linux之 pcie 总线协议基础知识
一、pcie 总线架构
在读pcie 相关文档时,发现了一篇比较好的文章,在这里摘抄并增加自己实战中的分享和疑问。
pcie 的总线架构,每家SOC厂商可能都不相同;下面就展示一下intel 芯片的总线架构,至于自己公司的总线架构是属于保密的,不方便展示:
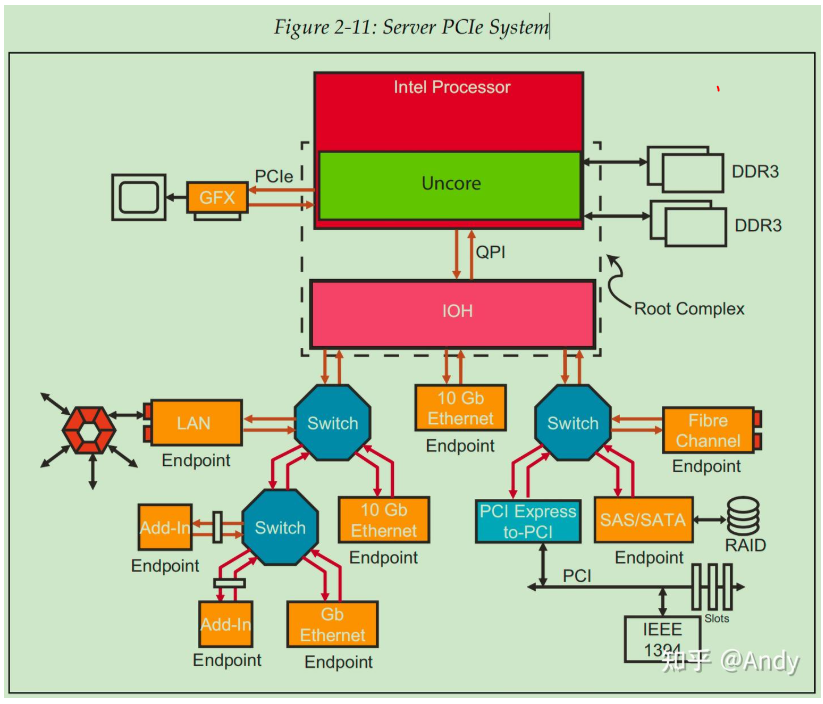
如图 Uncore 和 IOH 组成 PCIe Root Complex。Root Complex 挂接了 PCIe 的 GFX 图像显卡,DDR3 内存,两个 PCIE switch,以及一个 10Gb Ethernet PCIe endpoint。如果通过 lspci -tv 查看,会发现以上PCIe 设备(endpoint 和 switch)挂在PCIe Bus 0上.
可以看出DDR3 内存控制器集成在 Processor 内,IOH对PCIe 进行扩展,最多支持 36 lanes(一个PCIe 设备最多支持 32 lanes)。Lane 是PCIe 串行传递数据的链路,下文将详细介绍。Core 和 IOH之间通过 QPI (Quick Path Interface)总线相连,速率是 25.6GB/s。IOH 和 ICH 之间通过 DMI(Direct Media Interface) 相连,ICH 支持扩展 6个 PCIe x1 的接口(x1 和 lane1 是等同的,PCIe 不同版本的单条 Lane 支持的带宽是不同的,例如PCIe 3.0 支持 8GT/s,GT的意义下文将介绍)以及 USB、SATA、网络等芯片接口。
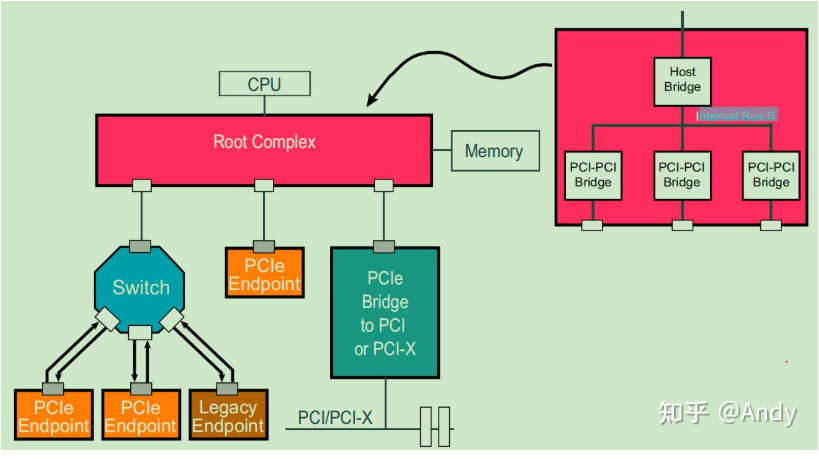
在X86 的处理器架构上,Host/Root Bridge 通过 内部总线0,连接到各个PCIe brdige,再扩展出新的总线1,2,3....
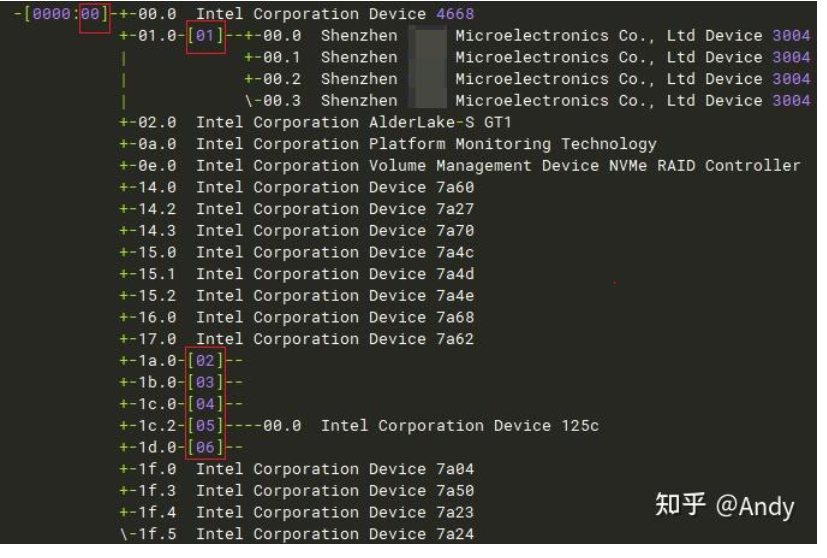
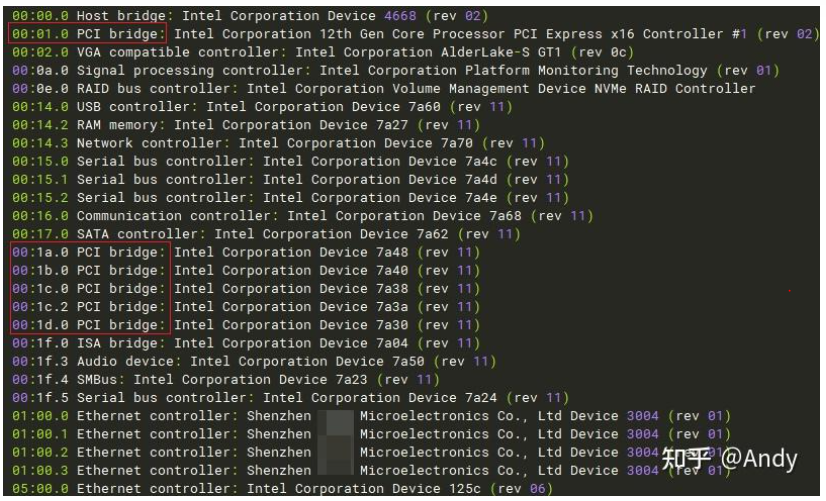
我们可以使用 linux 的命令 lspci -tv 查看当前主机的PCIe 总线树型结构,如下图前面的 0000:00 表示 Domain 0 (2个byte)的 总线 0(一个byte),而总线 0 下面总共挂接了 22 个PCIe 设备和 PCI-PCI brdige。如何识别下图中哪些 PCIe Bridge,哪些是 PCIe device,方法就是看总线号(如下面的 [01], [02], [03]....),每条总线的上面一层都是 Bridge,即总线是挂在 Bridge 下面,如下图中PCIe设备 00:01.0 是一个 PCIe bridge,其下面挂接的是总线 [01](1个byte),对应的设备号是 00(5bit),function 从 0~3(3bit).
# lspci -tv
# lspci
二、pcie 物理链路
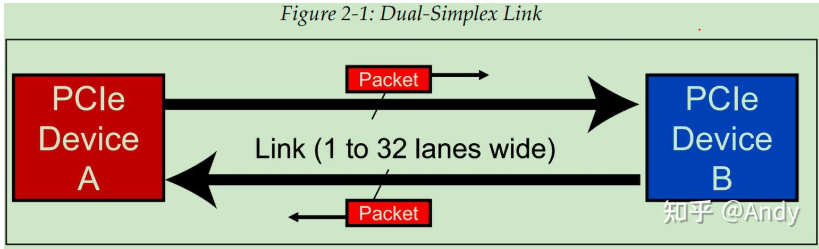
上文提到PCIe Lane 是指在两个PCIe 设备之间,用于传递数据的端到端的链路。如下图,两个PCIe设备之间的Link Width可以支持 1, 2, 4, 8, 12, 16, or 32 Lanes。Lane又被称为链路带宽,通常被表示为 x1, x2, x4, x8, x16, and x32。
PCIe总线使用端到端的连接方式,互为接收端和发送端,全双工,基于数据包的传输;物理底层采用差分信号传递数据(PCI链路采用并行总线,而PCIe链路采用串行总线),一条Lane中有两组差分信号,共四根信号线;
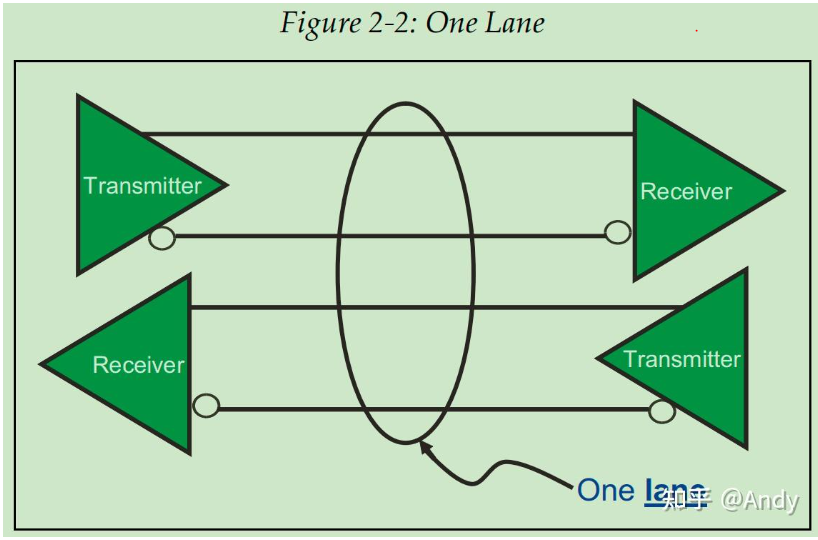
Transmiter(TX)和 Receiver(RX)Logical 位于PCIe最底部的物理层(Physical Layer),在传递物理信号“1”和“0” 给对端设备时,采用两个差分信号线传递一个信号值,基于两个差分信号的电压差值表示“1”或“0”。重点是,在提到One Lane的时候,我们一定要想到在物理上就是对应着4条信号线,TX占用两根,RX占用两根,进行信号的串行传递。如果是多条Lane的时候(如Lane4 或 x4),则TX和RX分别有8根信号线串行传递数据,两根信号线一起传递一个信号位,当有4位的bit流需要传递时,则x4的带宽可以一次传递完成,而x1需要传递4次。
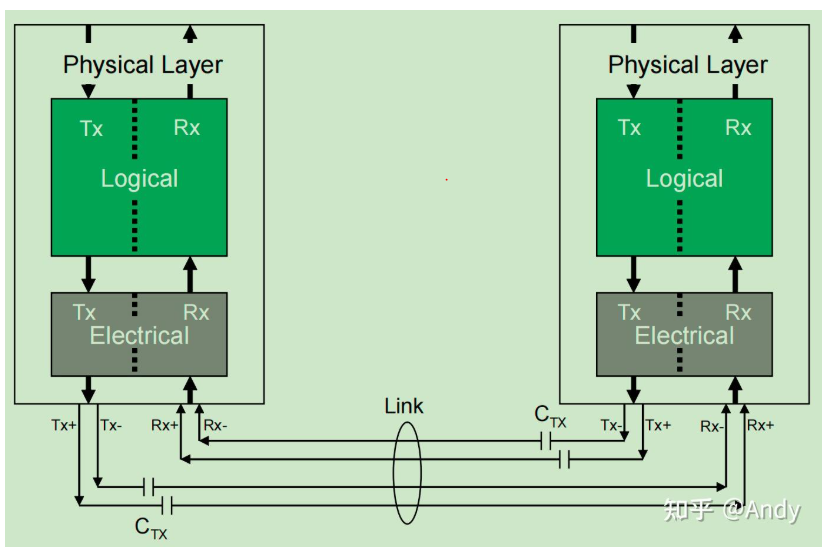
提一个问题: phy 与lan 之间关系, 是一对多还是一对一?
