendLine(" public List<" + className + "> " + className + "s;");stringBuilder.AppendLine(" }");stringBuilder.AppendLine("}");string csPath = CsClassPath + "/" + className + ".cs";if (File.Exists(csPath)){File.Delete(csPath);}using (StreamWriter sw = new StreamWriter(csPath)){sw.Write(stringBuilder);Debug.Log("生成:" + csPath);}}catch (System.Exception e){Debug.LogError("写入CS失败:" + e.Message);throw;}}这段代码的执行流程为:通过 StringBuilder 动态构建C#类代码字符串,首先添加必要的命名空间引用(如 System.Xml.Serialization),定义包含 [Serializable] 标记的主类及字段,其中字段处理逻辑为核心——遍历字段名、类型及描述,若字段为数组(如 int[]),生成 List<T> 属性及配套的 [XmlElement] 辅助字段(如 _nameArray)以适配XML嵌套结构,同时为每个字段添加XML注释(<summary>)及序列化属性([XmlAttribute] 或 [XmlElement]);随后生成 LoadBytes 方法,利用 BinaryFormatter.Deserialize 从 .bytes 文件反序列化数据,并依赖配套的包装类(如 allPerson)存储列表;最终通过 StreamWriter 将代码写入 .cs 文件,调用 File 类覆盖旧文件并记录日志。底层逻辑围绕代码生成与序列化适配,通过反射无关的字符串拼接实现动态类构建,结合 XmlSerializer 属性控制序列化格式,BinaryFormatter 实现高效二进制存储,涉及API包括 System.Text.StringBuilder(代码拼接)、System.IO.File/StreamWriter(文件读写)、System.Xml.Serialization 属性(XML配置)及 System.Runtime.Serialization.Formatters.Binary(二进制反序列化)。
但如果是要生成二进制文件的话我们还额外需要一个生成XML文件的过程,究其原因说白了就是.NET平台内置的XmlSerializer可以帮助我们把XML文件序列化时进行安全的转换,或者说.NET针对XML文件的序列化/反序列化而不支持直接从xlsx文件转换成二进制文件。

static void WriteXml(string className, string[] names, string[] types, List<string[]> datasList){try{StringBuilder stringBuilder = new StringBuilder();stringBuilder.AppendLine("<?xml version=\"1.0\" encoding=\"utf-8\"?>");stringBuilder.AppendLine("<" + AllCsHead + className + ">");stringBuilder.AppendLine("<" + className + "s>");for (int d = 0; d < datasList.Count; d++){stringBuilder.Append("\t<" + className + " ");//单行数据string[] datas = datasList[d];//填充属性节点for (int c = 0; c < datas.Length; c++){string type = types[c];if (!type.Contains("[]")){string name = names[c];string value = datas[c];stringBuilder.Append(name + "=\"" + value + "\"" + (c == datas.Length - 1 ? "" : " "));}}stringBuilder.Append(">\n");//填充子元素节点(数组类型字段)for (int c = 0; c < datas.Length; c++){string type = types[c];if (type.Contains("[]")){string name = names[c];string value = datas[c];string[] values = value.Split(ArrayTypeSplitChar);stringBuilder.AppendLine("\t\t<" + name + ">");for (int v = 0; v < values.Length; v++){stringBuilder.AppendLine("\t\t\t<item>" + values[v] + "</item>");}stringBuilder.AppendLine("\t\t</" + name + ">");}}stringBuilder.AppendLine("\t</" + className + ">");}stringBuilder.AppendLine("</" + className + "s>");stringBuilder.AppendLine("</" + AllCsHead + className + ">");string xmlPath = XmlDataPath + "/" + className + ".xml";if (File.Exists(xmlPath)){File.Delete(xmlPath);}using (StreamWriter sw = new StreamWriter(xmlPath)){sw.Write(stringBuilder);Debug.Log("生成文件:" + xmlPath);}}catch (System.Exception e){Debug.LogError("写入Xml失败:" + e.Message);}}static void WriteBytes(){string csAssemblyPath = Application.dataPath + "/../Library/ScriptAssemblies/Assembly-CSharp.dll";Assembly assembly = Assembly.LoadFile(csAssemblyPath);if (assembly != null){Type[] types = assembly.GetTypes();for (int i = 0; i < types.Length; i++){Type type = types[i];if (type.Namespace == "Table" && type.Name.Contains(AllCsHead)){string className = type.Name.Replace(AllCsHead, "");//读取xml数据string xmlPath = XmlDataPath + "/" + className + ".xml";if (!File.Exists(xmlPath)){Debug.LogError("Xml文件读取失败:" + xmlPath);continue;}object table;using (Stream reader = new FileStream(xmlPath, FileMode.Open)){//读取xml实例化table: all+classname//object table = assembly.CreateInstance("Table." + type.Name);XmlSerializer xmlSerializer = new XmlSerializer(type);table = xmlSerializer.Deserialize(reader);}//obj序列化二进制string bytesPath = BytesDataPath + "/" + className + ".bytes";if (File.Exists(bytesPath)){File.Delete(bytesPath);}using (FileStream fileStream = new FileStream(bytesPath, FileMode.Create)){BinaryFormatter binaryFormatter = new BinaryFormatter();binaryFormatter.Serialize(fileStream, table);Debug.Log("生成:" + bytesPath);}if (IsDeleteXmlInFinish){File.Delete(xmlPath);Debug.Log("删除:" + bytesPath);}}}}
WriteXml函数负责将Excel数据转换成XML格式,它通过StringBuilder高效构建XML字符串,将普通字段作为XML属性处理,而数组类型字段则拆分为嵌套元素结构(使用#符号分隔数组元素);随后,WriteBytes函数接管这个XML文件并完成二进制转换,它首先通过反射机制加载Assembly-CSharp.dll程序集,查找符合条件的"Table"命名空间下带有"all"前缀的类型,利用XmlSerializer将XML反序列化为对象,然后使用BinaryFormatter将对象序列化为二进制文件,最后根据配置选择是否删除中间XML文件。这两个函数协同工作构成了完整的数据转换管道,巧妙利用了.NET的类型系统和序列化机制,确保了类型安全和高效处理,同时通过反射实现了配置表名与类名的自动映射,使整个过程既保证数据完整性又优化了运行时性能。
上述内容针对的是Excel文件内容转变成CS文件乃至二进制的方法,那我们能否从二进制文件直接获取得到信息使用呢?
using System.Collections;
using System.Collections.Generic;
using Table;
using UnityEngine;public class readBytesTest : MonoBehaviour
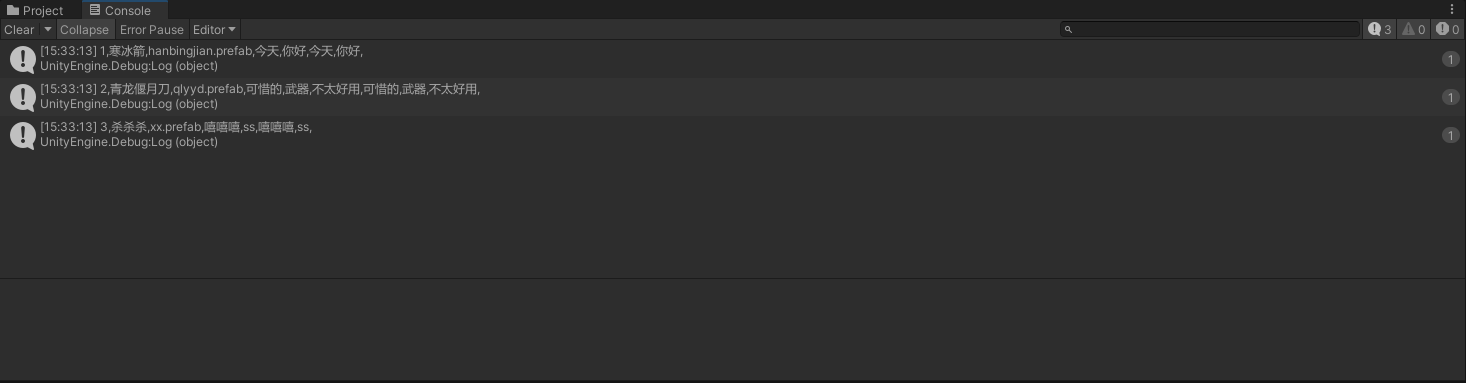
{// Start is called before the first frame updatevoid Start(){List<weapon> weapons = weapon.LoadBytes();for (int i = 0; i < weapons.Count; i++){weapon w = weapons[i];string log = w.id + "," + w.name + "," + w.prefabName + ",";for (int d = 0; d < w.desc.Count; d++){log += w.desc[d] + ",";}for (int n = 0; n < w.desc.Count; n++){log += w.desc[n] + ",";}Debug.Log(log);}}
}
public static List<weapon> LoadBytes(){string bytesPath = "D:/Downloads/UnityExcel2BytesCs/Assets/Resources/DataTable/weapon.bytes";if (!File.Exists(bytesPath))return null;using (FileStream stream = new FileStream(bytesPath, FileMode.Open)){BinaryFormatter binaryFormatter = new BinaryFormatter();allweapon table = binaryFormatter.Deserialize(stream) as allweapon;return table.weapons;}}这个函数的核心就是使用BinaryFormatter将二进制数据反序列化为allweapon对象。
效果如下: