分布式链路跟踪
目录
链路追踪简介
基本概念
基于代理(Agent)的链路跟踪
基于 SDK 的链路跟踪
基于日志的链路跟踪
SkyWalking
Sleuth + ZipKin
链路追踪简介
分布式链路追踪是一种监控和分析分布式系统中请求流动的方法。它能够记录和分析一个请求在系统中经历的每一步操作,帮助开发者和运维人员了解系统的性能和行为。在微服务架构中,一个请求可能会跨越多个服务节点,而每个服务节点又可能依赖其他多个服务。分布式链路追踪通过生成一个唯一的跟踪ID(Trace ID),并在每个服务节点生成一个跨度(Span),记录每个操作的详细信息,从而形成完整的请求链路。
基本概念
Span 和 Trace
Trace:表示一个完整的请求链路,从请求发起到请求完成,包含了所有相关的 Spans。
Span:表示 Trace 中的一个单独的操作单元,包含操作的开始时间、结束时间、操作名称、相关的元数据(如标签、日志)等信息。一个 Trace 由多个 Spans 组成,形成一个有向无环图(DAG)。
实现方式: 【application名称+Traceid+spanid 】
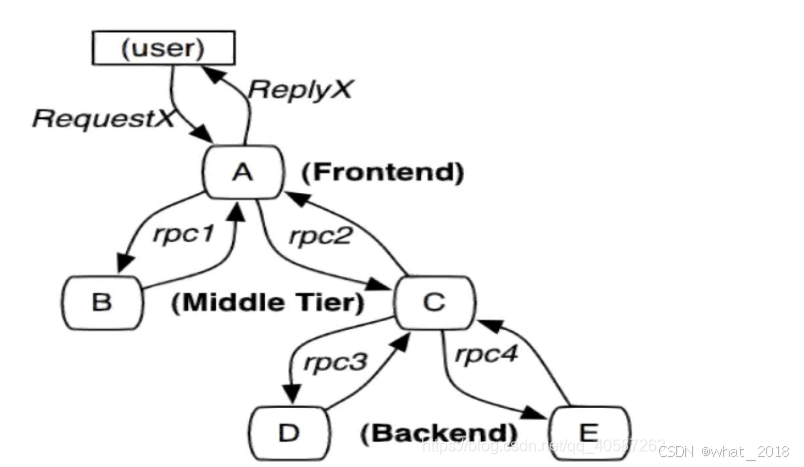
分布式链路追踪(Distributed Tracing),就是将一次分布式请求还原成调用链路,进行日志记录,性能监控并将一次分布式请求的调用情况集中展示。比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
链路跟踪在分布式系统中至关重要,它主要有以下几类,各自具有不同作用和使用方式:
基于代理(Agent)的链路跟踪
- 作用:
- 透明性高:对应用代码侵入性小,通过在应用启动时加载代理,自动收集链路数据。应用开发者无需在业务代码中大量添加跟踪相关代码,就能实现链路跟踪功能。
- 全面收集数据:能自动捕获应用与外部服务(如数据库、消息队列)的交互,全面记录请求从进入应用到离开应用的完整路径,包括网络调用、数据库查询等细节,有助于分析整个分布式系统的调用关系和性能瓶颈。
- 使用方式:
- 选择代理工具:如 SkyWalking Agent、Pinpoint Agent 等。以 SkyWalking Agent 为例,下载对应版本的 Agent 包后,在应用启动命令中添加代理参数,如
java -javaagent:/path/to/skywalking-agent.jar -Dskywalking.agent.service_name=your_service_name -jar your_application.jar。 - 配置代理参数:可在配置文件中设置代理的各种参数,如指定后端收集器地址、采样率等。例如在 SkyWalking 中,可在
agent.config文件里配置collector.backend_service指定后端服务地址。
- 选择代理工具:如 SkyWalking Agent、Pinpoint Agent 等。以 SkyWalking Agent 为例,下载对应版本的 Agent 包后,在应用启动命令中添加代理参数,如
基于 SDK 的链路跟踪
- 作用:
- 定制性强:开发者可以根据业务需求灵活定制链路跟踪逻辑。比如在特定业务场景下,对某些关键操作添加自定义的跟踪标签或注释,更精准地记录和分析业务相关的性能指标。
- 深度集成:与应用代码深度结合,能获取更详细的业务上下文信息。例如,在电商下单场景中,可将订单 ID、用户信息等业务关键数据作为跟踪信息的一部分,方便排查与业务逻辑紧密相关的问题。
- 使用方式:
- 引入 SDK:根据所选择的链路跟踪系统,在项目中引入相应的 SDK。例如,使用 Jaeger 时,对于 Java 项目,在
pom.xml中添加io.jaegertracing:jaeger - client - java依赖。 - 代码埋点:在业务代码中合适的位置添加跟踪代码。例如,在方法入口处创建跨度(Span),在方法结束时结束跨度,并在过程中记录关键信息。以下是使用 Jaeger SDK 在 Java 中简单创建跨度的示例代码:
- 引入 SDK:根据所选择的链路跟踪系统,在项目中引入相应的 SDK。例如,使用 Jaeger 时,对于 Java 项目,在
import io.jaegertracing.Configuration;
import io.jaegertracing.internal.JaegerTracer;
import io.opentracing.Span;
import io.opentracing.Tracer;
import io.opentracing.util.GlobalTracer;public class ExampleService {private static final Tracer tracer;static {Configuration.SamplerConfiguration samplerConfig = Configuration.SamplerConfiguration.fromEnv().withType("const").withParam(1);Configuration.ReporterConfiguration reporterConfig = Configuration.ReporterConfiguration.fromEnv().withLogSpans(true);Configuration config = new Configuration("example - service").withSampler(samplerConfig).withReporter(reporterConfig);tracer = config.getTracer();GlobalTracer.register(tracer);}public void doBusinessLogic() {Span span = tracer.buildSpan("doBusinessLogic").start();try {// 业务逻辑代码} finally {span.finish();}}
}
基于日志的链路跟踪
- 作用:
- 兼容性好:几乎适用于所有类型的应用,无论应用采用何种技术栈、框架,只要能记录日志,就可实现链路跟踪。这对于一些老旧系统或难以引入其他链路跟踪工具的场景非常适用。
- 辅助排查:通过在日志中添加特定的跟踪标识(如 Trace ID、Span ID),当系统出现问题时,可以根据这些标识从大量日志中快速定位相关联的日志记录,分析问题发生的过程。
- 使用方式:
- 添加跟踪标识到日志:在应用代码中,在记录日志的地方添加 Trace ID 和 Span ID 等跟踪标识。例如,在使用 Logback 作为日志框架的 Java 应用中,可通过 MDC(Mapped Diagnostic Context)来实现。首先在请求入口处生成 Trace ID 并放入 MDC,如下:
import org.slf4j.MDC;
import java.util.UUID;public class RequestInterceptor {public void intercept() {String traceId = UUID.randomUUID().SkyWalking
- 简介:SkyWalking 是一个开源的应用性能监控(APM)系统,专为微服务、云原生架构和基于容器(Docker、Kubernetes)的架构而设计。它提供了分布式链路跟踪、性能指标分析、应用拓扑图展示等功能。
- 特点:
- 低侵入性:通过 Java Agent 方式,对应用代码的侵入性极小,只需要在启动命令中添加相关参数即可启用链路跟踪,无需在业务代码中大量添加跟踪代码。
- 多语言支持:不仅支持 Java,还支持 C++、.NET、Node.js、Python 等多种语言,适用于异构的分布式系统。
- 丰富的可视化界面:其自带的 Web UI 可以直观地展示服务拓扑、链路详情、性能指标等信息,方便运维和开发人员进行问题排查和性能优化。
- 使用步骤:
- 安装 SkyWalking:从 SkyWalking 官方GitHub Releases下载安装包,解压后启动后端和前端。启动后端可在
bin目录下执行startup.sh(Windows 下为startup.bat),前端默认端口为 8080,可通过浏览器访问http://localhost:8080查看监控数据。 - 集成到应用:对于 Java 应用,在
pom.xml中添加依赖:
- 安装 SkyWalking:从 SkyWalking 官方GitHub Releases下载安装包,解压后启动后端和前端。启动后端可在
<dependency><groupId>org.apache.skywalking</groupId><artifactId>apm - agent - core</artifactId><version>[具体版本号]</version>
</dependency>
<dependency><groupId>org.apache.skywalking</groupId><artifactId>apm - spring - boot - starter</artifactId><version>[具体版本号]</version>
</dependency>
然后在application.properties中配置 SkyWalking 相关参数,如:
skywalking.agent.service_name=your - service - name
skywalking.collector.backend_service=localhost:11800
Sleuth + ZipKin
sleuth : 链路追踪器
zipkin:链路分析器(可视化)
- 简介:
- Spring Cloud Sleuth:它是 Spring Cloud 体系中用于分布式链路跟踪的工具包,为 Spring Boot 应用提供了自动配置的分布式跟踪支持。它会自动为应用生成 Trace ID 和 Span ID 等跟踪信息,并将这些信息注入到 HTTP 请求头中,实现跨服务的链路跟踪。