个人理解: phy 与lan 是一对多或者 一对一的关系, 物理层可以有很多条lan进行数据收发。
三、pcie 速率计算
这个比较简单,不做具体计算;
我们在看到任何一个PCIe 设备之后,通过 其传输速率和Lane的数量,就可以得知其吞吐量是多少。传输速率和Lane的数量使用linux lspci 命令可以获得:sudo lspci -s 07:00.1 -vvv
如下图该PCIe 设备的物理层的LinkSta(连接状态)是 8GT/s,Width 是 x8,通过这两个值,我们需要一眼就知道这是一个运行在 PCIe Gen3 的设备,有 8条 lane 在工作。通过这些信息,读者可自行计算实时的吞吐量进行练习。为什么称为实时吞吐量,如果该PCIe 设备插在一个 PCIe Gen 2 的x4的插槽上,我们会发现 LinkSta是 5GT/s,Width 是 x4。这时 PCIe 设备就是降速工作,所以我们前面介绍了这一堆PCIe 物理层的知识,目的就是要让你具有一眼就看穿事物本质的能力,看穿当前设备是否工作在其本身具有的真实能力上。如下图的设备真实能力是 linkCap:Speed 8GT/s,Width x8,而当前工作能力LinkSta也是一样的。
sudo lspci -s 07:00.1 -vvv
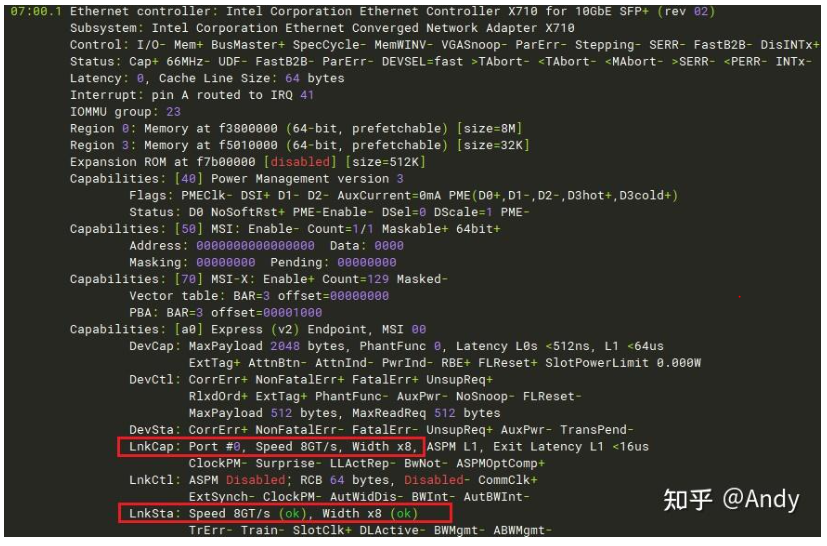
目前只要会看 pcie设备是否降速;
四、pcie 地址空间 (重点)
就PCIe 总线上的设备(包括RC,Bridge,Device)来说,涉及的地址空间主有三种。
- 第一种是配置空间(PCIe Bridge/Device Configuration Space),这一部分是PCIe 协议规范定义的,用于标识一个PCIe 设备(如Vendor ID,Device ID),并包括协议运行时的统计和配置参数(如AER 的错误统计,Maxpayload Size等)。
- 第二种是BAR(base address register) 空间,对于一个以PCIe 协议为数据传输桥梁的GPU,网卡,SSD等设备,其芯片内部的寄存器地址空间,会通过BAR的方式映射出来,可以提供给驱动程序作为管理接口进行读写操作。
- 第三种是存储域空间,也是非常重要的地址空间,待发送的网络数据报文,待写入磁盘的数据,全部在主机的内存DRAM中,对于PCIe 设备可以进行DMA读写的内存,这就是PCIe设备和CPU读写可以访问的存储域地址空间。
4.1 pcie 配置空间
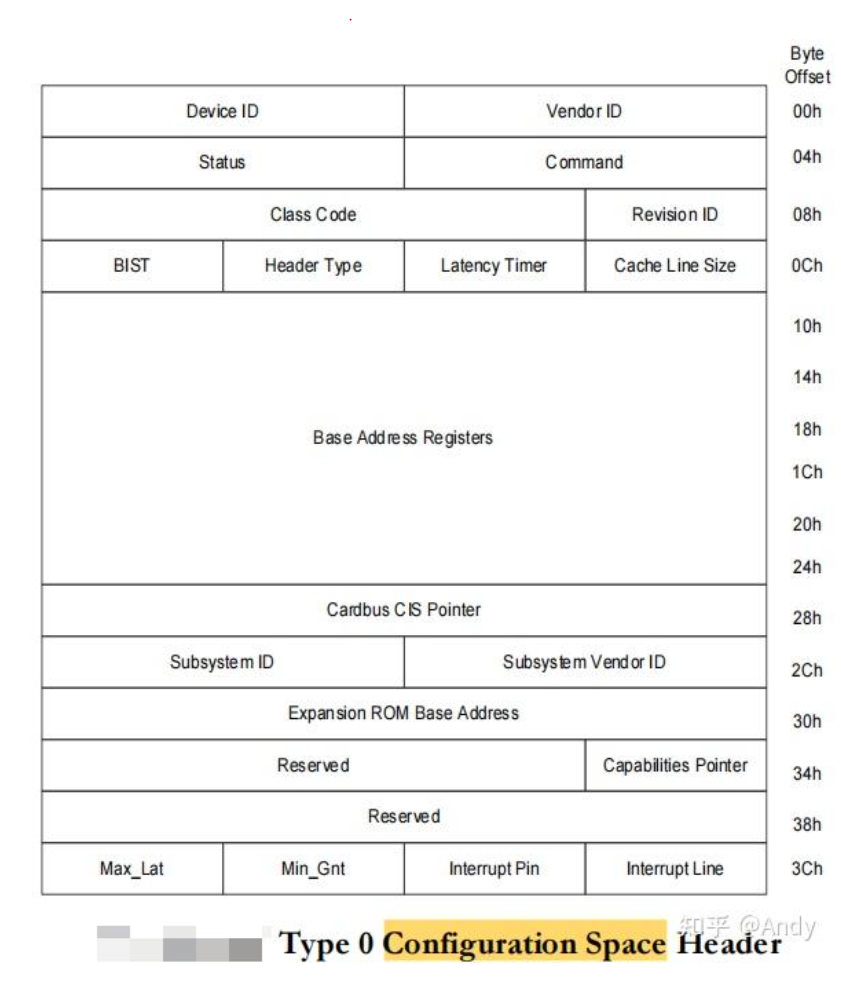
PCIe 配置空间位于PCIe芯片的内部寄存器中,存放当前PCIe 设备的身份(如Vendor ID,Device ID)以及状态与配置等信息。
PCIe 配置空间分为三块,起始的 256bytes(16 DWs + 48 DWs)是向前兼容 PCI 的规范,沿用了PCI的定义。首先,开始的 64 btyes(16 DWs),对应着配置空间的头部信息,其中比较重要的,如下图右边蓝色部分:
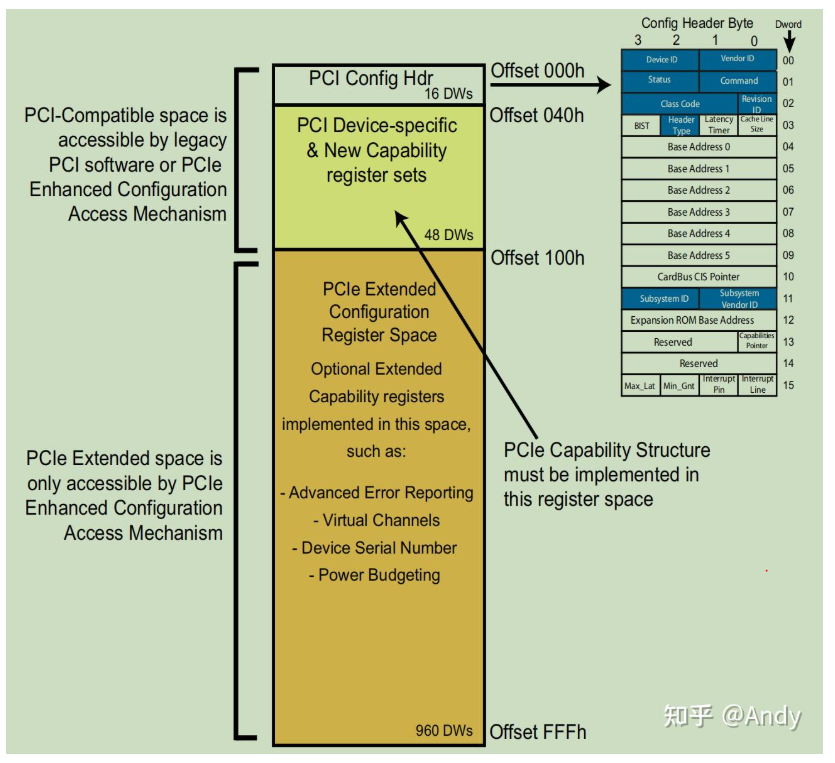
- Vendor ID:PCI设备的生产厂商
- Device ID:该厂商所生产的具体设备,如不同型号的SSD或网卡等
- Command:命令寄存器,控制I/O访问、 Memory访问和中断的使能或者关闭
- Status:状态寄存器,如中断和错误状态
- Class Code:标识 PCI设备类别
- Revision ID:PCI设备的版本号
- Header Type:标识PCI设备类型寄存器
- Expansion ROM Base Address:扩展ROM 映射基地址寄存器
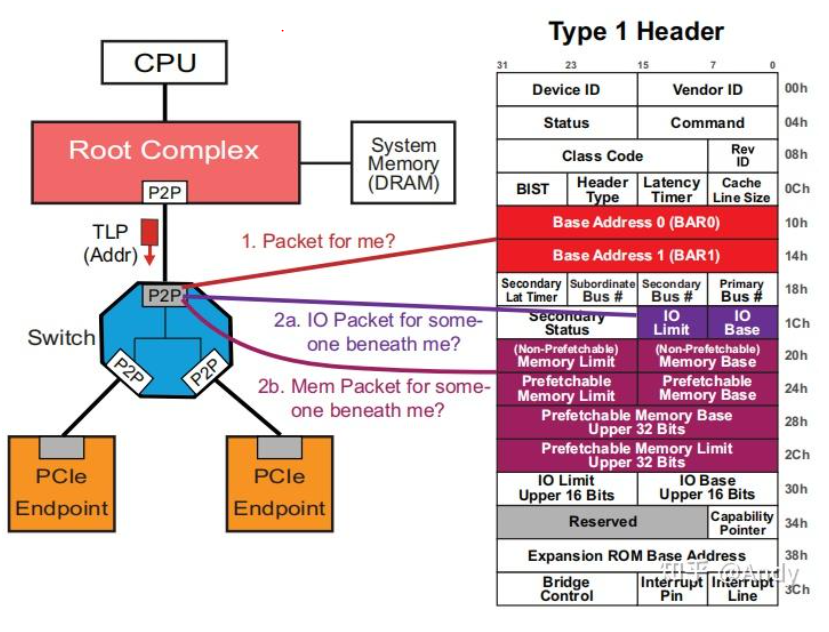
有两种类型的配置空间头部类型:Type 0 Header 用于PCIe 设备节点(endpoint);而 Type 1 Header 用于 PCIe Bridge Device,关于PCIe Bridge的详细描述下文将给出。当前我们重点关注 Type 1 Header 中比较重要的几个寄存器:
- Memory Base:当前PCIe Bridge 管理的所有下游 PCIe 设备 BAR地址的起始地址
- Memory Limit:当前PCIe Bridge管理的所有下游 PCIe 设备 BAR空间对齐后的总大小
- Primary Bus Number:当前PCIe Bridge 上游紧邻总线的 Bus ID
- Secondary Bus Number:当前PCIe Bridge 下游紧邻总线的 Bus ID
- Subordinate Bus Number:当前PCIe Bridge 下游总线的最大Bus ID
以上三种Bus Number下文将进行详细介绍。
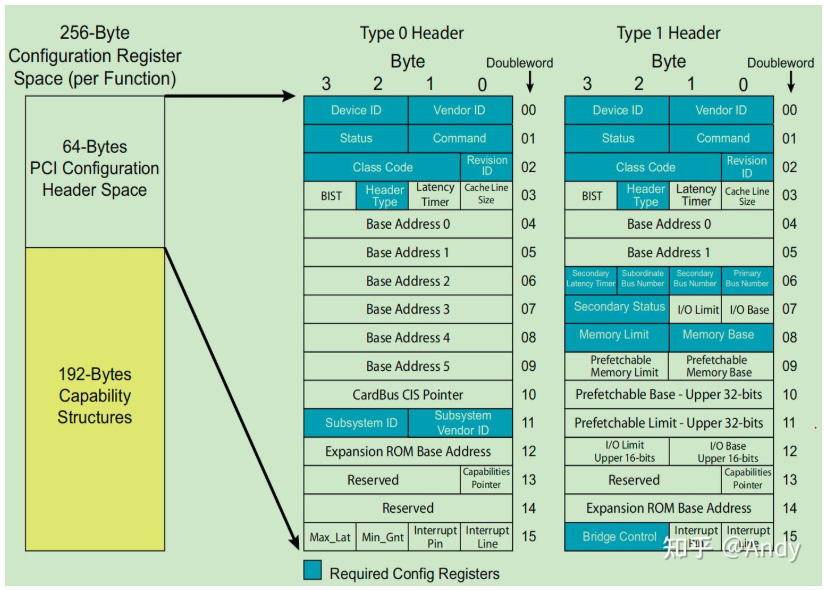
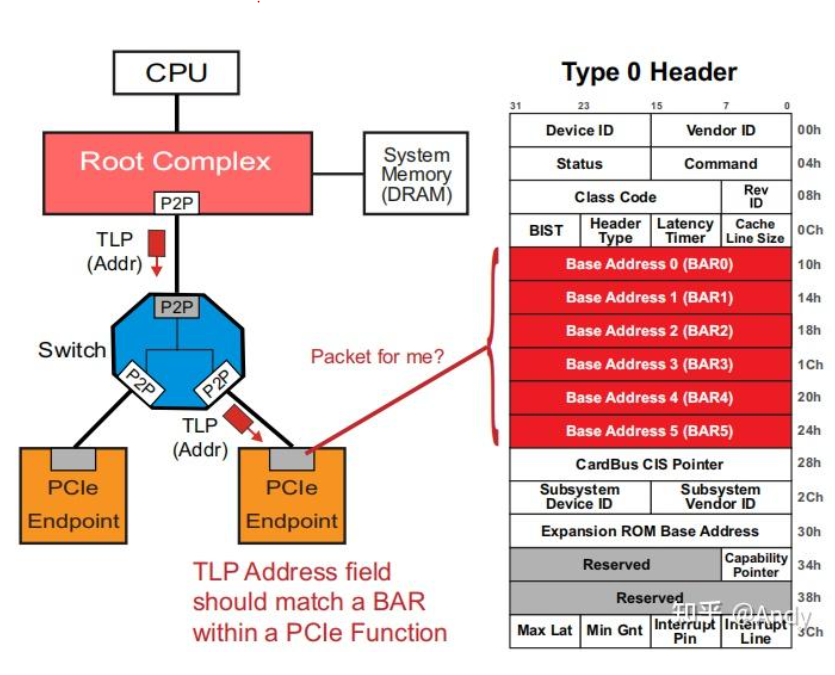
我们还需要清楚的是,Type 1 Header 用于 Bridge或桥,Type 0 用于 PCIe Endpoint即功能设备(如网卡、SSD等):
4.2 pcie bar 空间
PCIe 配置空间中的 Base Address 0~5 为6个基地址寄存器,其中存放着BAR空间起始地址的起始地址。每个Base Address寄存器为 32 bit,最多可以存放6个32位地址(也可支持64位地址模式,即将Base Address 两两合并,成为3个 64位 base address),注意PCIe Base Adress寄存器中的地址,是芯片内部子模块的寄存器地址空间(例如一颗完整的智能网卡芯片,集成了PCIe,MAC,PHY,以太网Engine,RDMA等子模块,或称为子IP,PCIe 子模块可通过配置空间来控制和管理,而其他子模块需要通过PCIe Base Address 寄存器中存放的32位或64位地址 来访问控制和管理)。
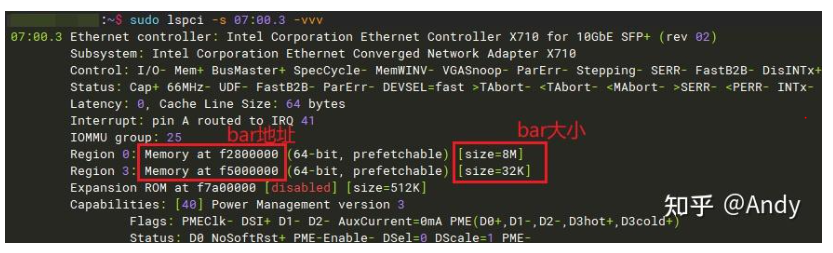
下文将采用BAR地址表示芯片内子模块的寄存器或存储器(芯片内的SRAM寄存器地址空间也可称为存储器)地址空间。CPU针对BAR地址空间,采用和DRAM 统一编址的方式,进行统一的物理地址空间管理,下一节将详细介绍,注意上图是PCIe总线 07,设备 00,功能 3 的Bar0,Bar3,Expansion ROM的地址,下面将展示。
注1:PCIe 设备的编号 07:00.3, 其中 07 占用 8bit,00占用5bit,3占用3个bit。所以一个总线下面最多可以挂32个设备,每个设备最多8个function。
注2:PCIe Bar空间一般会通过固件映射到芯片内部SRAM存储空间(我们通常称为芯片寄存器)的一段固定地址区域(下图在后面章节将详细介绍):
Base Address 寄存器中的数值(BAR地址)是谁进行分配的,是什么时候进行分配的,该地址空间的大小在PCIe配置空间中并没有一个专门的寄存器进行记录,又是如何知道其size是8M还是32K的呢?下文将进行介绍。
4.3 存储域地址空间
对于主机CPU指令可以读写访问所有存储器介质,进行统一编址后的物理地址空间,我们称之为存储域地址空间。这包括了CPU内部通用寄存器、主存储器DRAM、外部设备存储空间等。针对以PCIe总线互联的系统,我们将主要关注PCIe设备Bar地址空间和DRAM内存空间。例如对于X86的Linux主机系统来说,伙伴系统将DRAM内存分为三个区域,分别是:

- DMA ZONE:16MB
- DMA32 ZONE:4GB以内
- Normal ZOEN:4GB以上
从iomem的输出信息可以看到,物理内存不同区域,以及 PCIe Bar的存储区域,被进行统一编址。例如系统DRAM内存在4GB以内的空间,存在着DMA 和 DMA32 物理内存页的分布:
- 00001000-0009ffff : System RAM
- cb492018-cb4b2857 : System RAM
- ......
- da4d1000-dcffffff : System RAM
在4GB以内的iomem空间中(即物理地址空间),也存在PCIe 设备 Bar 的分布:
- f2800000-f52fffff : PCI Bus 0000:07
- f2800000-f2ffffff : 0000:07:00.3
- f2800000-f2ffffff : i40e
- f2800000-f2ffffff : 0000:07:00.3
以上表示,在PCIe 总线 07 下面,有一个 PCIe 设备 00,Function 3 的地址空间范围是 f2800000-f2ffffff,正好对应 Bar 0 的 8MB 空间大小。Bar 3 和 Expansion ROM 的空间及大小,可以尝试自己从下面找出并计算:
root@lab02:~# cat /proc/iomem
00000000-00000fff : Reserved
00001000-0009ffff : System RAM
000a0000-000fffff : Reserved00000000-00000000 : PCI Bus 0000:00000a0000-000dffff : PCI Bus 0000:00000c0000-000ce9ff : Video ROM000f0000-000fffff : System ROM
00100000-09d01fff : System RAM
09d02000-09ffffff : Reserved
0a000000-0a1fffff : System RAM
0a200000-0a20bfff : ACPI Non-volatile Storage
0a20c000-cb492017 : System RAMbf000000-caffffff : Crash kernel
cb492018-cb4b2857 : System RAM
......
da4d1000-dcffffff : System RAM
dd000000-dfffffff : Reserved
e0000000-f7ffffff : PCI Bus 0000:00e8000000-f1ffffff : PCI Bus 0000:09e8000000-efffffff : 0000:09:00.0f0000000-f1ffffff : 0000:09:00.0f2800000-f52fffff : PCI Bus 0000:07f2800000-f2ffffff : 0000:07:00.3f2800000-f2ffffff : i40ef3000000-f37fffff : 0000:07:00.2f3000000-f37fffff : i40ef3800000-f3ffffff : 0000:07:00.1f3800000-f3ffffff : i40ef4000000-f47fffff : 0000:07:00.0f4000000-f47fffff : i40ef4800000-f49fffff : 0000:07:00.3f4a00000-f4bfffff : 0000:07:00.2f4c00000-f4dfffff : 0000:07:00.1f4e00000-f4ffffff : 0000:07:00.0f5000000-f5007fff : 0000:07:00.3f5000000-f5007fff : i40ef5008000-f500ffff : 0000:07:00.2f5008000-f500ffff : i40ef5010000-f5017fff : 0000:07:00.1f5010000-f5017fff : i40ef5018000-f501ffff : 0000:07:00.0f5018000-f501ffff : i40ef5020000-f509ffff : 0000:07:00.3f50a0000-f511ffff : 0000:07:00.2f5120000-f519ffff : 0000:07:00.1f51a0000-f521ffff : 0000:07:00.0
......
100000000-41f37ffff : System RAM330400000-331402487 : Kernel code331600000-33209afff : Kernel rodata332200000-332649b7f : Kernel data3329b8000-333bfffff : Kernel bss
41f380000-41fffffff : RAM buffer
......
4000000000-7fffffffff : PCI Bus 0000:004000000000-400fffffff : 0000:00:02.04010000000-4010000fff : 0000:00:15.04010001000-4010001fff : 0000:00:15.14010002000-4010002fff : 0000:00:15.26000000000-60dfffffff : 0000:00:02.0如上图,对于Linux内核的代码和数据存放在4GB以上的物理地址空间,Normal ZONE的内存页用于存放这些数据:
- 100000000-41f37ffff: System RAM
- 330400000-331402487: Kernel code
- 331600000-33209afff : Kernel rodata
- 332200000-332649b7f : Kernel data
- 3329b8000-333bfffff : Kernel bss
注: 此处 的iomem 可能和arm64 的有所区别, 但是整个的内存模型是一致,可以参考。
4.4 地址空间和存储空间
PCIe Bar空间,我们也可以称为是 PCIe 总线域存储空间,Linux内核系统将其和DRAM域纯空间 一起编址,产生了我们所提到的存储域地址空间(即物理地址空间)。如下图 16GB的 DRAM,以及5GB PCIe 总线域存储空间一起组成了19GB的存储域地址空间。
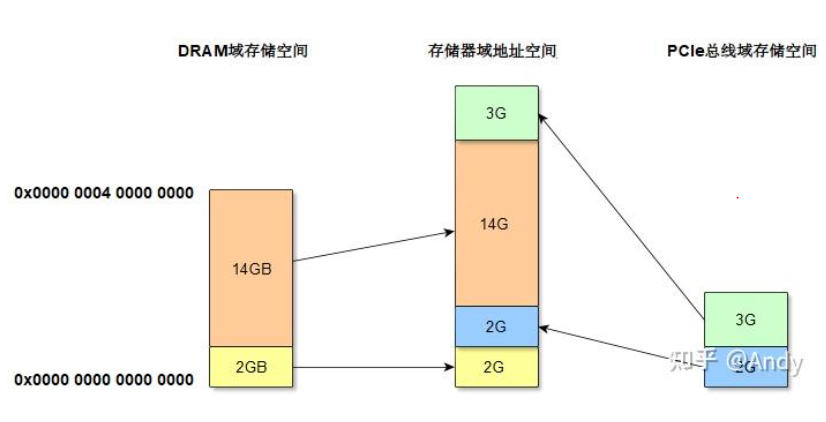
- DRAM域存储空间:通过内存控制器,可以访问的最大内存空间大小。
- PCIe总线域存储空间:主要是由芯片(如网卡,SSD控制器,GPU控制器)内的SRAM空间组成,通过Bar寄存器获取其大小。
- 存储器域地址空间:这个是CPU可以访问的地址空间,Linux系统对DRAM和外设芯片SRAM统一进行编址得到了存储域地址空间,或者称为物理地址空间。对于Linux系统程序员来说,不管是访问DRAM还是PCIe 总线域,编写驱动等代码时,全部使用的是虚拟地址,通过系统接口virt_to_phys 可以将虚拟地址转换为物理地址(存储域地址空间的地址),这种映射映射关系,统一由页表进行管理,通过MMU进行地址翻译,并基于TLB进行缓存加速。
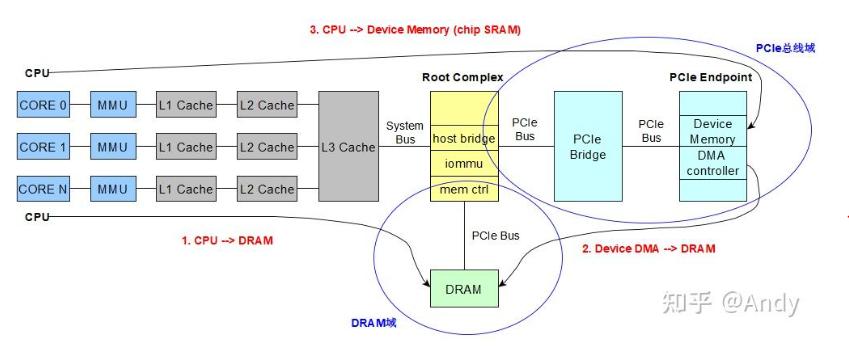
对于PCIe总线域(由Root Complex,PCIe总线,PCIe bridge,PCIe device组成)来说,其中的设备或bridge的存储空间不仅会被CPU访问;设备或bridge还会主动发起请求,对DRAM进行 DMA 访问或者对其他PCIe设备的Bar发起读写请求。所以PCIe设备(包括Bridge)也可被想象成一个CPU,这颗CPU不仅能访问PCIe总线域的存储空间(如图中绿色3G和蓝色2G的空间),也可以访问DRAM的存储空间(图中虚线部分,14GB和2G的空间)。对于X86 或 ARM 的PCIe 总线域来说,如果IOMMU关闭(或者是Passthrough模式)虚线部分的地址空间和存储器域地址空间是一一对应的,即DMA地址(linux内核称为IOVA)和物理地址相等。如果IOMMU开启,Passthrough 模式关闭,则通过IOMMU页表(类似进程虚拟地址到物理地址页表映射)对PCIe 总线域使用的DMA地址和存储器域的物理地址进行映射。就此收住,再写就跑题了,对内核 IOMMU 感兴趣,请参考作者的另外一篇文章《Linux Kernel IOMMU》。如果对PCIe设备的DMA请求感兴趣,请参考 Andy:一文读懂 内存DMA 及 设备内存控制
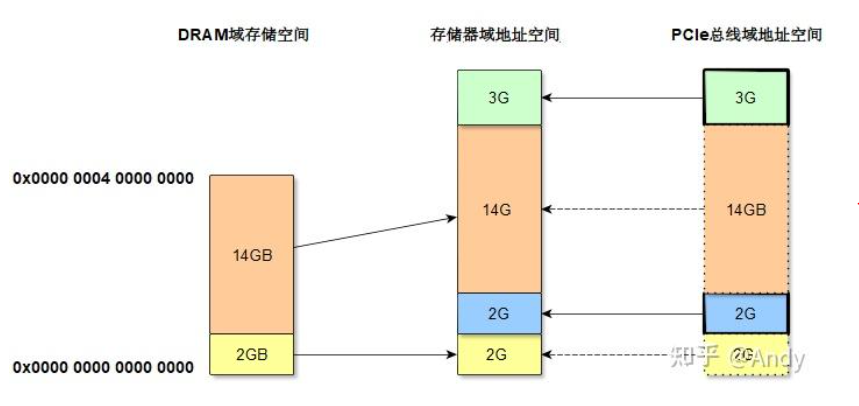
注: 上面的解释主要是告诉 总线地址、存储域地址、cpu 访问的地址空间之间的关系。
五、pcie 设备枚举(重点)
5.1 基本概念
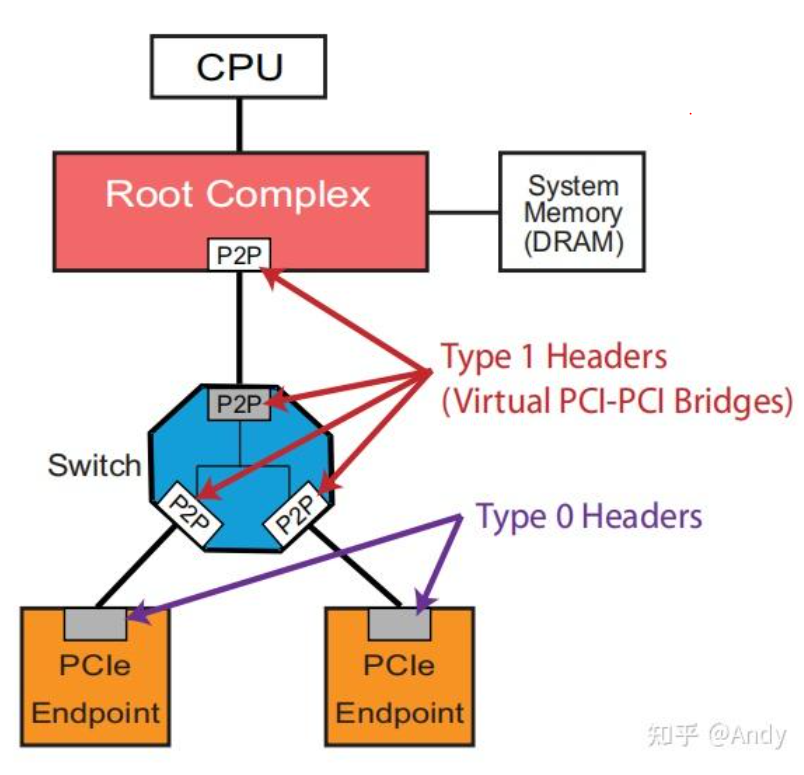
- Root Complex(RC):是连接CPU和内存子系统与PCI Express设备之间的桥梁。从PCIe角度看,其中重要包括了Host Bridge(或称为Root Bridge),Virtual P2P(虚拟PCIe bridge),以及PCIe 总线 0(Bus 0)。当Processor 发出条指令需要读取Bar空间某个地址的寄存器的值,这个读取数据的请求指令,会通过RC生成PCIe 的协议报文,基于PCIe的通路发送给对应的PCIe device。
- Host Bridge(Root Bridge):整个PCIe 树型结构的根节点,通过内部高速总线连接处理器。
- Virtual P2P(PCI Bridge):全称是Virtual PCI‐to‐PCI Bridge (P2P),对应PCI规范中的PCI Bridge,用于连接或者扩展新的总线。在P2P的上行和下行分别为两条不同的总线,P2P的上行总线是Bus 0,下行总线是Bus1。
- PCIe Switch:这是PCIe 协议引入的概念,在PCI规范中只有Bridge,到了PCIe,将多个Bridge组在一起,形成一个Switch。Switch 由多个Virtual P2P 组成,在switch 内部具有流量控制和调度,在不同的bridge端口之间进行流量的转发。
- USP(Upstream Port)& DSP(Downstream Port):PCIe Switch 由多个虚拟的P2P Bridge 组成,每个Bridge 对应Switch的一个端口,上行的称为USP(图中一般用灰色小长方形表示),下行的称为 DSP(用白色小长方形表示)。
- Endpoint(EP):PCIe生成树的叶子节点,或PCIe Device,以用来区分PCI Bridge。
5.2 枚举过程(重点)
PCIe设备(包括bridge)的枚举,对于不同的CPU架构实现方式也不同,例如X86 是在BIOS下实现,而有些CPU例如PowerPC是在Linux内核中实现。PCIe枚举结束后,会形成一个树行结构,枚举过程中会对:
- 树形结构的连接线分配总线号;
- 对PCIe Device 和 Bridge 分配BDF (Bus: Device. Function);
- 为PCIe bridge分配primary、secondary、subordinate bus number。
枚举的过程采用深度优先算法:(Linux 代码在第二章展示)
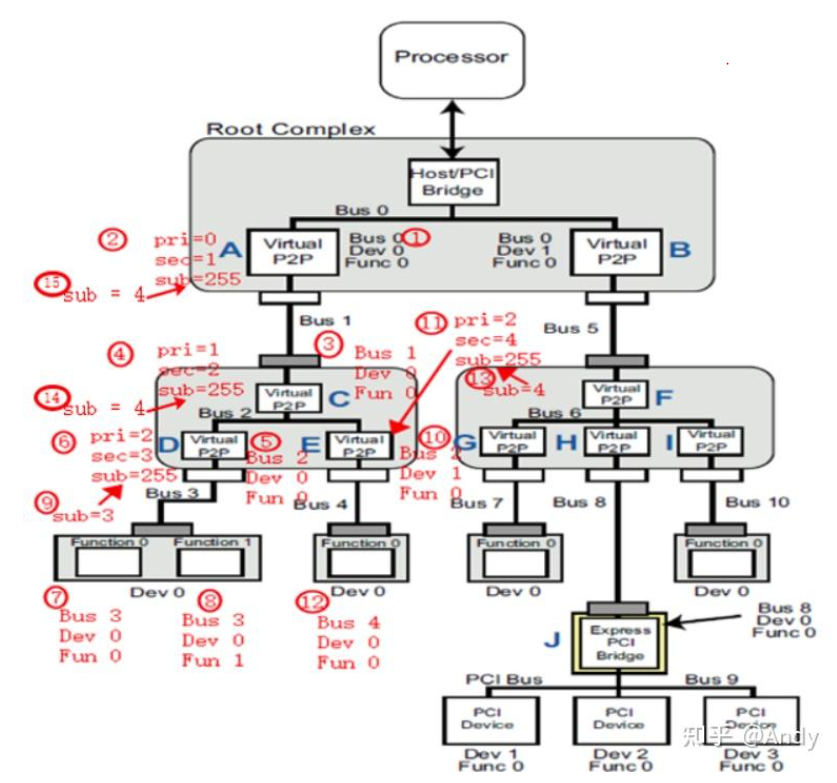
以下分配过程描述,忽略总线号的分配,算法以Root/Host Bridge 作为起点,从Bus number 0开始:
- 首先,以BDF=0:0.0 读取设备A的配置空间寄存器vendor ID和device ID(软件通过配置空间读取得方式判断PCIe设备是否存在)
- 如果设备A的Vendor ID和device ID有效,继续读设备A的配置空间寄存器header type;判断设备C是Bridge还是endpoint,该示例为桥设备,桥设备则初始化设备A配置空间寄存器Primary bus=0,Secondary bus=1,Subordinate bus=255(注意Subordinate bus 后面会修改为正确值)
- 以BDF=1:0.0 读取设备C的配置空间寄存器 vendor ID和device ID
- 设备C的vendor ID和device ID有效,继续读设备C的配置空间寄存器header type,判断设备C是桥设备还是endpoint,该示例为桥设备,桥设备则初始化设备C配置空间寄存器Primary bus=1,Secondary bus=2,Subordinate bus=255
- 以BDF=2:0.0 读取设备D的配置空间寄存器vendor ID和device ID
- 设备D的vendor ID和device ID有效,继续读设备D的配置空间寄存器header type,判断设备D是桥设备还是endpoint,该示例为桥设备,桥设备则初始化设备D配置空间寄存器Primary bus=2,Secondary bus=3,Subordinate bus=255
- 以BDF=3:0.0 读取设备的配置空间寄存器vendor ID和device ID,设备的vendor ID和device ID有效,继续读设备的配置空间寄存器header type,判断设备是桥设备还是endpoint,该示例为endpoint,继续读设备的配置空间判断是single-function设备还是multi-function设备
- 编号7中的设备为multi-function,然后以BDF=3:0.1 读取设备的配置空间寄存器vendor ID和device ID,设备的vendor ID和device ID有效,然后做一些初始化操作