- ZipKin:是一个分布式跟踪系统,它接收、存储和查询链路数据。它可以与 Sleuth 配合使用,Sleuth 负责收集链路数据并发送给 ZipKin,ZipKin 提供可视化界面来展示链路跟踪信息。
- 特点:
- 与 Spring 生态集成好:Sleuth 与 Spring Boot、Spring Cloud 紧密集成,对于使用 Spring 技术栈构建的微服务系统,使用起来非常方便,几乎可以做到开箱即用。
- 数据收集和存储灵活:ZipKin 支持多种存储后端,如内存、MySQL、Elasticsearch 等,可以根据实际需求选择合适的存储方式来存储链路数据。
- 使用步骤:
- 添加依赖:在 Spring Boot 项目的
pom.xml中添加 Sleuth 和 ZipKin 相关依赖:
- 添加依赖:在 Spring Boot 项目的
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring - cloud - starter - sleuth</artifactId>
</dependency>
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring - cloud - starter - zipkin</artifactId>
</dependency>
- 配置 ZipKin Server:可以通过 Docker 快速启动一个 ZipKin Server 实例:
docker run -d -p 9411:9411 openzipkin/zipkin
- 配置应用:在
application.properties中配置 ZipKin 地址:
spring.zipkin.base - url=http://localhost:9411
spring.sleuth.sampler.probability=1.0
这里spring.sleuth.sampler.probability设置为 1.0 表示对所有请求进行采样跟踪,实际应用中可根据需要调整采样率。
- 对比
- 易用性:
- SkyWalking:对于 Java 应用,通过简单配置 Java Agent 即可启用,对业务代码侵入小,上手相对容易。在异构系统中,多语言支持使其能统一管理不同语言编写的服务的链路跟踪。
- 易用性:
- Sleuth + ZipKin:在 Spring 生态系统内,借助 Spring Boot 的自动配置特性,整合较为便捷,开发人员可以快速上手。然而,对于非 Spring 技术栈的应用,集成难度较大,需要额外的工作来实现跨语言的链路跟踪。
- 性能影响:
- SkyWalking:通过 Java Agent 方式实现链路数据收集,在设计上注重对应用性能的低影响。其采用字节码增强技术,在运行时对类进行增强以收集数据,并且支持灵活的采样策略,可在保证获取足够链路信息的同时,尽量减少对应用性能的损耗。
- Sleuth + ZipKin:Sleuth 在应用内收集链路数据,其对性能的影响取决于采样率设置以及应用内跟踪逻辑的复杂程度。如果采样率过高或跟踪逻辑过于复杂,可能会对应用性能产生一定影响。此外,数据发送到 ZipKin Server 的网络开销也需要考虑。
- 功能特性:
- SkyWalking:除了基本的链路跟踪功能外,还提供了丰富的性能指标分析功能,如服务的响应时间、吞吐量等。其拓扑图展示功能能直观呈现分布式系统中各个服务之间的依赖关系,并且支持告警功能,可根据设定的阈值对性能指标进行实时监控和告警。
- Sleuth + ZipKin:主要聚焦于链路跟踪和可视化展示,通过 ZipKin 的界面可以清晰查看请求的调用链路、每个 Span 的耗时等信息。虽然也能获取一些基本的性能指标,但在指标分析的丰富度和深度上,相较于 SkyWalking 略显不足。同时,ZipKin 本身的告警功能相对较弱,通常需要借助外部工具实现复杂的告警策略。
- 数据存储与扩展性:
- SkyWalking:支持多种存储方式,包括 H2(默认,适合测试环境)、MySQL、Elasticsearch 等。在扩展性方面,通过集群部署方式可以应对大规模分布式系统的链路数据存储和处理需求,能够水平扩展以处理高并发的链路数据收集和查询请求。
- Sleuth + ZipKin:ZipKin 支持内存、MySQL、Elasticsearch 等存储后端。在扩展性方面,虽然也可以通过集群部署来提升性能和存储能力,但在面对超大规模分布式系统时,其架构可能需要更精细的优化和调整,以确保数据的高效存储和查询。例如,在高并发场景下,Elasticsearch 作为存储后端时,需要合理配置索引策略和集群参数。
参考:微服务—链路追踪(Sleuth+Zipkin)_sleuth zipkin-CSDN博客
原来10张图就可以搞懂分布式链路追踪系统原理-阿里云开发者社区