- Bus 3 的设备遍历结束之后,发现桥设备D下最大的bus number为3,则将设备D的配置空间寄存器Subordinate bus=3
- Bus3遍历结束后,回到Bus 2,以BDF=2:1.0 读取设备E,和步骤5类似
- 步骤11和步骤6类似,步骤12和步骤7类似,步骤13&14&15和步骤9类似
注: sub 先设置为255, 后面在返回路径中,进行修改为具体的sub=4;
六、pcie 存储空间地址和大小分配 (重点)
6.1 bar 地址和大小分配方法
系统软件(BIOS 或 Linux 内核)负责对所有PCIe 设备的Bar空间的起始地址和大小进行分配。其实精确的来说,系统软件负责分配Bar空间的起始起始地址(采用前面介绍的存储器统一编址的方式),而Bar空间的大小是PCIe设备决定的:
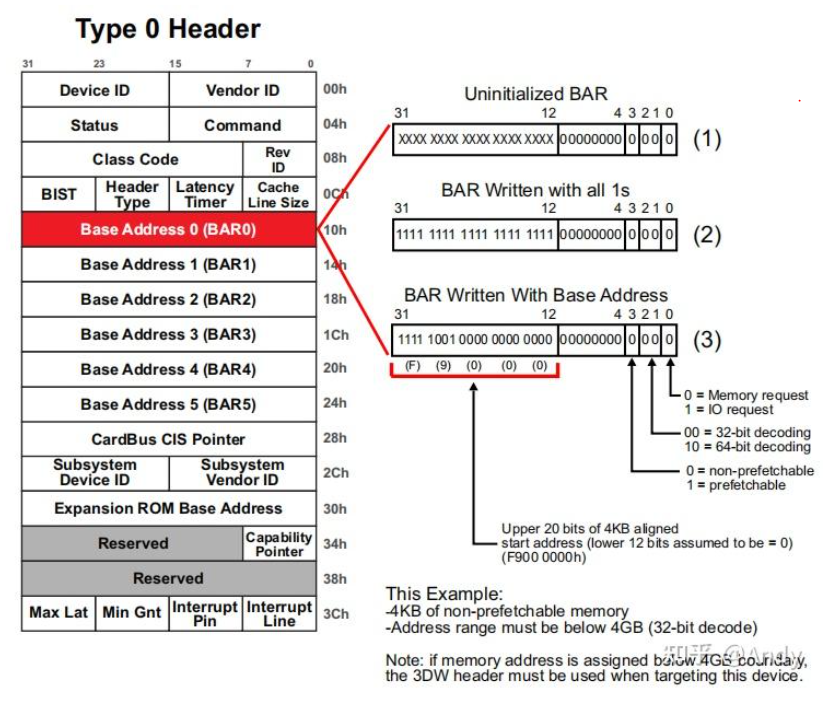
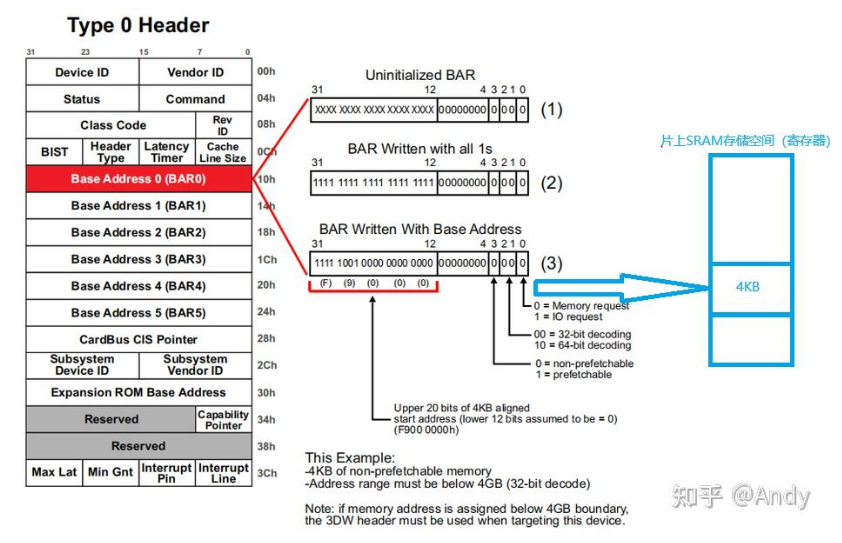
这是一个采用32位地址访问Bar空间的例子,即在存储器域空间中编址为低4GB的地址。系统软件如何基于BAR0寄存器(寄存器仅用于存放Bar空间的起始地址)得知当前BAR 空间的大小的呢?采用的步骤如下:
Step 1:首先系统软件读取配置空间的BAR0 寄存器值,当前是一个未初始化状态(Uninitialized BAR)
Step 2:系统软件对BAR0 所有位全部写1,但是低4位 0~3 无法写入(后面会介绍),如果PCIe设备支持的BAR空间大小是 4KB,则PCIe设备会阻止写入4~11位(保持为0);紧接着系统软件再从BAR0寄存器中读取当前值,发现结果是 0xffff f000;系统软件发觉第一个不为0的bit是12,2^12=4096嘛(4KB),如果bit12也是0,bit13是1,那就表示PCIe设备支持8KB的BAR存储空间。
Step 3:系统软件获取到BAR空间大小之后,会将存储器域分配的地址0xF900 0000 写入BAR寄存器,我们需要清楚是对BAR0访问的地址范围是 0xF900 0000~0xF900 0FF0 (第4~11 bit 为 00 - FF)。注意 0xf9000ff0 - 0xf9000000 = 4k, 地址的变化取决于 第4~11位。
Bar 寄存器最低的4bit具有固定的意义:
- 0:表示当前Bar空间的类型,是 IO 还是 Memory 类型,当前主要使用的是Memory类型
- 1~2:表示Bar空间访问支持的地址宽度是 32bit,还是64bit,这是由PCIe Endpoint设备决定其支持的地址宽度,然后系统软件根据PCIe EP的配置,来决定是分配32bit还是64bit的 存储器域地址。
- 3:确定当前Bar空间包括的存储空间是否可以预取,如果存储空间的寄存器没有读取清除等功能,则可以进行cache预取并加速,这个属性同样是 PCIe EP决定的。

如果PCIe EP支持64bit的地址编码访问Bar空间,则可以将两个Bar寄存器组合使用,例如 Bar 1的 bit 1~2 设置为10,Bar 2 全部用于高32bit的地址编码。Bar1 和 Bar2 组合在一起,被写入系统软件分配的 64bit Bar 空间起始地址,注意起始地址再加上前面提到的系统软件得到的Bar 空间大小,既可得知整个Bar 空间的地址范围。
两个Bar组合在一起获得Bar空间大小和分配64bit 地址的过程和前面Step1~Step3 类似,如下,得到的Bar空间大小是64MB,分配的Bar起始地址是 0x 0000 0002 4000 000C,具体的过程建议自己推导一遍。
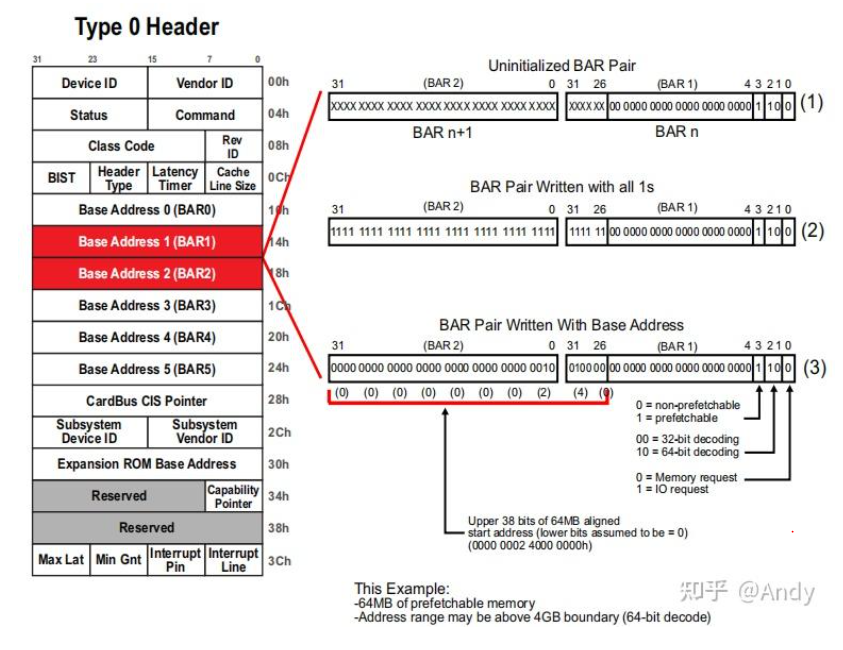
那么PCIe Bar地址分配的具体过程是什么?在PCIe 总线树中除了Bar地址,还有什么其他类型的地址需要分配?分配了这些地址,又是如何使用的,一个PCIe TLP 报文,是怎么基于地址路由到各个PCIe设备的?后面将详细介绍。
6.2 地址分配过程
我们将主要关注PCIe Device Bar寄存器中地址 和 Bridge Base/Limit 寄存器中地址分配的过程。前面一小节,我们只介绍了Bar寄存器中地址会被系统软件分配,但是分配的过程没有介绍。
分配的过程和PCIe枚举创建总线树的过程类似,也是使用的深度优先算法:
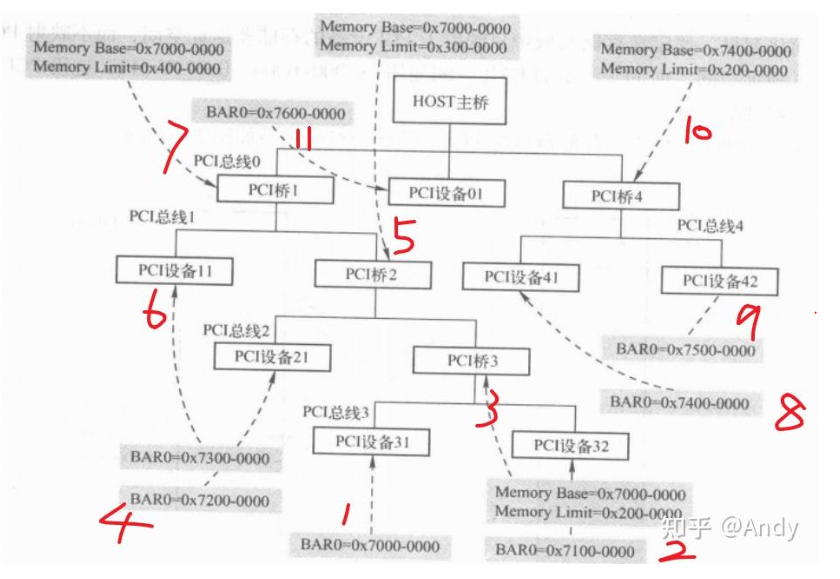
深度优先算法,从PCI总线0的最左侧PCI桥1开始向下扫描,最终扫描到最大的PCI总线3。在总线3下面再也没有PCI桥,所以总线3是最底层的总线号。上图我们假设每个PCI设备只有一个Bar0需要分配地址,而且每个BAR对应空间大小16MB (0x100 0000)。
- 首先对PCI总线3的左子树 PCI设备31 分配BAR空间的起始地址 0x7000 0000
- 对右子树 PCI 设备32分配BAR0 的起始地址 0x7000 0000 (在分配的同时也会按照前面描述的方法,计算BAR 空间的大小Size,这边就忽略了)
- 到了比较重要的一步,PCI总线3 的下挂设备全部分配完成地址和大小之后,深度优先的递归算法,会回到PCI桥3,对PCI桥3设置 Memory Base 和 Memory Limit(这两个寄存器的意义前面介绍过,可回查),Memory Base等于下面总线扩展PCI设备的起始BAR地址,而Limit等于所有BAR空间大小Size的总和。所以PCI桥3的 Base=0x7000 0000,Limit = 0x200 0000。
- 回到PCI总线2,对最左侧 PCI设备21 分配BAR0起始地址0x7200 0000 = (0x7000 0000 + 0x200 0000)
- 对PCI桥2 设置 Memory Base 和 Memory Limit,对于桥2来说,其Base为下面挂接所有设备的起始地址0x7000 0000,Limit 为 总大小 0x300 0000
- 回到PCI总线1,分配PCI设备11 的 BAR0 起始地址 0x7300 0000
- 对PCI桥1 设置 Memory Base 和 Memory Limit (请读者自己尝试计算)
- 回到PCI总线0,扫描总线0 的下一个 PCI Bridge即 桥4 (注意总线0下面的PCI设备01暂时略过),继续采用深度优先算法,分配PCI总线4下面的PCI设备41 的BAR0 起始地址 0x7400 0000
- 分配PCI设备42 的 BAR0 = 0x7500 0000
- 对PCI桥4 设置 Memory Base 和 Memory Limit (请读者自己尝试计算)
- 最后分配PCI分配PCI设备01 的 BAR0 = 0x7600 0000
有2个疑问: bar 地址大小和基地址 与桥的base_mem 和base_limit 是不是同时进行的?
分配的PCI设备01 的BAR0的地址是写在设备树中还是 根据PCIE的地址空间分配的?
上面的两个疑问在第二章的Linux 代码分析时给出答案。
七、PCIE协议基础
7.1 pcie 协议分层
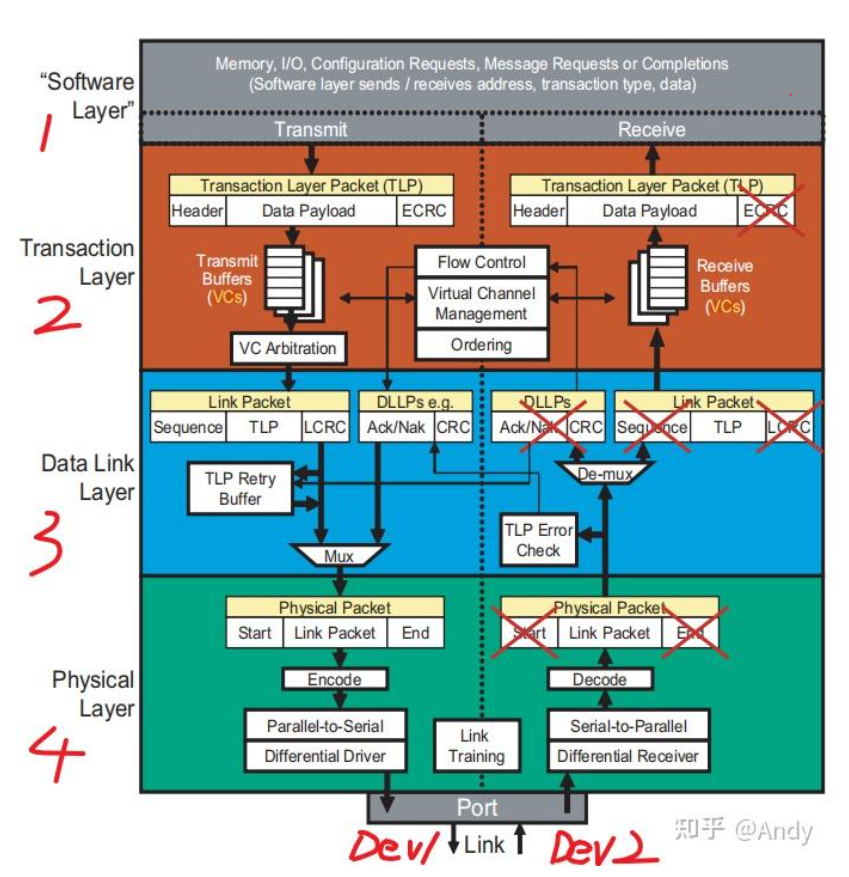
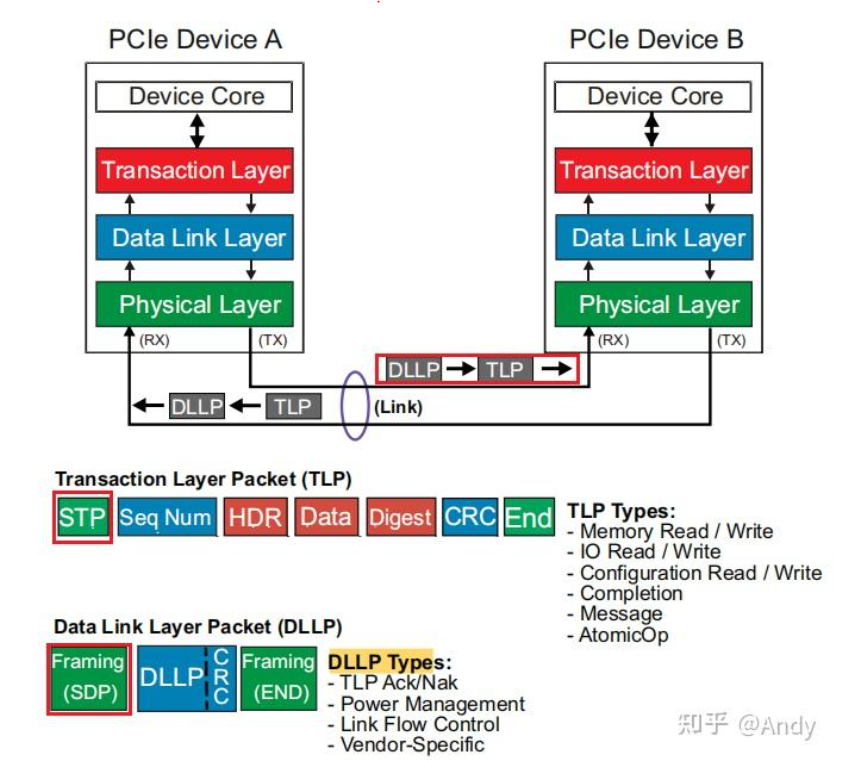
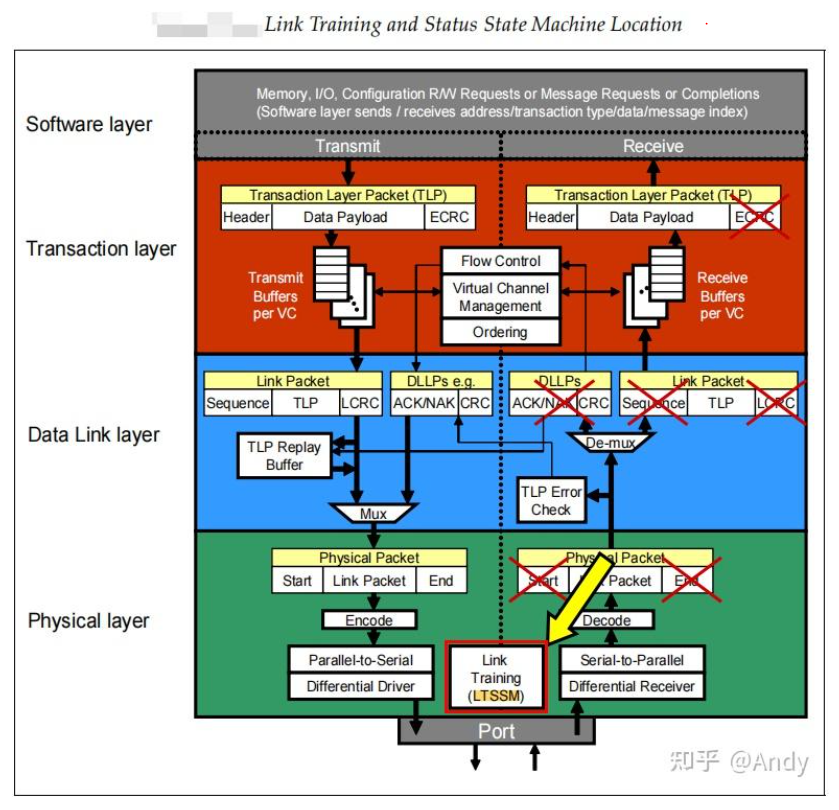
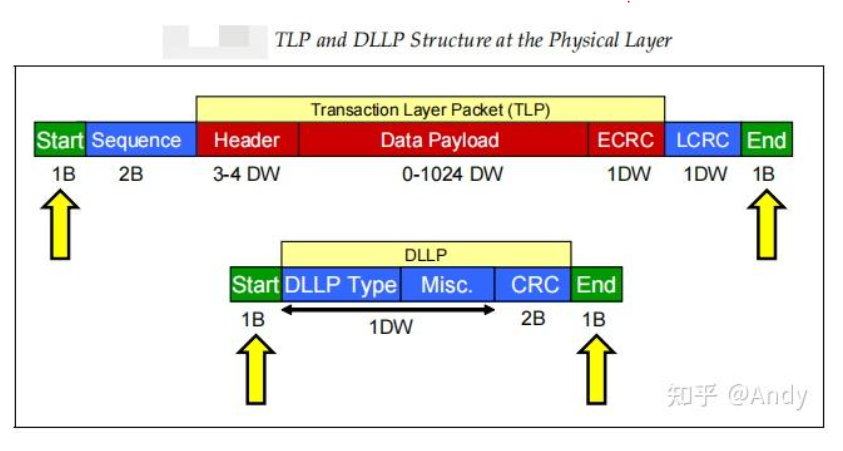
PCIe协议和TCP/IP网络协议非常的类似,如果你有网络协议的基础,将很容易理解PCIe协议。TCP/IP 协议的封装和解封装是在系统软件中实现,但是PCIe协议头的封装和解封装是由芯片内部的逻辑电路实现,作为计算机系统外设的内部互联总线,通过逻辑电路实现的协议才可以做到更大的带宽和更低的时延。每个PCIe设备(EP或Bridge)包括了Transmit(TX) 和 Receive(RX)两部分电路逻辑,这两部分可以同时运行。例如作为Device 1 可以在发送的同时,还接受 Device 2 的输入的数据。PCIe协议主要涉及三层,分别是 事务层(Transaction Layer)、数据链路层(Data Link Layer)以及 物理层(Physical Layer):
7.2 Transmit(TX) 流程
- 软件层(Software layer)或设备核心层(Device Core),PCIe标准协议并没有软件层这个名词,软件层是使用PCIe的核心设备(如上层的CPU或者底层网卡GPU等)与PCIe硬件之间的接口层。CPU需要通过PCIe 传递数据时,例如CPU需要读写Bar空间,配置空间等。则软件编写的源代码,会被转换为CPU流水线可以执行的指令,CPU发现指令读写的存储域地址空间位于PCIe总线域,则会通过内部高速总线将地址和数据等相关信息,通过软件层传递给 RC的Root bridge,Root Bridge中有PCIe的逻辑电路,负责PCIe协议的分层组装和解封装。
- 从事务层开始,对数据(Data Payload)进行每个协议层的协议头部封装。事务层封装后的数据报文,称为TLP(Transaction Layer Packet)。事务层负责将总线上传递过来的“Data Payload”,加上 "Header" 报文头和 “ECRC”校验和,就形成了TLP报文。TLP报文产生后,会根据TLP的优先级,放入对应的Virtual Channel(VC)即Transmit Buffer,然后通过事务层的VC Arbitration (冲裁器),从多个VC 通道中调度出一个TLP报文,进行发送传递到下一层。
- 数据链路层,负责对TLP进行封装,加上“Sequence”序列号和“LCRC”校验和,形成数据链路层的”Link Packet“。该Link Packet会暂存在TLP Retry Buffer中,只有从RX端收到这笔报文的回复确认ACK报文,才会从Retry Buffer中删除,如果超时没有收到ACK会进行重发。Link Packet 头部的Sequence类似TCP头部的序列号,用于RX端确认报文是否连续收到。TLP报文封装后称为 Link Packet,而数据链路层还会主动发送ACK/NAK报文,Link Packet和ACk 报文需要通过 Mux(多路选择器)的逻辑,将多路信号选择合并为一路向下一层进行发送。
- 物理层,继续对Link Packet进行封装,加上"Start" 开始符号 “End”结束符号。然后进行”Encode“编码,例如PCI 2.0 需要进行 8/10 编码,而PCIe 4.0 要进行 128/130 编码。接着再进行”Parallel to Serial“并行到串行的物理信号转换等,最后通过Lane链路发送出去。
7.3 Receive(RX) 流程
RX的流程和TX是相反的过程,如果理解了TX,则RX就很好理解了:
- 物理层,收到Lane上的物理电信号后,进行串行到并行的转换,再通过”Decode“进行解码,和编码是逆向的过程,编码将128bit编码为130bit,而解码将 130bit解为128bit。然后校验并去除数据链路层的”Start“和”End“,将剩下的 Link Packet 传递到 上一层。
- 数据链路层,首先进行“TLP Error Check”报文合法性检测,如果有问题,则电路通知TX端,进行NAK的“DLLP”报文发送。如果报文合法,继续做”De-Mux" ,根据Link Packet类型,将其分发到“DLLPs”或者“Link Packet”的处理逻辑。如果是Link Packet,则去除Sequence 和 LCRC,得到TLP,然后将TLP传送给上一层。
- 事务层,收到数据链路层的TLP后,首先根据其报文头部的优先级信息,将TLP放入对应的Virtual Channel (VC) 即 Receive Buffer 中。然后从VC中调度选择TLP packet 进行处理,对TLP 去除Header 和 ECRC后,将得到的“Data Payload”传递给设备核心层(软件层)。如下图Device A设备核心层 输入 Data,通过协议的各层封装后传递给Device B,Device B 通过各层协议解封装后,传递给 Device B 设备核心层。
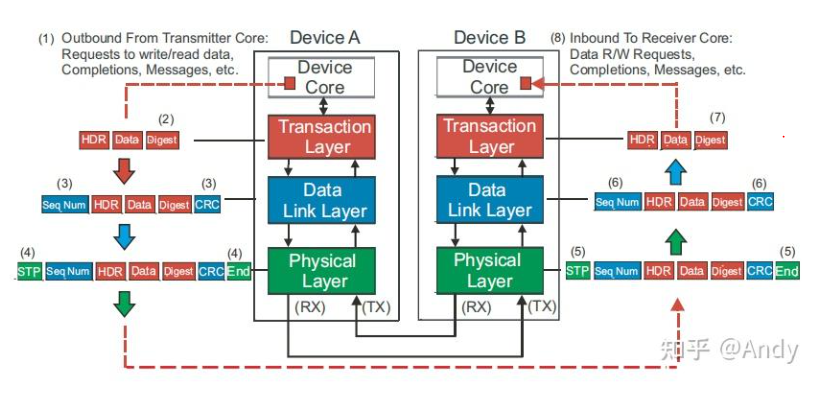
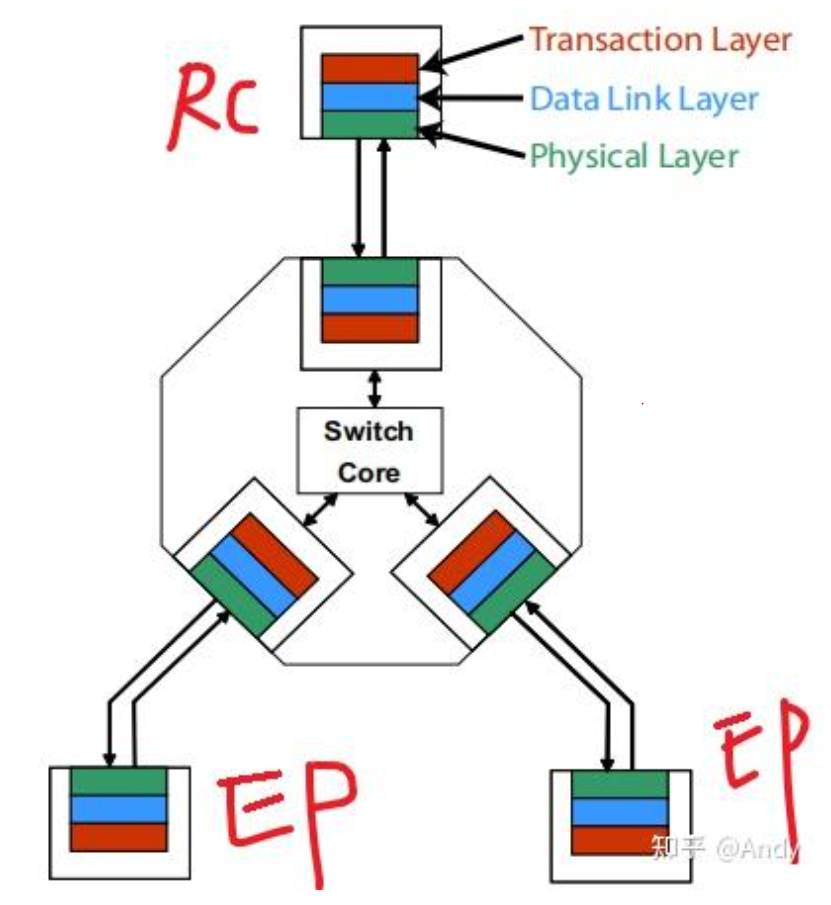
总结:PCIe协议主要涉及三层,而这三层协议需要在 RC,Switch Port(Bridge),EP 每一个设备中进行支持:
7.4 事务层TLP报文格式
TLP报文由TLP Header、Data、Digest(LCRC)三部分组成,我们主要关注的时Header的格式:
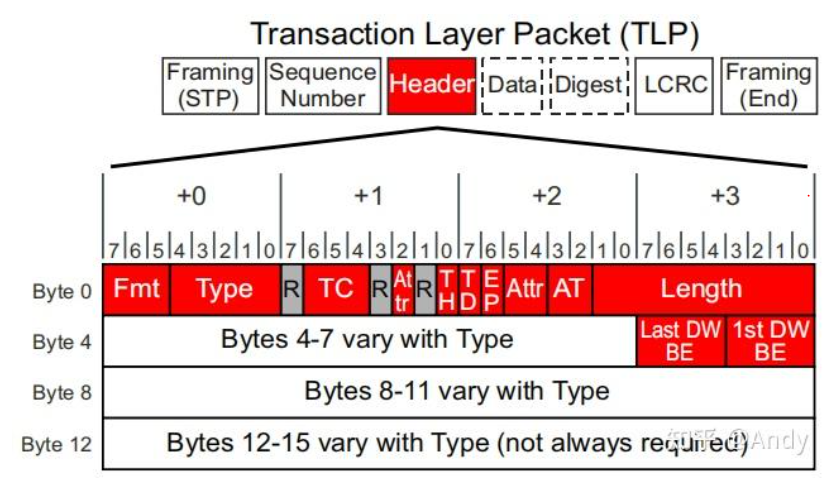
对于这个通用的Header格式,我们主要关注Fmt、Type 和 Length:
1. Fmt:一共3个bit 5~7,Fmt用于指示两种信息,一个是TLP头部的长度,另一个是读写请求类型
- 00b 3DW header, no data (该TLP 头部长度一共3个W即12字节,并且该TLP是一个读请求)
- 01b 4DW header, no data (该TLP 头部长度一共4个DW即12字节,并且该TLP是一个读请求)
- 10b 3DW header, with data (该TLP 头部长度一共3个DW即12字节,并且该TLP是一个写请求)
- 11b 4DW header, with data(该TLP 头部长度一共4个DW即12字节,并且该TLP是一个写请求)
2. Type:一共5个bit 0~4,该字段特别重要,指TLP具体类型,当前PCI标准定义的类型大概20种左右,但是对于系统程序员来说,关注下面几种就够了。从中我们可以发现一点规律,只有MRd和MWr才支持4DW的协议头,因为只有MRd和MWr的TLP Head需要填充存储域地址(所有这两个TLP是基于地址的路由,后面会介绍),而64位的地址长度需要2DW。其他类型的TLP,在TLP header中不需要填充存储器域的地址,所以3DW就够了。而且读请求全部是不带Data的,因为需要接收端通过 CplD 回传请求的Data 数据。Memory Read 和 Config Read Request 全部通过 CplD回复请求数据。
| TLP Type (TLP 类型描述) | FMT[2:0] Value (Format值) | TYPE [4:0] Value(TLP类型值) |
|---|---|---|
| Memory Read Request (MRd) | 000 = 3DW, no data(读请求) 001 = 4DW, no data(读请求) | 0 0000 |
| Memory Write Request (MWr) | 010 = 3DW, w/ data (写请求) 011 = 4DW, w/ data(写请求) | 0 0000 |
| Config Type 0 Read Request (CfgRd0) | 000 = 3DW, no data (读请求) | 0 0100 |
| Config Type 0 Write Request (CfgWr0) | 010 = 3DW, w/ data(写请求) | 0 0100 |
| Config Type 1 Read Request (CfgRd1) | 000 = 3DW, no data(读请求) | 0 0101 |
| Config Type 1 Write Request (CfgWr1) | 010 = 3DW, w/ data(写请求) | 0 0101 |
| Completion W/Data (CplD) | 010 = 3DW, w/ data(读完成有数据) | 0 1010 |
3. Length:TLP后面数据的总长度,最大支持4KB,即1024DW,单位是DW。
下面将重点介绍上面列出的各种 TLP 协议报文的类型。
7.5 事务层TLP报文类型
- MRd(Memory读请求):Memory读TLP主要用于两个方向,一个是从CPU发起指令,读取PCIe设备的Bar空间对应SRAM寄存器数据;另一个是从PCIe设备发起的,对主机内存DRAM读取数据的DMA读请求。对于64位地址的Memory读请求,Fmt为0x1,而32位Memory读请求,Fmt是0x0。Type不管是64位还是32位,全部为0x0。对于从PCIe EP发起的64位地址主机内存的读请求,送到RC的TLP Head中的64位地址,为存储器域地址空间4G以上的地址空间(这部分地址空间映射到主机的DRAM内存):
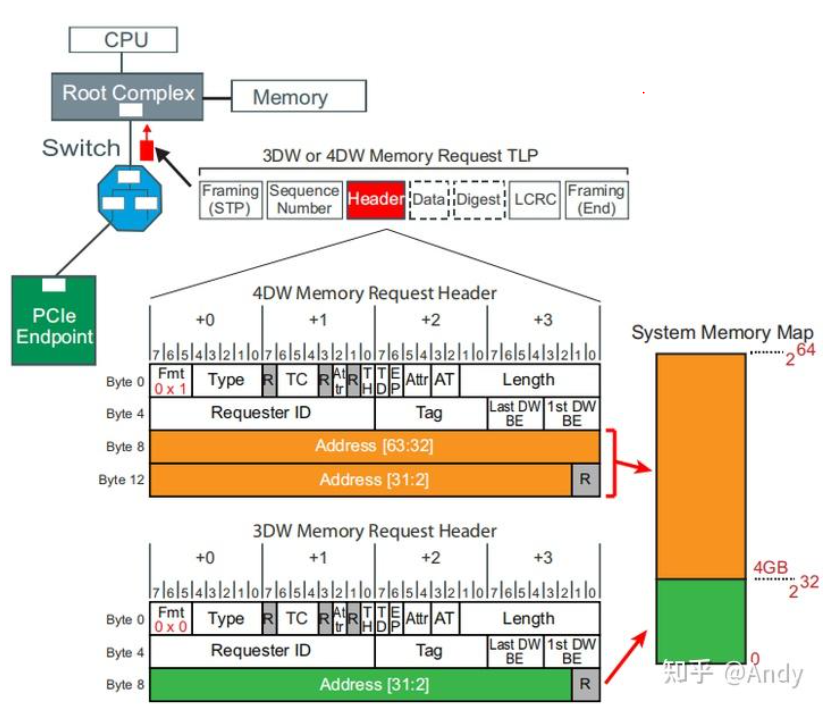
- MWr(Memory写请求):Memory写TLP主要也是用于两个访问,但是用途相对读请求会多一种。第一个是从CPU发起指令,写入数据到PCIe设备的Bar空间对应SRAM寄存器;第二个是从PCIe设备发起的,对主机内存DRAM写入数据的DMA写请求;还有一个是经常被忽略的,Memory写请求也会被用来发送MSI或MSI-X中断给CPU核心。如果对PCIe MSI-X中断感兴趣,请阅读作者的另一篇文章《PCIe MSI-X中断编程》。MWr TLP Head中的Fmt 和 Type 如何填充,请读者自己查看前面的表格。需要特别注意的是 MWr TLP 会直接带上数据传递出去,而MRd TLP 没有带数据(需要对端通过 CplD回复数据)
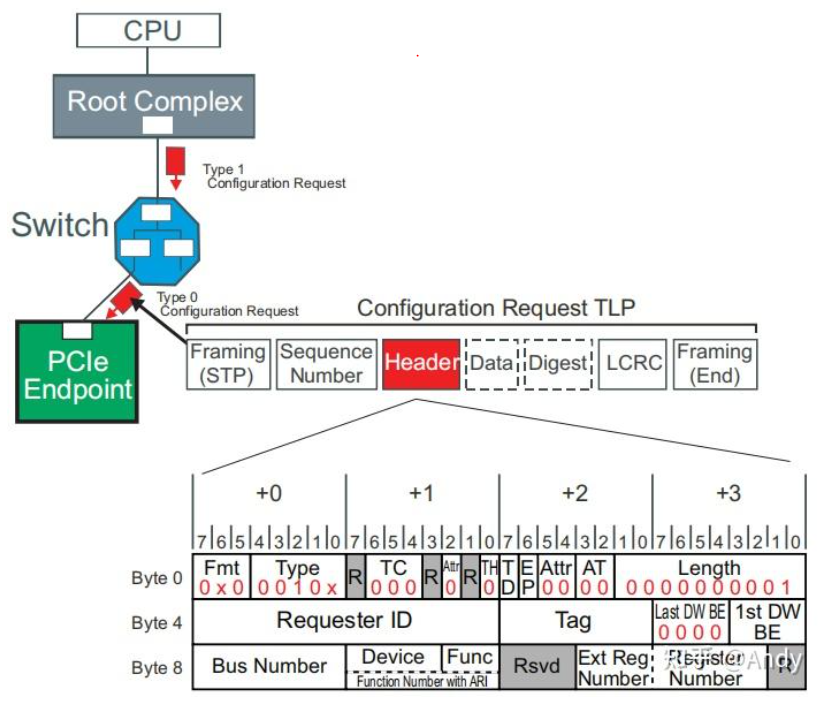
- CfgRd0/CfgRd1 & CfgWr0/CfgWr1(配置读写请求):按照PCIe 规范,对一个PCIe EP 的配置空间读写请求,回用到两种类型(Type 0 & Type 1)的配置读写请求TLP。例如对PCIe EP 的配置空间读请求, 从Root Bridge 开始生成TLP报文时,会将目的EP 的Bus Number 和 Root Bridge 的Secondary Bus Number 0 比较,如果EP就直接挂接在 Bus 0下,则产生的是CfgRd0 类型即Type 0 的TLP。如果EP的bus Number在 Root Bridge的Secondary 到 Subordinate Bus Number 之间,则会产生CfgRd1 类型即Type 1 的TLP。知道最后一级的Bridge,其发现目的EP的Bus Number 等于Bridge 的Secondary Bus Number,才会将 CfgRd1 转换为 CfgRd0 类型的TLP发送给最终的EP。配置读写TLP是由CPU RC 发出,其中比较重要字段有前面提到的Fmt 和 Type,以及 Requester ID (发起者的BDF,因为发起者是RC,我通常看到的是0,即bus/device/function为全0)和Byte 8~9 Completer ID(接受者的 BDF,如EP的 Bus/Device/Function)。
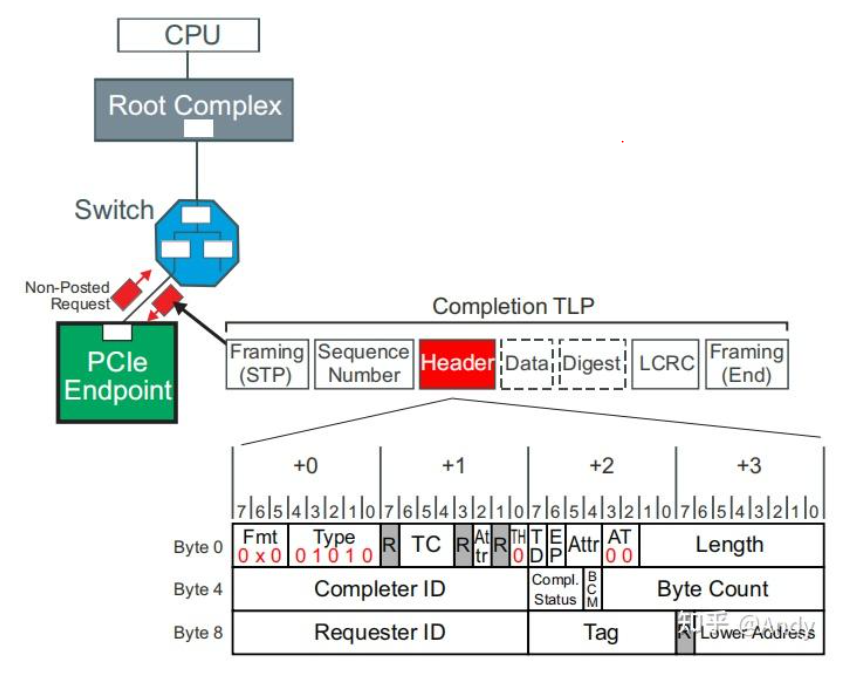
- CplD(完成数据响应):Memory Read 和 Config Read Request 全部需要通过 CplD回复请求存储器或PCIe 配置空间的数据。我们发现和前面配置读写请求不一样,Requester ID放置在Byte 8~9(表示谁发起了这次请求,配置读写是RC发起通常为0,Bar读写也是RC发起通常也是0,内存DMA读写请求是EP发起为EP的BDF),由此我们可以退则PCIe 协议固定以TLP头部的8~9字节来进行基于ID的路由选路,通过这两个字节可以找到这笔报文需要回复给谁,对于ID路由后面会介绍。
7.6 事务层TLP Routing
TLP 的路由主要有两种类型,一种是基于地址的路由,即在PCIe 总线域中,使用TLP头部的64位或32位地址进行路由,前面提到的 MRd,MWr 请求报文,就是基于地址进行路由的;另一种是基于TLP头部的 Byte 8~9 字节中的BDF进行路由,对于配置读请求和MRd读请求的回复报文CplD,是通过 Byte 8~9 的 Requester ID(请求者)进行路由,而对于CfgRd0/CfgRd1 & CfgWr0/CfgWr1 配置读写请求,则是基于Byte 8~9 的 Completer ID(接收者)进行路由。
TLP Type 不同,对应使用的Routing方法也不同,除了基于地址和ID的路由之外,还有一个是隐式路由(implicit routing),隐式路由即不基于地址也不基于ID进行路由,而是基于TLP头部的一个字段来确认这笔TLP是发送给RC或者所有的EP,隐式路由通常用于Message 报文,Message 报文是PCIe 协议用来代替 PCI的 sideband边带 信号, 转换为报文的方式来进行电源管理信号,error信号的通知,对于系统程序员来说,使用较少,所以本文就不详细介绍了。
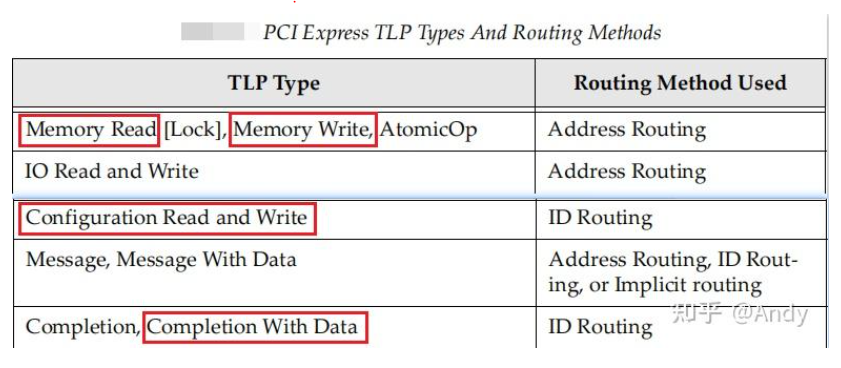
1、基于地址的路由
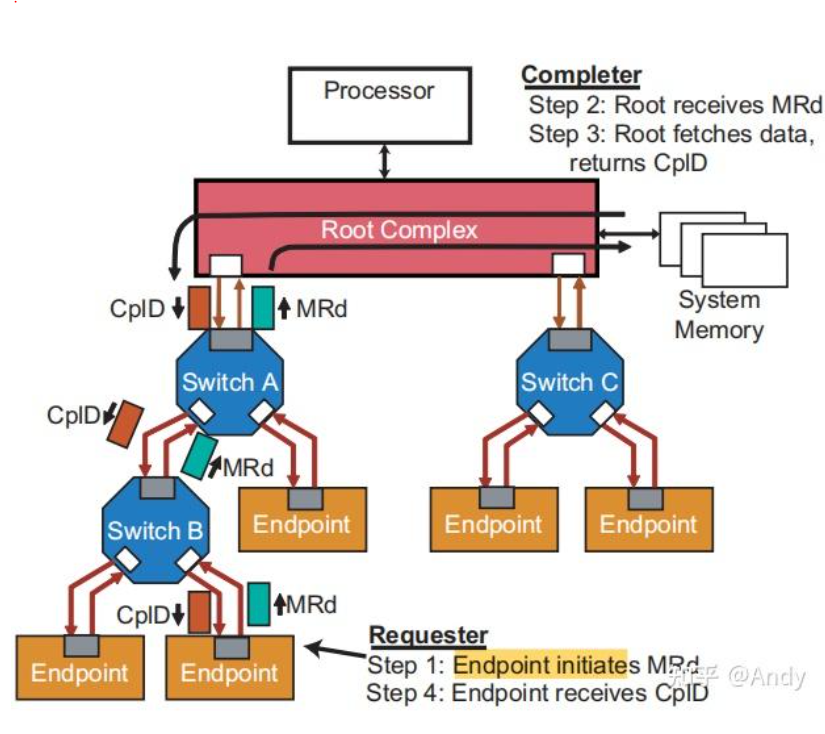
以EP发起的Bar空间写请求MWr为例,从Step 1 RC 发请求MWr 写请求开始,产生的TLP报文将通过中间的Switch A 和 Switch B,最终到达 Step 2 EP 接受到MWr 请求。
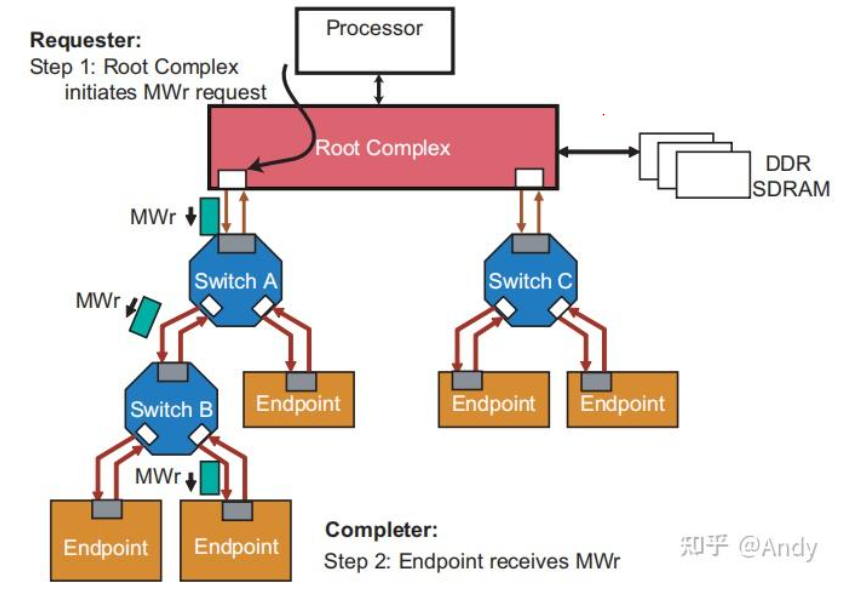
首先MWr 请求报文到达Switch 的处理流程是:
- 第一步:比对报文中的64位或32位地址,是否在P2P Bridge 的Bar 空间地址范围之内,如果在,则P2P Bridge直接消费掉该TLP报文;如果不在,则继续下一步
- 第二步:比对报文中的32位地址,是否在P2P Bridge 的IO空间地址范围之内(IO空间类似Bar空间,很少使用,所以本文没有介绍),如果在,则P2P Bridge直接消费掉该TLP报文;如果不在,则继续下一步
- 第三步:比多报文中的64位或32位地址,否在P2P Bridge 的 Memory Base + Limit 地址范围之内,如果在,则将TLP继续向下面的P2P Bridge 或 Endpoint 发送;如果不在,则丢弃
TLP通过了Switch,最终到达 EP,EP也会比对报文中的64位或32位地址,是否在EP的6个Bar 空间地址范围之内,如果在,则接受该TLP MWr,并写入数据Payload到对于地址偏移的 Bar空间中;如果不在6个Bar 空间地址范围中,则EP丢弃该TLP报文。
下面是EP发起MRd 请求读取系统内存的过程,其也是基于地址进行路由,但重点是,和Bar空间读写请求略有不同。Bar空间读写TLP中地址如果不在对应Switch和EP的地址之内就会丢弃TLP;而内存读写TLP,其中的地址为系统内存在存储器空间中的物理地址,一定不属于PCIe总线域的Bar空间地址,所以Switch在收到EP发起的MRd后,比对地址不在自己的范围之内,默认行为是将MRd 或 MWr TLP直接发送到上行的端口USP,一路通过USP发送的 RC,然后RC将这个MRd的TLP请求转换为 系统内存控制器读取信号作为输入,内存控制器读取数据后,回给RC,RC再将该Data Payload封装成 CplD TLP 回复给最终 EP(注意回复的过程采用基于ID的路由)。
2、基于ID的路由
基于ID(BDF)的路由就比较简单了,前面提到过,就是基于TLP Header 中的 Byte 8~9 的BDF进行路由选择:

例如当配置读写请求的TLP到达 Switch 的 P2P Bridge时,会通过TLP中的Byte 8~9 Bus Number和当前Bridge配置空间内的Secondary 和 Subordinate Bus Number 进行比较;如果TLP中Bus Number和Bridge 配置空间Secondary Bus 相同,则表示该TLP的目的地就在该Bridge下面的总线上;如果TLP中Bus Number在Bridge 配置空间Secondary Bus 和 Subordinate Bus 之间,则继续将该TLP向下面的 Bridge 和 EP继续转发;如果不在Secondary Bus 和 Subordinate Bus 之间,则Switch丢弃该报文。
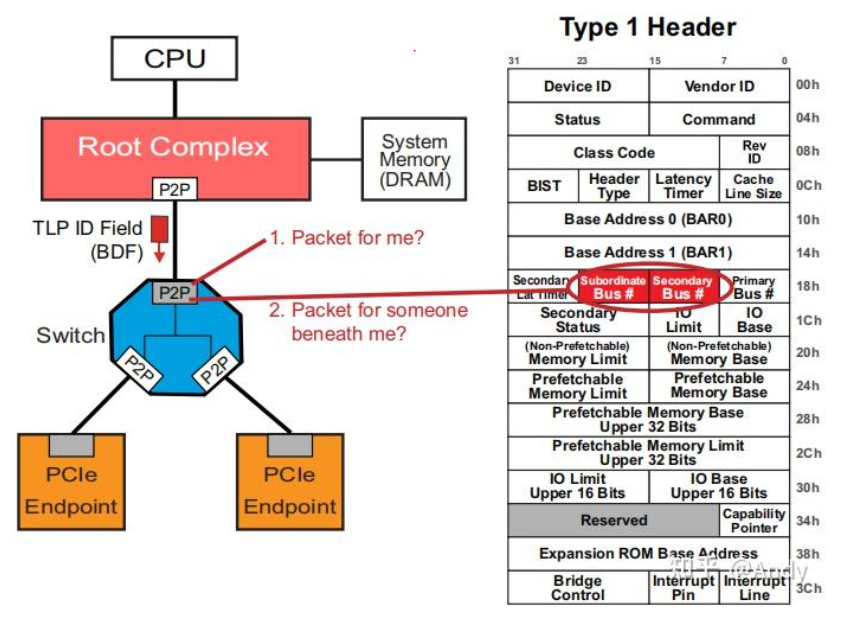
最终 EP 接受到该配置读写的TLP之间,会比较EP自己BDF和TLP报文中的是否相同,如果BDF全部相同,则接受并处理该报文的请求;否则丢弃。
7.7 数据链路层DLLP类型以及格式
在PCIe物理链路(Lane)上,传递的Packet 类型主要是DLLP和TLP。TLP和DLLP的Type(类型)对应着他们的用途。TLP在物理层封装的起始位是STP(Start of TLP),物理层封装的起始位是 SDP(Start of DLLP)。
DLLP(Data Link Layer Packet)报文类型主要分成三类,第一类是用于确认TLP传输完整性的Ack/Nak;第二类是电源通知管理;第三类是用于事务层的流量控制功能。本文只介绍第一类,如果对PM和FC感兴趣,建议阅读附录的参考文档。
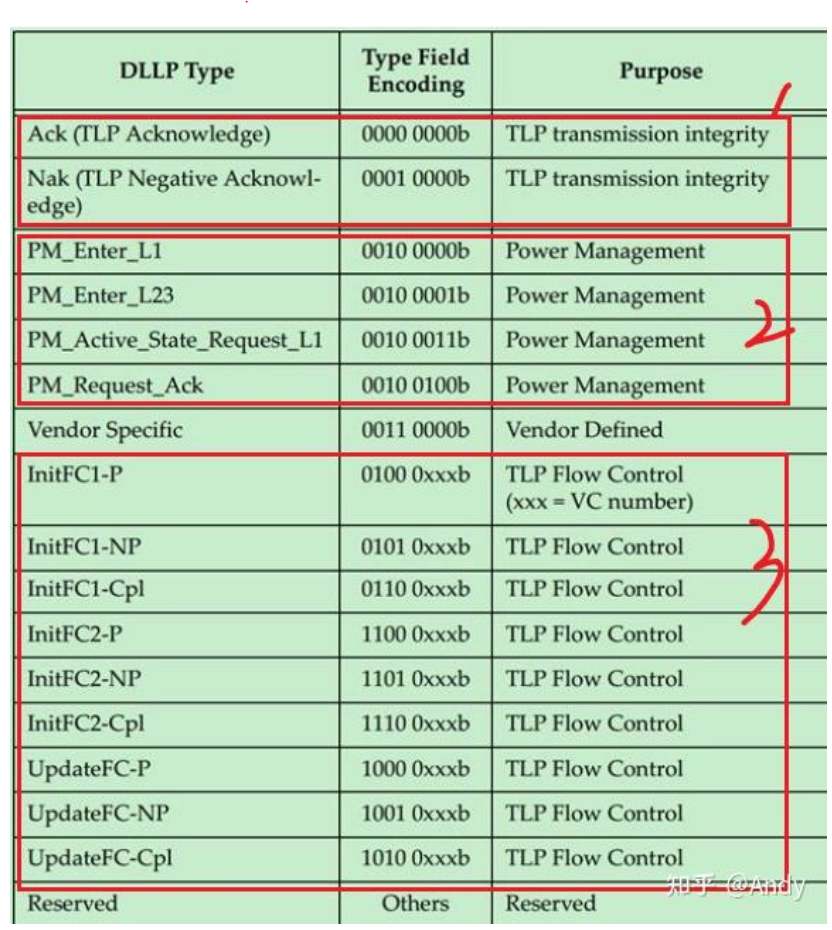
DLLP的报文产生于PCIe 设备一端的数据链路层,终结于PCIe设备另一端的数据链路层(被另一端进行接受和处理)。DLLP的总长度是6个字节,在数据链路层生成 DLLP 报文,在物理层封装和解封装SDP和END:
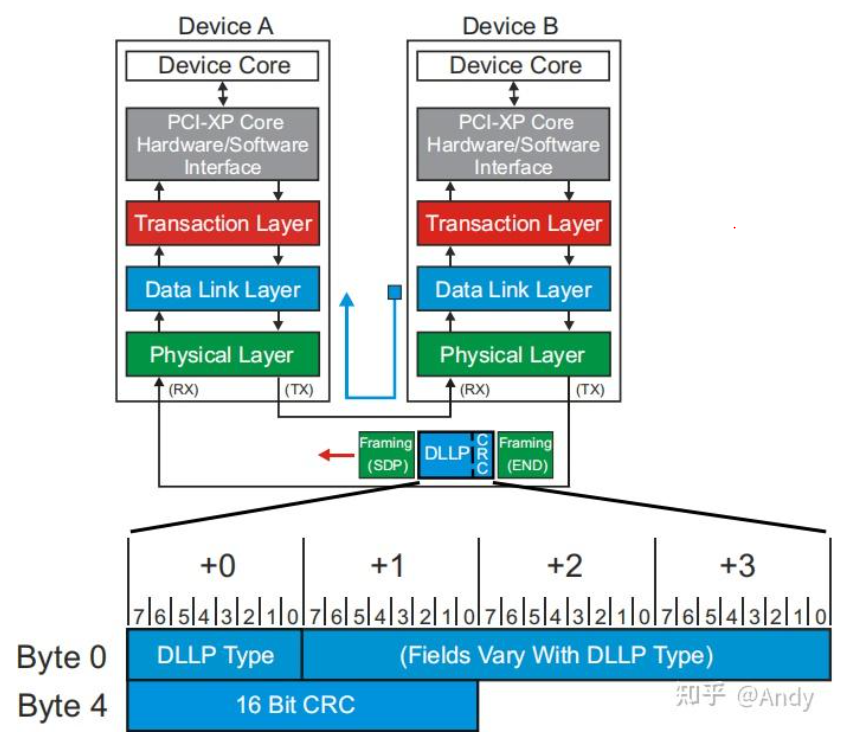
Ack 和 Nak 的DLLP 报文格式如下,第0个字节是Ack 和Nack 标识;第2个字节的低4位和第3个字节是用于TLP确认的Sequence Number;第5和6字节是CRC校验和。
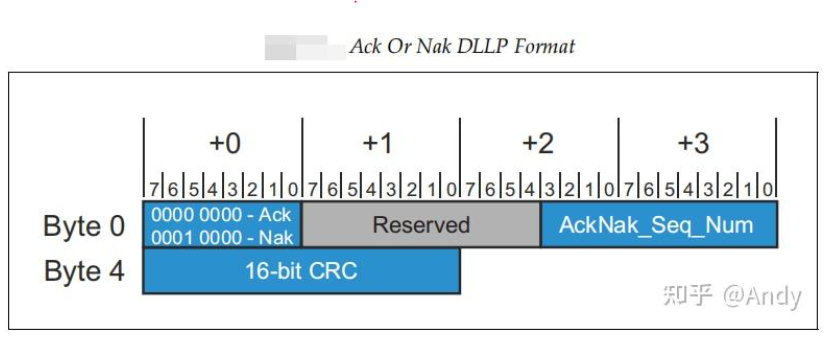
我们需要重点关注AckNak_Seq_Num字段,如果收到一个合法的TLP报文(如MWr),DLLP层的逻辑电路会基于该字段实现TLP的可靠传递,防止接受TLP丢包和乱序:
- 如果接受的TLP报文的 Sequence Number 等于 接收端的NEXT_RCV_SEQ(下一个期待接受序号的计数器),则调度发送Aak DLLP(填充当前TLP的 Seq Number到AckNak_Seq_Num字段)。
- 如果接受到重复的TLP报文(TLP Seq Number 小于 NEXT_RCV_SEQ),则接收端使用 NEXT_RCV_SEQ-1 (最后一次收到的Good TLP)发送一个 Ack 给发送端。
- 如果收到的TLP报文有错误,或者Seq Nubmer大于NEXT_RCV_SEQ,则使用 NEXT_RCV_SEQ-1,发送一个Nak DLLP给发送端。
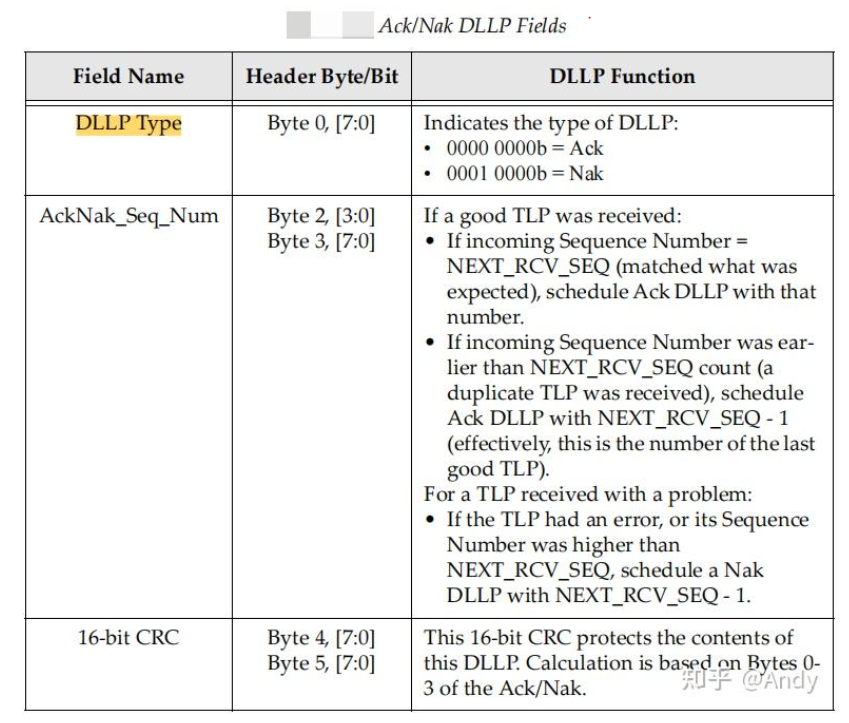
DLLP和TLP非常不同的地方是,DLLP没有路由的概念,不会跨设备进行路由。DLLP报文只用于在两个邻居设备之间传递,事务层甚至不知道DLLP 报文的存在。例如设备A是一个EP,其发送了MRd报文给RC,首先通过的是Device B(P2P Bridge),则Device B在收到Device A的MRd之后,立即回送一笔DLLP Ack报文给Device A。

- Device A 发送一笔 TLP 给 Device B
- Device B 进行 Error Check
- TLP正常则会送一笔Ack,TLP异常则发送 Nak DLLP报文给Device
7.8 TLP和DLLP抓包实战
我们遇到主机CPU无法收到PCIe EP发出的中断;EP读取主机内存的数据有误 或EP无法进行DMA读写时。则通常需要PCIe分析仪器进行抓包,从而对PCIe 的原始TLP、DLLP报文进行分析,进一步诊断是否DMA请求的地址有误,是否EP没有正确发出中断 等软硬件引起的错误状态。
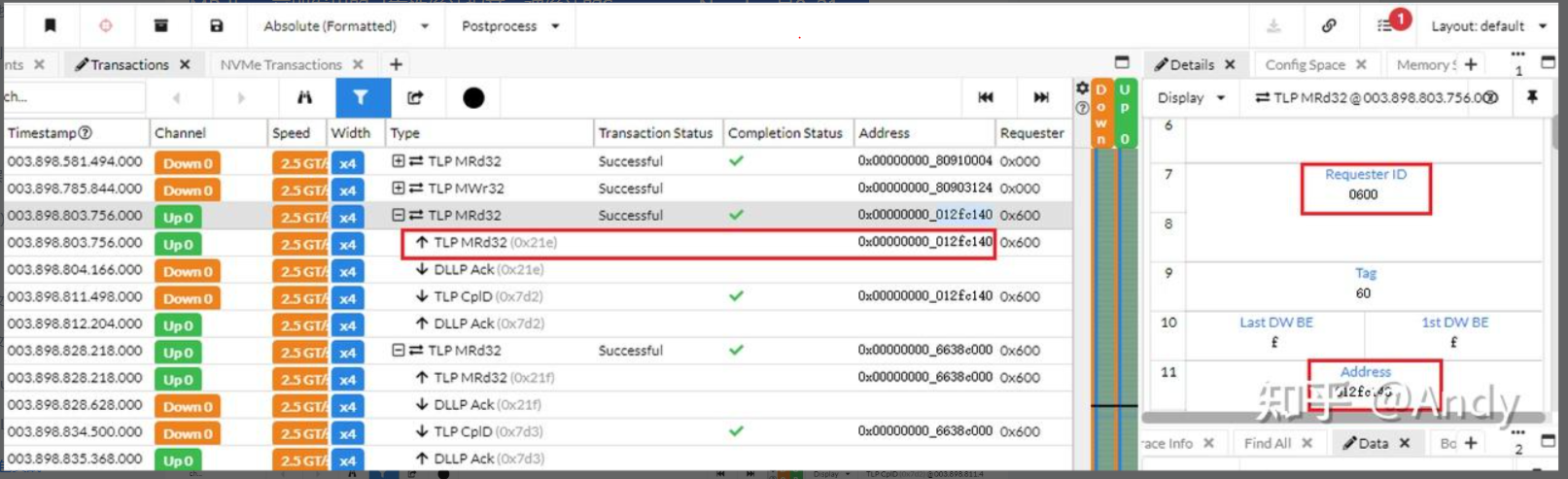
将PCIe EP设备接到PCIe分析仪器上(一般需要百万以上,只有芯片公司才会买),我们可以很轻松的抓取到PCIe的枚举过程,配置空间的读写报文,以及Memory的读写请求和回复报文。下面以TLP的MRd 为例子,讲一下如何去查看分析仪器抓取的报文。红色框中的是EP发起的TLP MRd,其Sequence Number是0x21e,方向为Up(到EP->RC或CPU方向),MRd请求的存储域地址是 0x00000000 012fc140,右面看到Requester ID(请求着的BDF)是0600即06:00.0。下一笔报文是DLLP Ack,即邻居设备(如P2P Bridge)收到TLP MRd后,立即发出的可靠性确认报文,被确认的Sequence Number是0x21e。
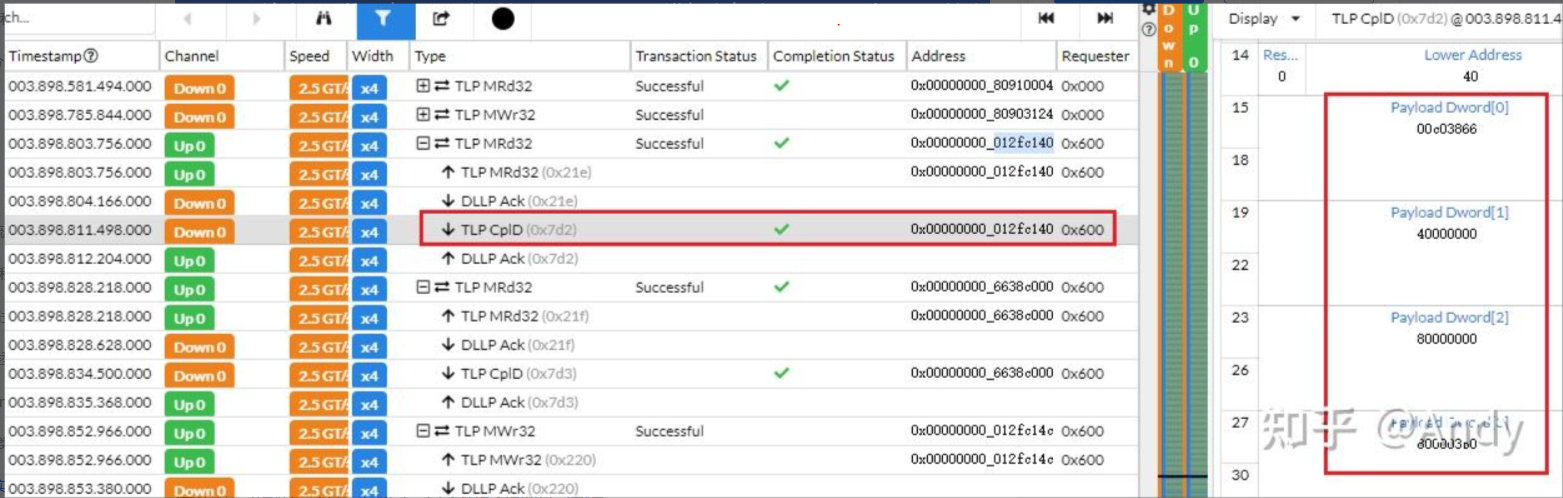
接着是对TLP MRd的数据回复报文TLP CplD,方向为Down(RC->EP),Sequence Number是0x7d2,地址还是0x00000000 012fc140,Request ID 也同样是0600即06:00.0。注意不同的地方是,CplD 基于Requester ID 进行路由到EP;而 MRd 使用地址路由到RC,然后读取DRAM的数据。
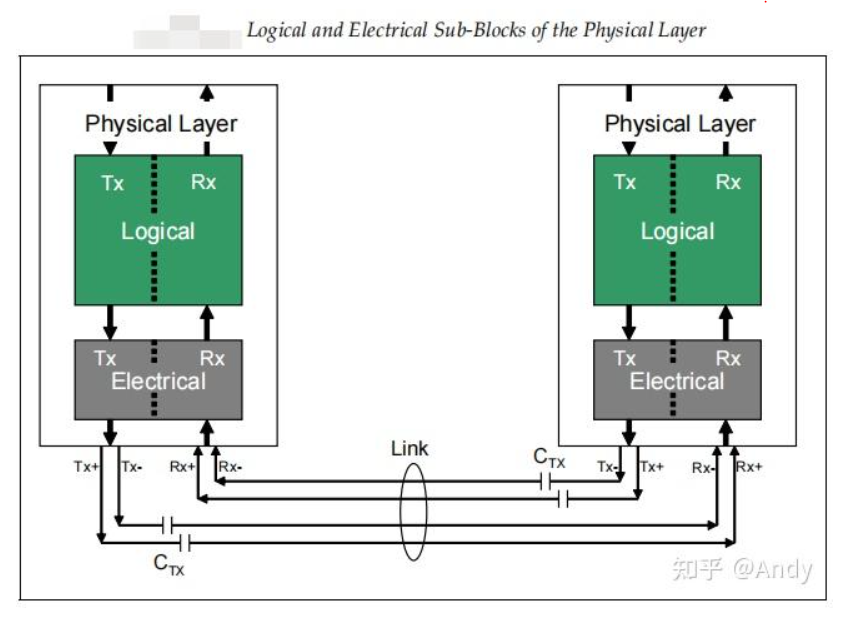
7.9 物理层结构
PCIe 的物理层由逻辑层(Logical)和电气层(Electrical)组成,这两层都包括了独立的发送和接受逻辑,支持全双工(TX和RX同时)通信。

物理层位于PCIe协议栈的最底部,作为和对端设备的物理层即数据链路层的接口和存在。物理层将本端上层数据链路层的TX报文,转换为串行的bit流,然后这些bit流按照硬件时钟信号传递到所有物理链路上(all Lanes of the Link)。这一层RX逻辑,还负责恢复来之所有物理链路的bit流程,将串行的bit流转换为并行的字符流,重新组装接受的报文,然后将接受的TLPs 以及 DLLPs 传递到数据链路层。

对于电气层,主要负责前面“PCIe物理链路”章节中介绍的差分信号的处理。如果没有印象了,建议回去复习一下。
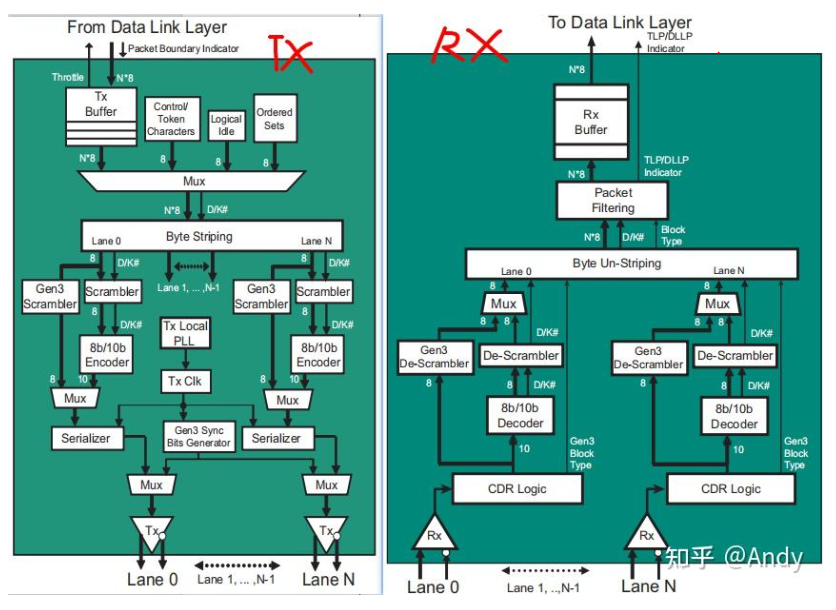
下图展示的是物理层的TX和RX逻辑层的实现,可以看到由TX Buffer 缓存来之DLLP层的数据报文,然后由 Byte Striping 对一个TX 报文(如64 Bytes)在不同的lane 上按照单字节(8bit)进行分配和插入同步信号;接着有Scrambler的逻辑,确保在PCIe物理链路上不会出现规律的信号波形, 从而将辐射能量尽量分散到不同的频率点,减小EMI辐射。 再就是8B/10B编码,保证连续的“1”或“0”不超过5位,从而保证信号 DC平衡;当高速串行流的逻辑1或逻辑0有多个位没有产生变化时,信号的转换就会因为电压位阶的关系而造成信号错误。
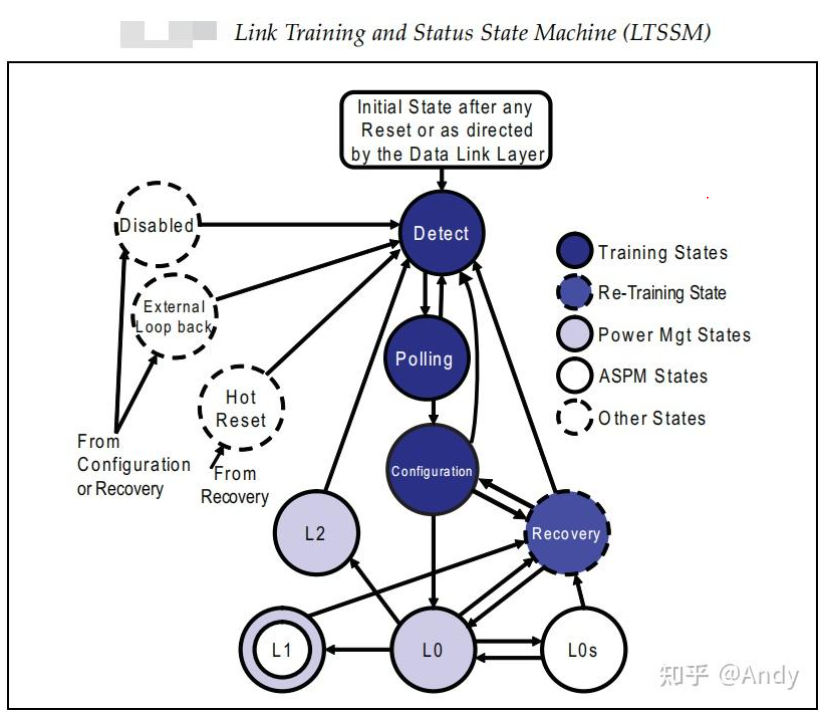
8.0 物理层LTSSM(Link Training and Status State Machine )
物理层还有一个比重要的模块是链路训练状态机,其不需要任何软件的参与。在硬件重置或启动上电后,会根据硬件的特性自动完成,其主要负责时钟信号的同步、两个PCIe设备之间链接链路带宽的协商(是X4 还是 X8)、链路速率的协商(是2.5GT,还是8GT),Lane之间的物理接线是直连还是交叉 等。
LTSSM状态机主要有下面的一些状态,例如初始的状态是 Dectect,对于L0s、L1和L2 状态,节能的级别逐渐提高。在L2时会将PCIe的12V主电源关闭,只剩下3.3V的辅助电源。我们通常需要关注的是正常工作状态L0,如果你加入了一家玩PCIe的芯片功能,请咨询做固件的小伙伴,使用什么命令可以获取到PCIe的当前的状态机。如果命令获取出来的状态是L0,则表示PCIe EP 和对端的主机P2P Bridge设备协商成功,该PCIe EP可以正常工作了。如果状态机还停留在Detect、Polling 等状态,则首先需要确认是否主机插槽有问题,如果排除了,则需要通过PCIe分析仪器抓包和硬件人员一起定位LTSSM状态机为什么没有走到正常的工作状态L0。
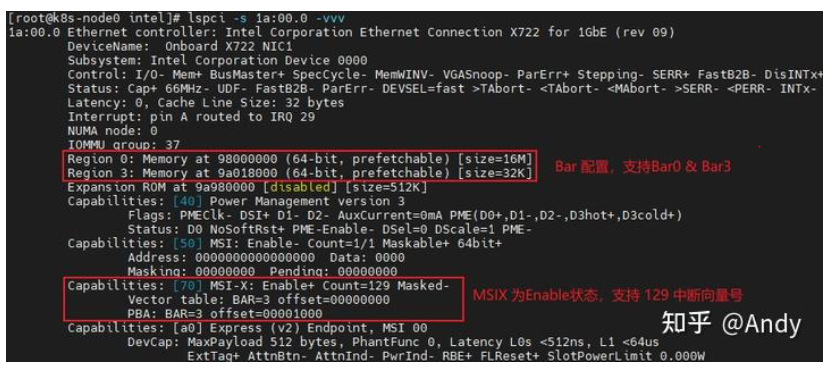
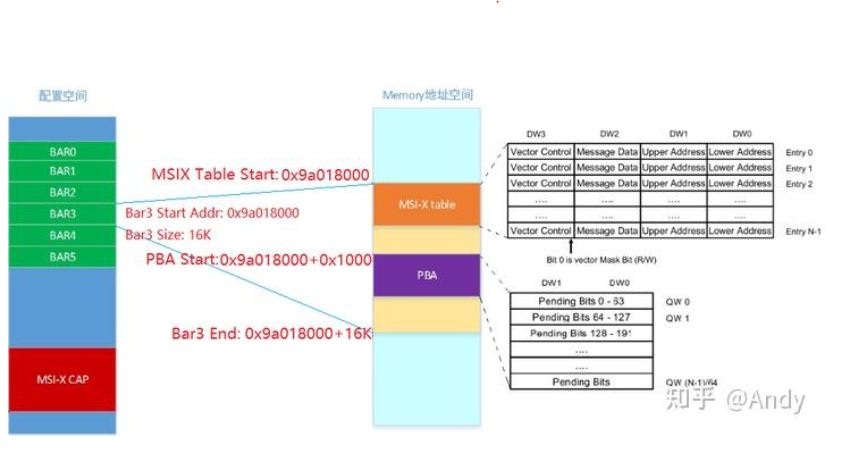
8.1 PCIe中断机制
关于PCIe中断机制,前面写过文章,但是比较重要,建议读者前往阅读《PCIe MSI-X 中断编程》,关键需要理解下面两幅图:
1、MSI-X Capability 的各个字段的意义
2、MSI-X Table,PBA table的作用,以及和Bar之间的关系
八、PCIe影响性能的因素
- 8B/10B以及128/130编码
我们提到PCIe 带宽为 5GT/s 或 8GT/s,这个速率是在PCIe Lane 上传输带宽。对于PCIe 1.0 或 2.0 采用8B/10B的编码,则发送8个bit就需要10个bit。所以有20%的带宽是浪费的,5GT/s只剩下4GT/s。但是对于PCIe3.0 就强很多,采用128/130编码,则只浪费了1.5%,8GT/s还剩下7.88G可以使用。
- Packet Overhead
这个是指报文头部信息带来的开销。例如需要传递一个TLP报文,包括了TLP层的头部(Header 3~4DW, ECRC 1DW),DLLP层的头部(Sequence 2B,LCRC 1DW),物理层的Start 和 End 各自占用一个字节。
对于MWr的TLP报文,假设TLP Head 是32位地址占用3DW,没有ECRC,TLP 的 Payload Size 是256B,则头部总长和负载比率(Payload_Ratio)为:
- 头部总长=Start + Sequence + TLP Header + LCRC + End = 1+2+12+4+1 = 20 B
- Payload_Ratio = Payload / (Payload + 20) = 256/(256 + 20) = 92.8%
如果Payload 是 4096,则负载比率可以达到99.5%。而Payload的大小在PCIe的协议规范中,最大值为4KB,最小为128B,最大Payload大小在哪里可以查看到,下一级将进行介绍。而对于MRd TLP的负载比率的计算会相对复杂一点,但是搞明白了,会受益匪浅,后面将介绍。
- Max Payload Size
PCIe EP 设备的配置空间,有多个Capabilities寄存器组,如下图有4个。分别是 Power Management Capabilities,MSI Capabilities,MSI-X Capabilities 以及 PCI Express Capabilities,各个Capabilities之间通过Nex Cap Pointer相互连接,所谓指针其实就是配置空间的偏移值。而MayPayload 大小位于PCI Express Capabilities中的 DevCap 和 DevCtrl,DevCap表示EP 硬件拥有的能力,MaxPayload 为 2048B。而DevCtl表示链路设备之间通信支持的最大值,类似于网络上的MTU(最大传输单元),如RC和EP需要通信,链路两端之间可以支持的最大MaxPayload 为 512B。所以实际工作在512B,对于Payload 大于该值的TLP,将作为非法错误报文对待。
$ sudo lspci -s 07:00.0 -vvv
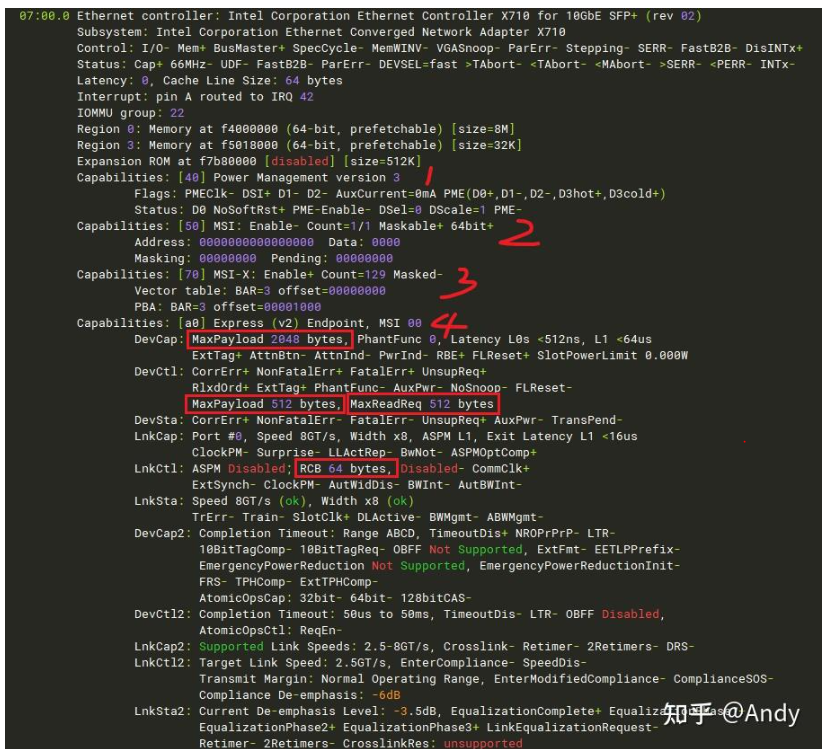
- Max Read Request Size
Max Read Request 表示MRr存储器读请求,一次可以请求的最大数据区域大小。如上图MaxReadReq也位于DevCtl,其大小为512B。MaxReadReq 最大为 MaxPayload,一定是小于等于MaxPayload。我们知道 MRd 请求报文只用于请求数据,而回复数据的长度是通过下面的RCB来控制。
- Read Completion Boundary(RCB)
RCB 表示一次CplD 最大的回复数据长度。如上图RCB也位于DevCtl,其大小为64 B。RCB 只有两个值,64 B 或者 128 B。例如RCB 是 64B,则对于EP 发起的长度为512B 的 MRd读取请求,RC需要分 8笔 CplD 报文进行回复,每笔完成报文,最大回复的数据长度不可以超过RCB 64B。
- MRd 负载比率
负载比率也可以称为有效带宽,即在PCIe 协议报文传递的过程中,有效负载数据占整个报文数据的长度。MRd计算负载比率涉及到了MaxReadReq 和 RCB 的当前配置。
假设存储器读请求MRd TLP头的大小为3DW,而且TLP层不包括ECRC。MaxReadReq 为 512B,RCB为64B。如果EP一起发起的DMA读请求的数据长度正好是MaxReadReq 512B,则RC需要使用 MaxReadReq/RCB = 8 个存储器读完成CplD报文传递所有请求的数据。则一次DMA读操作中Data Payload 所占的比例如下:
Payload_Ratio = Payload/(3 * 4 + 3 * 4 * MaxReadReq/RCB + Payload ) = 512/(12 + 12 * 8 + 512) = 512/620 = 82.6%。其中:
- 1个 MRd 请求报文的长度是 3 * 4 = 12
- 8个 CplD 报文的 TLP 头不长度是 3 * 4 , 8个头部的总长是 3 * 4 * MaxReadReq/RCB = 12 * 8 = 96.
- 8个 CplD 报文加数据的总长是 12 * 8+ 512 = 608
- 1个 MRd + 8个 Cpld 的总大小是 12 + 608 = 620
如果RCB是128,则负载比率可以达到 89.5%。而假设RCB是128,MaxReadReq是4096,一次DMA请求4096,则负载比率是91.2%。 由此可见,RCB的对对MRd 的负载比率起到决定作用。而MaxReadReq的加大,只能启动微小的提升。MaxReadReq的大小必须小于等于MaxPayload,而MaxPayload的最大值对MWr的负载比率起到了决定性作用。
- 描述符占用带宽
在SSD或网卡通信过程中,驱动需要为硬件准备描述符队列,描述符队列中的每个描述符包括硬件DMA的地址和数据长度。比如网卡的发送报文的同时,需要DMA获取描述符队列。每个描述符对应一个TX使用的DMA地址,所以没发送一笔报文,硬件就需要DAM获取一个描述符。那获取描述符必定会占用PCIe的带宽,例如对于DPDK发送 1笔 64B的网络小报文,假设描述符的长度是 4 DW(16B,Intel 100G网卡E810 就是这个长度),则有效报文负载占比是:64/(64 + 16) = 80%,即有20%的带宽是浪费在描述符上。
如果考虑到 TX 网络报文,使用的是DMA Read,对应着PCIe 的 MRd,假设 MRd的负载比率是 90%。则整个链路的有效数据带宽是 80% * 90% = 72%。如果你的硬件支持总带宽是 100Gb/s,则PCIe的能力需要达到 100/0.72 = 138.9 Gb/s。这个是在设计硬件和选择PCIe IP时必须考虑的点。
九、PCIe性能提升方法
通过调整前面提到的三个PCI Express Capabilities的参数,可以提升PCIe总线的带宽:
- 调整Max Payload Size
- 调整Max Read Request Size
- 调整RCB
前提条件是PCIe EP必须支持调整这些参数,并且PCIe 通信的两端经过的路径上的Switch节点也必须支持更大的值,否则也最终将协商为链路上设备支持的最大值中的最小的一个。
十、PCIe配置空间读写实战
在主机上,可以通过setpci 指令修改PCIe 配置空间的值。例如我们重启服务器后,为了不加载驱动,而能够直接使用工具操作(读写)PCIe 空间。则需要加PCIe配置空间中Command Register的Memory Space Enable 寄存器打开。其位于配置空间的0x04 偏移位置的第二个bit。
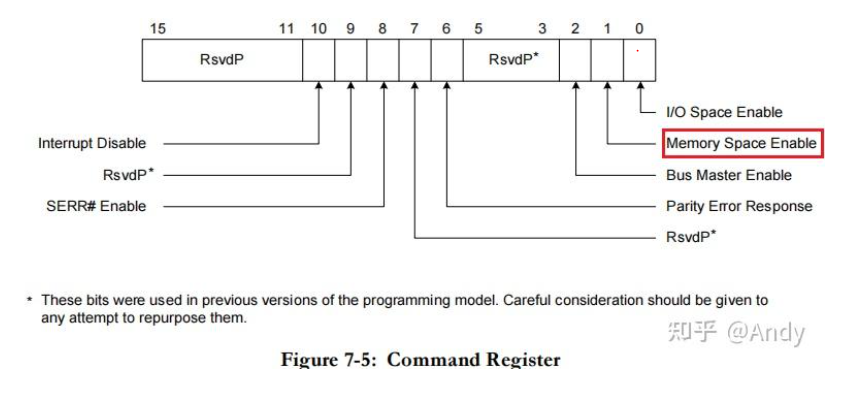
Command Register 使用lspci 展示出来的是 Control,其中Mem- 表示对Bar空间有读写权限:
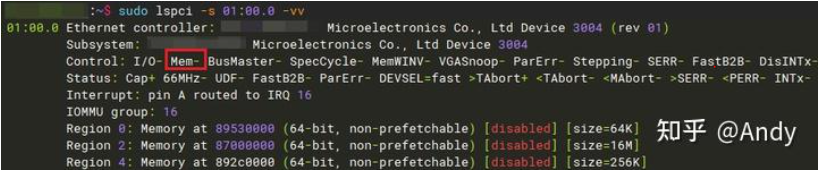
读取Command Register,并开启Bar空间读写权限(其中,'l'表示4字节,'w'表示 2字节,'b'表示 1字节):
$ sudo setpci -s 01:00.0 04.w
0000$ sudo setpci -s 01:00.0 04.w=0x0002$ sudo setpci -s 01:00.0 04.w
0002Mem+ 表示对Bar空间有读写权限,这个小技巧对于Linux等内核外设驱动开发人员非常有用,在和芯片或固件联合调试时,经常会遇到读取不了Bar空间寄存器的问题,导致驱动报出奇奇怪怪的问题。所以这时首先不要加载驱动,先将 PCIe Bar 的 Memory读写权限开启,然后通过 devmem2 工具读取Bar中映射寄存器的值,如果这时读出的值是 0xFFFF,表是Bar空间读取异常。则请芯片硬件或固件开发人员解决后,再进行驱动调试和开发。
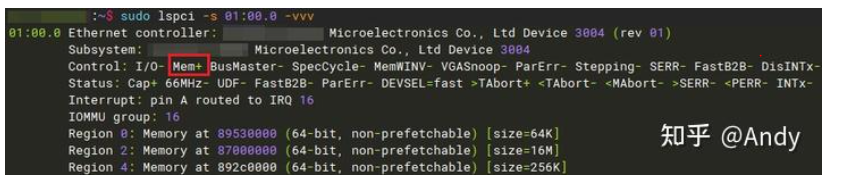
十一、PCIe Bar存储器空间操作
当Bar 空间读写权限是开启时,我们可以通过linux系统的 devmem2 进行 Bar空间的读写(其中,'w'表示 4字节,'h'表示 2字节,'b'表示1字节):
$ sudo devmem2 0x87020000 h
/dev/mem opened.
Memory mapped at address 0x7f3e90323000.
Value at address 0x87020000 (0x7f3e90323000): 0x0$ sudo devmem2 0x87020000 h 0x1122
/dev/mem opened.
Memory mapped at address 0x7f351d5cf000.
Value at address 0x87020000 (0x7f351d5cf000): 0x0
Written 0x1122; readback 0x1122$ sudo devmem2 0x87020000 h
/dev/mem opened.
Memory mapped at address 0x7f4c9d640000.
Value at address 0x87020000 (0x7f4c9d640000): 0x1122当关闭 Bar空间的读写权限后,就会发现 devmem2 工具读取bar空间的值为 0xFFFF,开启后就又可以正常读取了:
$ sudo devmem2 0x87020000 h
/dev/mem opened.
Memory mapped at address 0x7f1dc06c8000.
Value at address 0x87020000 (0x7f1dc06c8000): 0xFFFF$ sudo setpci -s 01:00.0 04.w=0x0002$ sudo devmem2 0x87020000 h
/dev/mem opened.
Memory mapped at address 0x7f85584c8000.
Value at address 0x87020000 (0x7f85584c8000): 0x1122